 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDySCO: Dynamic Attention-Scaling Decoding for Long-Context LMs
Feb 25, 2026Understanding and reasoning over long contexts is a crucial capability for language models (LMs). Although recent models support increasingly long context windows, their accuracy often deteriorates as input length grows. In practice, models often struggle to keep attention aligned with the most relevant context throughout decoding. In this work, we propose DySCO, a novel decoding algorithm for improving long-context reasoning. DySCO leverages retrieval heads--a subset of attention heads specialized for long-context retrieval--to identify task-relevant tokens at each decoding step and explicitly up-weight them. By doing so, DySCO dynamically adjusts attention during generation to better utilize relevant context. The method is training-free and can be applied directly to any off-the-shelf LMs. Across multiple instruction-tuned and reasoning models, DySCO consistently improves performance on challenging long-context reasoning benchmarks, yielding relative gains of up to 25% on MRCR and LongBenchV2 at 128K context length with modest additional compute. Further analysis highlights the importance of both dynamic attention rescaling and retrieval-head-guided selection for the effectiveness of the method, while providing interpretability insights into decoding-time attention behavior. Our code is available at https://github.com/princeton-pli/DySCO.
Query-Focused Retrieval Heads Improve Long-Context Reasoning and Re-ranking
Jun 11, 2025Recent work has identified retrieval heads (Wu et al., 2025b), a subset of attention heads responsible for retrieving salient information in long-context language models (LMs), as measured by their copy-paste behavior in Needle-in-a-Haystack tasks. In this paper, we introduce QRHEAD (Query-Focused Retrieval Head), an improved set of attention heads that enhance retrieval from long context. We identify QRHEAD by aggregating attention scores with respect to the input query, using a handful of examples from real-world tasks (e.g., long-context QA). We further introduce QR- RETRIEVER, an efficient and effective retriever that uses the accumulated attention mass of QRHEAD as retrieval scores. We use QR- RETRIEVER for long-context reasoning by selecting the most relevant parts with the highest retrieval scores. On multi-hop reasoning tasks LongMemEval and CLIPPER, this yields over 10% performance gains over full context and outperforms strong dense retrievers. We also evaluate QRRETRIEVER as a re-ranker on the BEIR benchmark and find that it achieves strong zero-shot performance, outperforming other LLM-based re-rankers such as RankGPT. Further analysis shows that both the querycontext attention scoring and task selection are crucial for identifying QRHEAD with strong downstream utility. Overall, our work contributes a general-purpose retriever and offers interpretability insights into the long-context capabilities of LMs.
Learning Composable Chains-of-Thought
May 28, 2025A common approach for teaching large language models (LLMs) to reason is to train on chain-of-thought (CoT) traces of in-distribution reasoning problems, but such annotated data is costly to obtain for every problem of interest. We want reasoning models to generalize beyond their training distribution, and ideally to generalize compositionally: combine atomic reasoning skills to solve harder, unseen reasoning tasks. We take a step towards compositional generalization of reasoning skills when addressing a target compositional task that has no labeled CoT data. We find that simply training models on CoT data of atomic tasks leads to limited generalization, but minimally modifying CoT formats of constituent atomic tasks to be composable can lead to improvements. We can train "atomic CoT" models on the atomic tasks with Composable CoT data and combine them with multitask learning or model merging for better zero-shot performance on the target compositional task. Such a combined model can be further bootstrapped on a small amount of compositional data using rejection sampling fine-tuning (RFT). Results on string operations and natural language skill compositions show that training LLMs on Composable CoT outperforms multitask learning and continued fine-tuning baselines within a given training data budget.
ChartMuseum: Testing Visual Reasoning Capabilities of Large Vision-Language Models
May 19, 2025Chart understanding presents a unique challenge for large vision-language models (LVLMs), as it requires the integration of sophisticated textual and visual reasoning capabilities. However, current LVLMs exhibit a notable imbalance between these skills, falling short on visual reasoning that is difficult to perform in text. We conduct a case study using a synthetic dataset solvable only through visual reasoning and show that model performance degrades significantly with increasing visual complexity, while human performance remains robust. We then introduce ChartMuseum, a new Chart Question Answering (QA) benchmark containing 1,162 expert-annotated questions spanning multiple reasoning types, curated from real-world charts across 184 sources, specifically built to evaluate complex visual and textual reasoning. Unlike prior chart understanding benchmarks -- where frontier models perform similarly and near saturation -- our benchmark exposes a substantial gap between model and human performance, while effectively differentiating model capabilities: although humans achieve 93% accuracy, the best-performing model Gemini-2.5-Pro attains only 63.0%, and the leading open-source LVLM Qwen2.5-VL-72B-Instruct achieves only 38.5%. Moreover, on questions requiring primarily visual reasoning, all models experience a 35%-55% performance drop from text-reasoning-heavy question performance. Lastly, our qualitative error analysis reveals specific categories of visual reasoning that are challenging for current LVLMs.
LongProc: Benchmarking Long-Context Language Models on Long Procedural Generation
Jan 09, 2025



