 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Models Localize Linguistic Knowledge in the Same Place: A Layer-wise Probing on BERToids' Representations
Paper and Code
Sep 15, 2021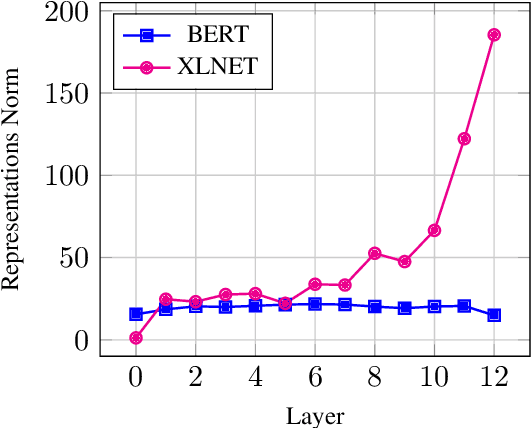

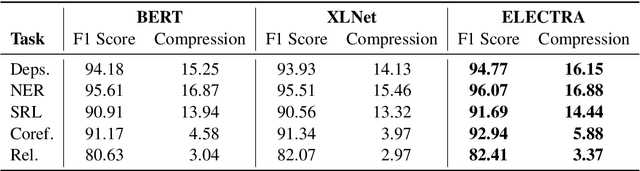
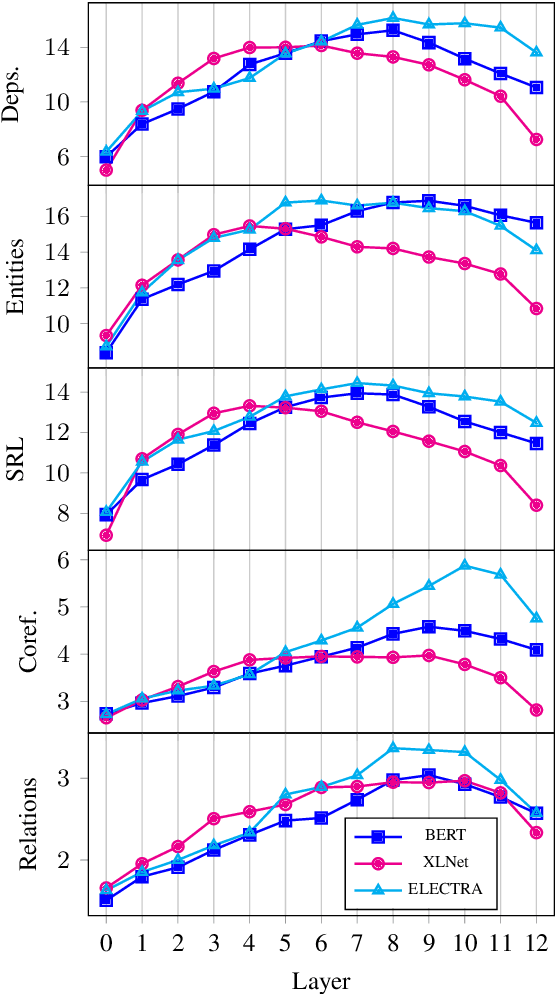
Most of the recent works on probing representations have focused on BERT, with the presumption that the findings might be similar to the other models. In this work, we extend the probing studies to two other models in the family, namely ELECTRA and XLNet, showing that variations in the pre-training objectives or architectural choices can result in different behaviors in encoding linguistic information in the representations. Most notably, we observe that ELECTRA tends to encode linguistic knowledge in the deeper layers, whereas XLNet instead concentrates that in the earlier layers. Also, the former model undergoes a slight change during fine-tuning, whereas the latter experiences significant adjustments. Moreover, we show that drawing conclusions based on the weight mixing evaluation strategy -- which is widely used in the context of layer-wise probing -- can be misleading given the norm disparity of the representations across different layers. Instead, we adopt an alternative information-theoretic probing with minimum description length, which has recently been proven to provide more reliable and informative results.