 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDK-Root: A Joint Data-and-Knowledge-Driven Framework for Root Cause Analysis of QoE Degradations in Mobile Networks
Nov 13, 2025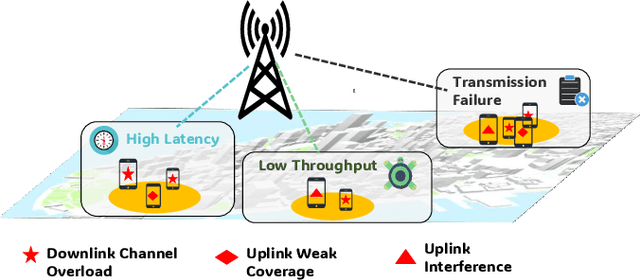
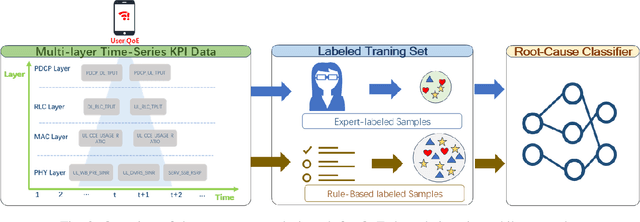
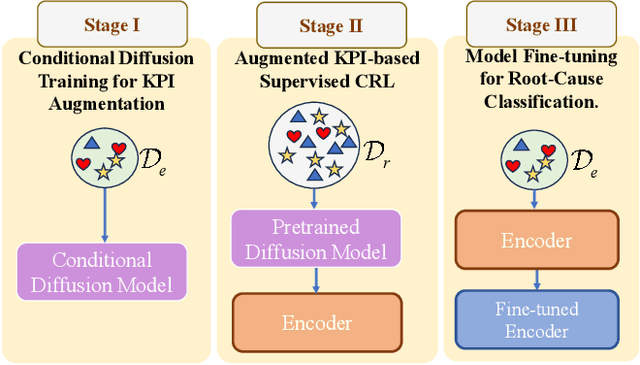
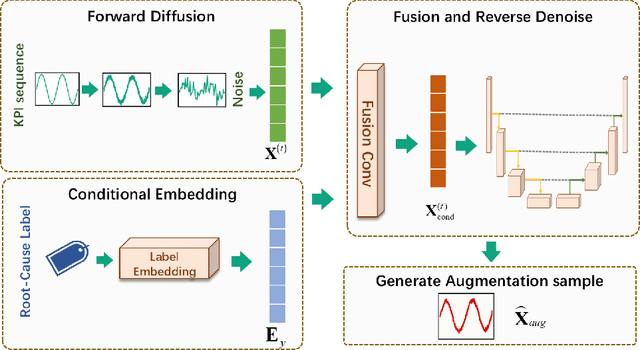
Diagnosing the root causes of Quality of Experience (QoE) degradations in operational mobile networks is challenging due to complex cross-layer interactions among kernel performance indicators (KPIs) and the scarcity of reliable expert annotations. Although rule-based heuristics can generate labels at scale, they are noisy and coarse-grained, limiting the accuracy of purely data-driven approaches. To address this, we propose DK-Root, a joint data-and-knowledge-driven framework that unifies scalable weak supervision with precise expert guidance for robust root-cause analysis. DK-Root first pretrains an encoder via contrastive representation learning using abundant rule-based labels while explicitly denoising their noise through a supervised contrastive objective. To supply task-faithful data augmentation, we introduce a class-conditional diffusion model that generates KPIs sequences preserving root-cause semantics, and by controlling reverse diffusion steps, it produces weak and strong augmentations that improve intra-class compactness and inter-class separability. Finally, the encoder and the lightweight classifier are jointly fine-tuned with scarce expert-verified labels to sharpen decision boundaries. Extensive experiments on a real-world, operator-grade dataset demonstrate state-of-the-art accuracy, with DK-Root surpassing traditional ML and recent semi-supervised time-series methods. Ablations confirm the necessity of the conditional diffusion augmentation and the pretrain-finetune design, validating both representation quality and classification gains.