Existing benchmarks for evaluating long-context language models (LCLMs) primarily focus on long-context recall, requiring models to produce short responses based on a few critical snippets while processing thousands of irrelevant tokens. We introduce LongProc (Long Procedural Generation), a new benchmark that requires both the integration of highly dispersed information and long-form generation. LongProc consists of six diverse procedural generation tasks, such as extracting structured information from HTML pages into a TSV format and executing complex search procedures to create travel plans. These tasks challenge LCLMs by testing their ability to follow detailed procedural instructions, synthesize and reason over dispersed information, and generate structured, long-form outputs (up to 8K tokens). Furthermore, as these tasks adhere to deterministic procedures and yield structured outputs, they enable reliable rule-based evaluation. We evaluate 17 LCLMs on LongProc across three difficulty levels, with maximum numbers of output tokens set at 500, 2K, and 8K. Notably, while all tested models claim a context window size above 32K tokens, open-weight models typically falter on 2K-token tasks, and closed-source models like GPT-4o show significant degradation on 8K-token tasks. Further analysis reveals that LCLMs struggle to maintain long-range coherence in long-form generations. These findings highlight critical limitations in current LCLMs and suggest substantial room for improvement. Data and code available at: https://princeton-pli.github.io/LongProc
Understanding Synthetic Context Extension via Retrieval Heads
Oct 29, 2024



Long-context LLMs are increasingly in demand for applications such as retrieval-augmented generation. To defray the cost of pretraining LLMs over long contexts, recent work takes an approach of synthetic context extension: fine-tuning LLMs with synthetically generated long-context data in a post-training stage. However, it remains unclear how and why this synthetic context extension imparts abilities for downstream long-context tasks. In this paper, we investigate fine-tuning on synthetic data for three long-context tasks that require retrieval and reasoning. We vary the realism of "needle" concepts to be retrieved and diversity of the surrounding "haystack" context, from using LLMs to construct synthetic documents to using templated relations and creating symbolic datasets. We find that models trained on synthetic data fall short of the real data, but surprisingly, the mismatch can be interpreted and even predicted in terms of a special set of attention heads that are responsible for retrieval over long context: retrieval heads (Wu et al., 2024). The retrieval heads learned on synthetic data are mostly subsets of the retrieval heads learned on real data, and there is a strong correlation between the recall of heads learned and the downstream performance of a model. Furthermore, with attention knockout and activation patching, we mechanistically show that retrieval heads are necessary and explain model performance, although they are not totally sufficient. Our results shed light on how to interpret synthetic data fine-tuning performance and how to approach creating better data for learning real-world capabilities over long contexts.
To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning
Sep 18, 2024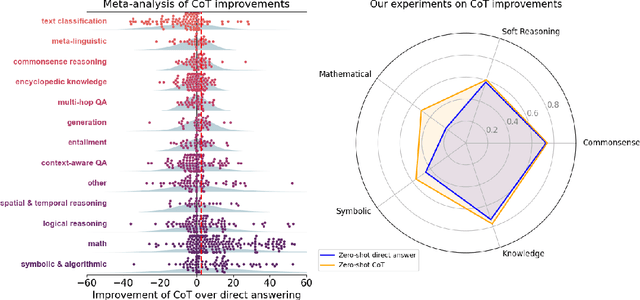


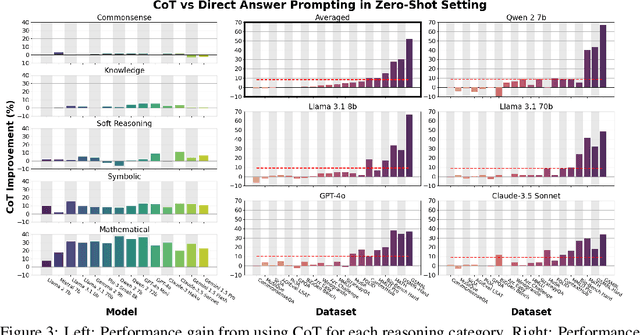
Chain-of-thought (CoT) via prompting is the de facto method for eliciting reasoning capabilities from large language models (LLMs). But for what kinds of tasks is this extra ``thinking'' really helpful? To analyze this, we conducted a quantitative meta-analysis covering over 100 papers using CoT and ran our own evaluations of 20 datasets across 14 models. Our results show that CoT gives strong performance benefits primarily on tasks involving math or logic, with much smaller gains on other types of tasks. On MMLU, directly generating the answer without CoT leads to almost identical accuracy as CoT unless the question or model's response contains an equals sign, indicating symbolic operations and reasoning. Following this finding, we analyze the behavior of CoT on these problems by separating planning and execution and comparing against tool-augmented LLMs. Much of CoT's gain comes from improving symbolic execution, but it underperforms relative to using a symbolic solver. Our results indicate that CoT can be applied selectively, maintaining performance while saving inference costs. Furthermore, they suggest a need to move beyond prompt-based CoT to new paradigms that better leverage intermediate computation across the whole range of LLM applications.
LoFiT: Localized Fine-tuning on LLM Representations
Jun 03, 2024



Recent work in interpretability shows that large language models (LLMs) can be adapted for new tasks in a learning-free way: it is possible to intervene on LLM representations to elicit desired behaviors for alignment. For instance, adding certain bias vectors to the outputs of certain attention heads is reported to boost the truthfulness of models. In this work, we show that localized fine-tuning serves as an effective alternative to such representation intervention methods. We introduce a framework called Localized Fine-Tuning on LLM Representations (LoFiT), which identifies a subset of attention heads that are most important for learning a specific task, then trains offset vectors to add to the model's hidden representations at those selected heads. LoFiT localizes to a sparse set of heads (3%) and learns the offset vectors from limited training data, comparable to the settings used for representation intervention. For truthfulness and reasoning tasks, we find that LoFiT's intervention vectors are more effective for LLM adaptation than vectors from representation intervention methods such as Inference-time Intervention. We also find that the localization step is important: selecting a task-specific set of attention heads can lead to higher performance than intervening on heads selected for a different task. Finally, for the tasks we study, LoFiT achieves comparable performance to other parameter-efficient fine-tuning methods such as LoRA, despite modifying 20x-200x fewer parameters than these methods.