 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Learning in Speech Language Models: Analyzing the Role of Acoustic Features, Linguistic Structure, and Induction Heads
Apr 07, 2026In-Context Learning (ICL) has been extensively studied in text-only Language Models, but remains largely unexplored in the speech domain. Here, we investigate how linguistic and acoustic features affect ICL in Speech Language Models. We focus on the Text-to-Speech (TTS) task, which allows us to analyze ICL from two angles: (1) how accurately the model infers the task from the demonstrations (i.e., generating the correct spoken content), and (2) to what extent the model mimics the acoustic characteristics of the demonstration speech in its output. We find that speaking rate strongly affects ICL performance and is also mimicked in the output, whereas pitch range and intensity have little impact on performance and are not consistently reproduced. Finally, we investigate the role of induction heads in speech-based ICL and show that these heads play a causal role: ablating the top-k induction heads completely removes the model's ICL ability, mirroring findings from text-based ICL.
Tracking the emergence of linguistic structure in self-supervised models learning from speech
Apr 02, 2026Self-supervised speech models learn effective representations of spoken language, which have been shown to reflect various aspects of linguistic structure. But when does such structure emerge in model training? We study the encoding of a wide range of linguistic structures, across layers and intermediate checkpoints of six Wav2Vec2 and HuBERT models trained on spoken Dutch. We find that different levels of linguistic structure show notably distinct layerwise patterns as well as learning trajectories, which can partially be explained by differences in their degree of abstraction from the acoustic signal and the timescale at which information from the input is integrated. Moreover, we find that the level at which pre-training objectives are defined strongly affects both the layerwise organization and the learning trajectories of linguistic structures, with greater parallelism induced by higher-order prediction tasks (i.e. iteratively refined pseudo-labels).
Gender Disambiguation in Machine Translation: Diagnostic Evaluation in Decoder-Only Architectures
Mar 18, 2026While Large Language Models achieve state-of-the-art results across a wide range of NLP tasks, they remain prone to systematic biases. Among these, gender bias is particularly salient in MT, due to systematic differences across languages in whether and how gender is marked. As a result, translation often requires disambiguating implicit source signals into explicit gender-marked forms. In this context, standard benchmarks may capture broad disparities but fail to reflect the full complexity of gender bias in modern MT. In this paper, we extend recent frameworks on bias evaluation by: (i) introducing a novel measure coined "Prior Bias", capturing a model's default gender assumptions, and (ii) applying the framework to decoder-only MT models. Our results show that, despite their scale and state-of-the-art status, decoder-only models do not generally outperform encoder-decoder architectures on gender-specific metrics; however, post-training (e.g., instruction tuning) not only improves contextual awareness but also reduces the masculine Prior Bias.
On the reliability of feature attribution methods for speech classification
May 22, 2025As the capabilities of large-scale pre-trained models evolve, understanding the determinants of their outputs becomes more important. Feature attribution aims to reveal which parts of the input elements contribute the most to model outputs. In speech processing, the unique characteristics of the input signal make the application of feature attribution methods challenging. We study how factors such as input type and aggregation and perturbation timespan impact the reliability of standard feature attribution methods, and how these factors interact with characteristics of each classification task. We find that standard approaches to feature attribution are generally unreliable when applied to the speech domain, with the exception of word-aligned perturbation methods when applied to word-based classification tasks.
How Language Models Prioritize Contextual Grammatical Cues?
Oct 04, 2024Transformer-based language models have shown an excellent ability to effectively capture and utilize contextual information. Although various analysis techniques have been used to quantify and trace the contribution of single contextual cues to a target task such as subject-verb agreement or coreference resolution, scenarios in which multiple relevant cues are available in the context remain underexplored. In this paper, we investigate how language models handle gender agreement when multiple gender cue words are present, each capable of independently disambiguating a target gender pronoun. We analyze two widely used Transformer-based models: BERT, an encoder-based, and GPT-2, a decoder-based model. Our analysis employs two complementary approaches: context mixing analysis, which tracks information flow within the model, and a variant of activation patching, which measures the impact of cues on the model's prediction. We find that BERT tends to prioritize the first cue in the context to form both the target word representations and the model's prediction, while GPT-2 relies more on the final cue. Our findings reveal striking differences in how encoder-based and decoder-based models prioritize and use contextual information for their predictions.