STM3: Mixture of Multiscale Mamba for Long-Term Spatio-Temporal Time-Series Prediction
Aug 17, 2025Recently, spatio-temporal time-series prediction has developed rapidly, yet existing deep learning methods struggle with learning complex long-term spatio-temporal dependencies efficiently. The long-term spatio-temporal dependency learning brings two new challenges: 1) The long-term temporal sequence includes multiscale information naturally which is hard to extract efficiently; 2) The multiscale temporal information from different nodes is highly correlated and hard to model. To address these challenges, we propose an efficient \textit{\textbf{S}patio-\textbf{T}emporal \textbf{M}ultiscale \textbf{M}amba} (STM2) that includes a multiscale Mamba architecture to capture the multiscale information efficiently and simultaneously, and an adaptive graph causal convolution network to learn the complex multiscale spatio-temporal dependency. STM2 includes hierarchical information aggregation for different-scale information that guarantees their distinguishability. To capture diverse temporal dynamics across all spatial nodes more efficiently, we further propose an enhanced version termed \textit{\textbf{S}patio-\textbf{T}emporal \textbf{M}ixture of \textbf{M}ultiscale \textbf{M}amba} (STM3) that employs a special Mixture-of-Experts architecture, including a more stable routing strategy and a causal contrastive learning strategy to enhance the scale distinguishability. We prove that STM3 has much better routing smoothness and guarantees the pattern disentanglement for each expert successfully. Extensive experiments on real-world benchmarks demonstrate STM2/STM3's superior performance, achieving state-of-the-art results in long-term spatio-temporal time-series prediction.
First Token Probability Guided RAG for Telecom Question Answering
Jan 11, 2025Large Language Models (LLMs) have garnered significant attention for their impressive general-purpose capabilities. For applications requiring intricate domain knowledge, Retrieval-Augmented Generation (RAG) has shown a distinct advantage in incorporating domain-specific information into LLMs. However, existing RAG research has not fully addressed the challenges of Multiple Choice Question Answering (MCQA) in telecommunications, particularly in terms of retrieval quality and mitigating hallucinations. To tackle these challenges, we propose a novel first token probability guided RAG framework. This framework leverages confidence scores to optimize key hyperparameters, such as chunk number and chunk window size, while dynamically adjusting the context. Our method starts by retrieving the most relevant chunks and generates a single token as the potential answer. The probabilities of all options are then normalized to serve as confidence scores, which guide the dynamic adjustment of the context. By iteratively optimizing the hyperparameters based on these confidence scores, we can continuously improve RAG performance. We conducted experiments to validate the effectiveness of our framework, demonstrating its potential to enhance accuracy in domain-specific MCQA tasks.
Analyst Reports and Stock Performance: Evidence from the Chinese Market
Nov 13, 2024



This article applies natural language processing (NLP) to extract and quantify textual information to predict stock performance. Using an extensive dataset of Chinese analyst reports and employing a customized BERT deep learning model for Chinese text, this study categorizes the sentiment of the reports as positive, neutral, or negative. The findings underscore the predictive capacity of this sentiment indicator for stock volatility, excess returns, and trading volume. Specifically, analyst reports with strong positive sentiment will increase excess return and intraday volatility, and vice versa, reports with strong negative sentiment also increase volatility and trading volume, but decrease future excess return. The magnitude of this effect is greater for positive sentiment reports than for negative sentiment reports. This article contributes to the empirical literature on sentiment analysis and the response of the stock market to news in the Chinese stock market.
An overview of domain-specific foundation model: key technologies, applications and challenges
Sep 06, 2024The impressive performance of ChatGPT and other foundation-model-based products in human language understanding has prompted both academia and industry to explore how these models can be tailored for specific industries and application scenarios. This process, known as the customization of domain-specific foundation models, addresses the limitations of general-purpose models, which may not fully capture the unique patterns and requirements of domain-specific data. Despite its importance, there is a notable lack of comprehensive overview papers on building domain-specific foundation models, while numerous resources exist for general-purpose models. To bridge this gap, this article provides a timely and thorough overview of the methodology for customizing domain-specific foundation models. It introduces basic concepts, outlines the general architecture, and surveys key methods for constructing domain-specific models. Furthermore, the article discusses various domains that can benefit from these specialized models and highlights the challenges ahead. Through this overview, we aim to offer valuable guidance and reference for researchers and practitioners from diverse fields to develop their own customized foundation models.