 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Joint Spectrum and Power Allocation in Cellular Networks
Dec 19, 2020
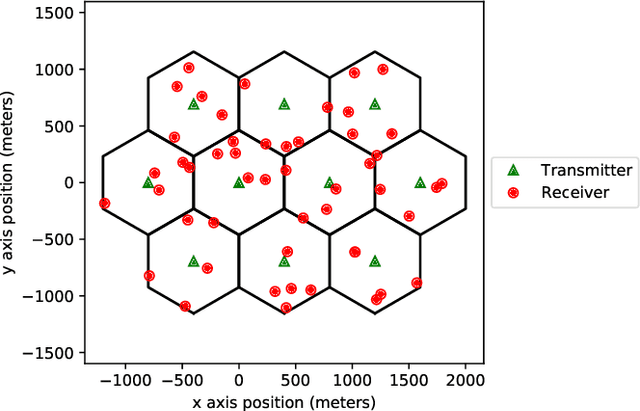

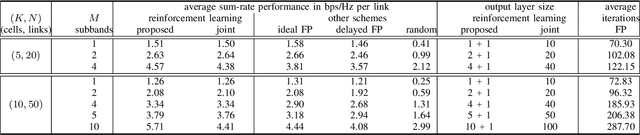
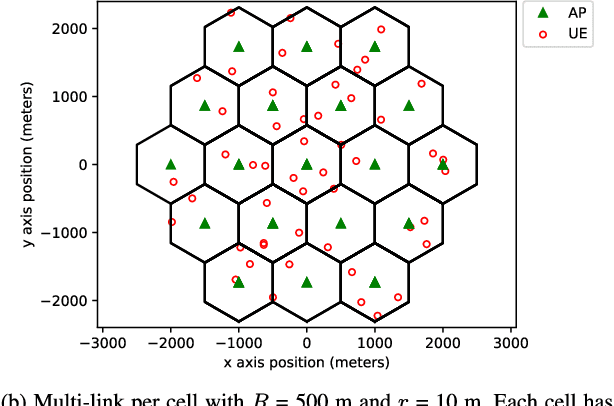
A wireless network operator typically divides the radio spectrum it possesses into a number of subbands. In a cellular network those subbands are then reused in many cells. To mitigate co-channel interference, a joint spectrum and power allocation problem is often formulated to maximize a sum-rate objective. The best known algorithms for solving such problems generally require instantaneous global channel state information and a centralized optimizer. In fact those algorithms have not been implemented in practice in large networks with time-varying subbands. Deep reinforcement learning algorithms are promising tools for solving complex resource management problems. A major challenge here is that spectrum allocation involves discrete subband selection, whereas power allocation involves continuous variables. In this paper, a learning framework is proposed to optimize both discrete and continuous decision variables. Specifically, two separate deep reinforcement learning algorithms are designed to be executed and trained simultaneously to maximize a joint objective. Simulation results show that the proposed scheme outperforms both the state-of-the-art fractional programming algorithm and a previous solution based on deep reinforcement learning.
Deep Actor-Critic Learning for Distributed Power Control in Wireless Mobile Networks
Sep 14, 2020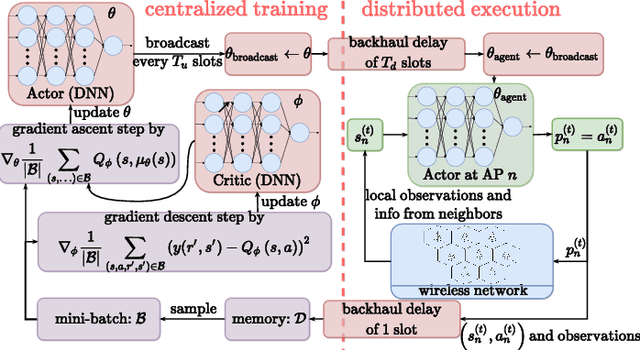
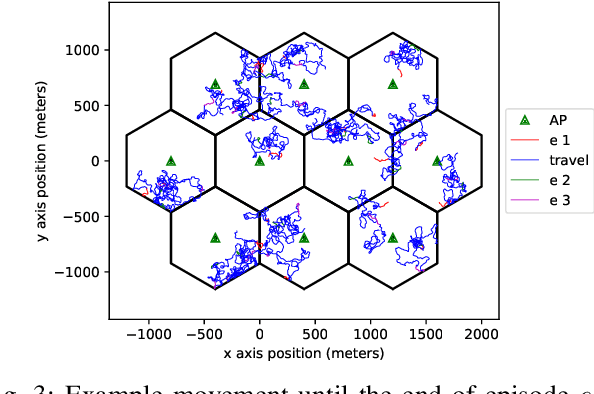
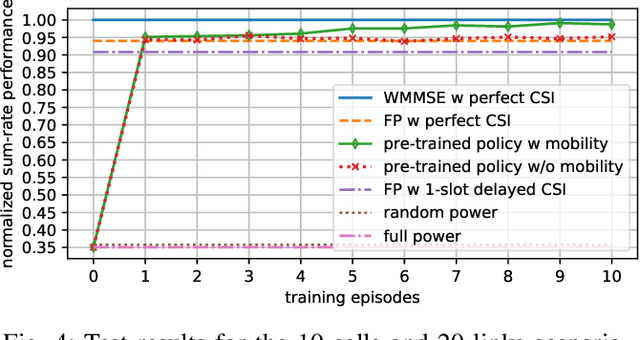
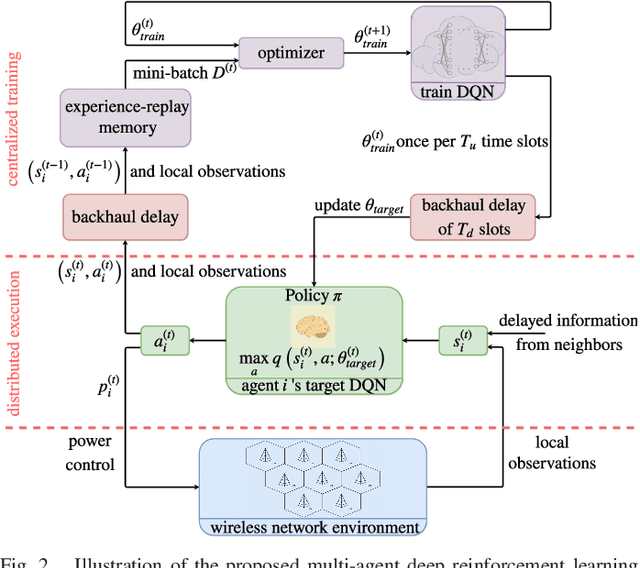
Deep reinforcement learning offers a model-free alternative to supervised deep learning and classical optimization for solving the transmit power control problem in wireless networks. The multi-agent deep reinforcement learning approach considers each transmitter as an individual learning agent that determines its transmit power level by observing the local wireless environment. Following a certain policy, these agents learn to collaboratively maximize a global objective, e.g., a