Disentangling Textual and Acoustic Features of Neural Speech Representations
Oct 03, 2024



Neural speech models build deeply entangled internal representations, which capture a variety of features (e.g., fundamental frequency, loudness, syntactic category, or semantic content of a word) in a distributed encoding. This complexity makes it difficult to track the extent to which such representations rely on textual and acoustic information, or to suppress the encoding of acoustic features that may pose privacy risks (e.g., gender or speaker identity) in critical, real-world applications. In this paper, we build upon the Information Bottleneck principle to propose a disentanglement framework that separates complex speech representations into two distinct components: one encoding content (i.e., what can be transcribed as text) and the other encoding acoustic features relevant to a given downstream task. We apply and evaluate our framework to emotion recognition and speaker identification downstream tasks, quantifying the contribution of textual and acoustic features at each model layer. Additionally, we explore the application of our disentanglement framework as an attribution method to identify the most salient speech frame representations from both the textual and acoustic perspectives.
Homophone Disambiguation Reveals Patterns of Context Mixing in Speech Transformers
Oct 15, 2023



Transformers have become a key architecture in speech processing, but our understanding of how they build up representations of acoustic and linguistic structure is limited. In this study, we address this gap by investigating how measures of 'context-mixing' developed for text models can be adapted and applied to models of spoken language. We identify a linguistic phenomenon that is ideal for such a case study: homophony in French (e.g. livre vs livres), where a speech recognition model has to attend to syntactic cues such as determiners and pronouns in order to disambiguate spoken words with identical pronunciations and transcribe them while respecting grammatical agreement. We perform a series of controlled experiments and probing analyses on Transformer-based speech models. Our findings reveal that representations in encoder-only models effectively incorporate these cues to identify the correct transcription, whereas encoders in encoder-decoder models mainly relegate the task of capturing contextual dependencies to decoder modules.
DecoderLens: Layerwise Interpretation of Encoder-Decoder Transformers
Oct 05, 2023



In recent years, many interpretability methods have been proposed to help interpret the internal states of Transformer-models, at different levels of precision and complexity. Here, to analyze encoder-decoder Transformers, we propose a simple, new method: DecoderLens. Inspired by the LogitLens (for decoder-only Transformers), this method involves allowing the decoder to cross-attend representations of intermediate encoder layers instead of using the final encoder output, as is normally done in encoder-decoder models. The method thus maps previously uninterpretable vector representations to human-interpretable sequences of words or symbols. We report results from the DecoderLens applied to models trained on question answering, logical reasoning, speech recognition and machine translation. The DecoderLens reveals several specific subtasks that are solved at low or intermediate layers, shedding new light on the information flow inside the encoder component of this important class of models.
Quantifying Context Mixing in Transformers
Feb 08, 2023
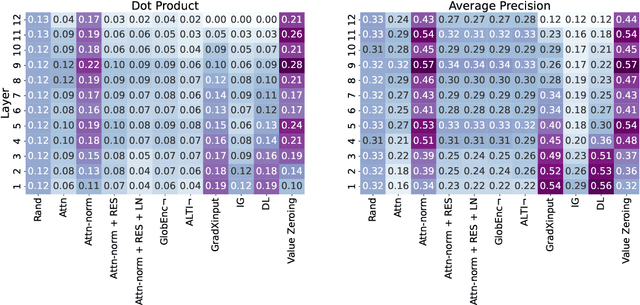
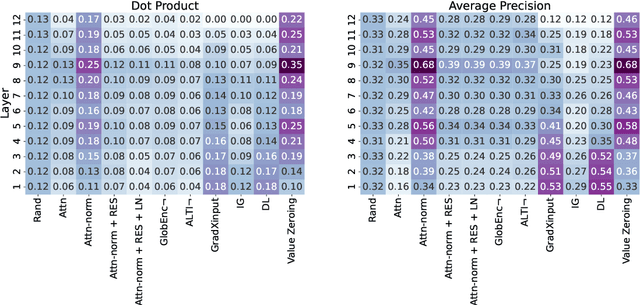

Self-attention weights and their transformed variants have been the main source of information for analyzing token-to-token interactions in Transformer-based models. But despite their ease of interpretation, these weights are not faithful to the models' decisions as they are only one part of an encoder, and other components in the encoder layer can have considerable impact on information mixing in the output representations. In this work, by expanding the scope of analysis to the whole encoder block, we propose Value Zeroing, a novel context mixing score customized for Transformers that provides us with a deeper understanding of how information is mixed at each encoder layer. We demonstrate the superiority of our context mixing score over other analysis methods through a series of complementary evaluations with different viewpoints based on linguistically informed rationales, probing, and faithfulness analysis.
AdapLeR: Speeding up Inference by Adaptive Length Reduction
Mar 16, 2022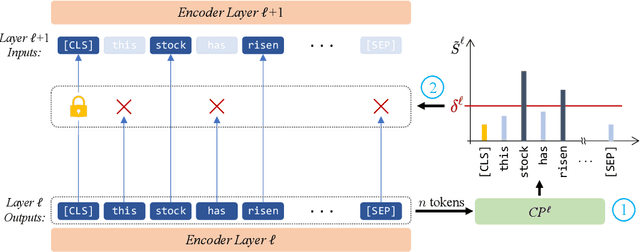
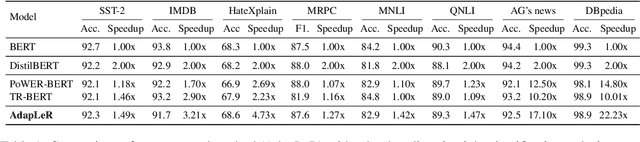
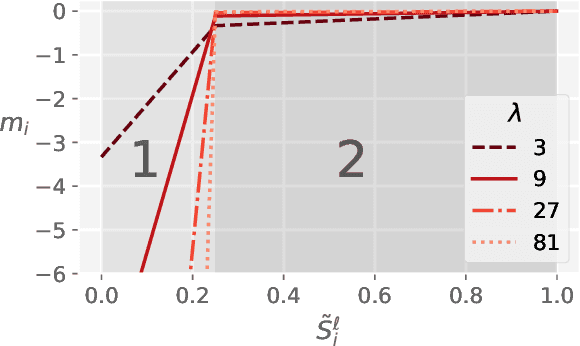
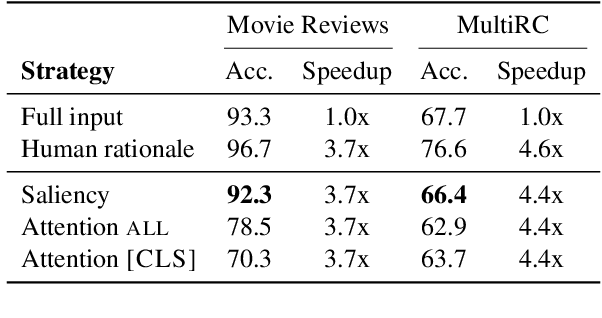
Pre-trained language models have shown stellar performance in various downstream tasks. But, this usually comes at the cost of high latency and computation, hindering their usage in resource-limited settings. In this work, we propose a novel approach for reducing the computational cost of BERT with minimal loss in downstream performance. Our method dynamically eliminates less contributing tokens through layers, resulting in shorter lengths and consequently lower computational cost. To determine the importance of each token representation, we train a Contribution Predictor for each layer using a gradient-based saliency method. Our experiments on several diverse classification tasks show speedups up to 22x during inference time without much sacrifice in performance. We also validate the quality of the selected tokens in our method using human annotations in the ERASER benchmark. In comparison to other widely used strategies for selecting important tokens, such as saliency and attention, our proposed method has a significantly lower false positive rate in generating rationales. Our code is freely available at https://github.com/amodaresi/AdapLeR .