sum-rate utility function. This multi-agent scheme is easily scalable and practically applicable to large-scale cellular networks. In this work, we present a distributively executed continuous power control algorithm with the help of deep actor-critic learning, and more specifically, by adapting deep deterministic policy gradient. Furthermore, we integrate the proposed power control algorithm to a time-slotted system where devices are mobile and channel conditions change rapidly. We demonstrate the functionality of the proposed algorithm using simulation results.
Deep Reinforcement Learning for Distributed Dynamic Power Allocation in Wireless Networks
Aug 01, 2018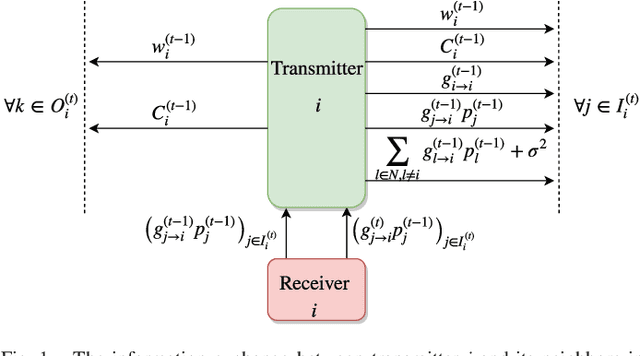

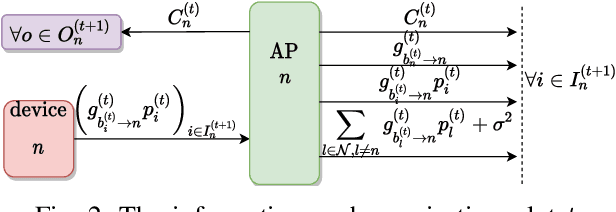
This work demonstrates the potential of deep reinforcement learning techniques for transmit power control in emerging and future wireless networks. Various techniques have been proposed in the literature to find near-optimal power allocations, often by solving a challenging optimization problem. Most of these algorithms are not scalable to large networks in real-world scenarios because of their computational complexity and instantaneous cross-cell channel state information (CSI) requirement. In this paper, a model-free distributed dynamic power allocation scheme is developed based on deep reinforcement learning. Each transmitter collects CSI and quality of service (QoS) information from several neighbors and adapts its own transmit power accordingly. The objective is to maximize a weighted sum-rate utility function, which can be particularized to achieve maximum sum-rate or proportionally fair scheduling (with weights that are changing over time). Both random variations and delays in the CSI are inherently addressed using deep Q-learning. For a typical network architecture, the proposed algorithm is shown to achieve near-optimal power allocation in real time based on delayed CSI measurements available to the agents. This work indicates that deep reinforcement learning based radio resource management can be very fast and deliver highly competitive performance, especially in practical scenarios where the system model is inaccurate and CSI delay is non-negligible.