 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Advanced Reasoning of Large Language Models via Black-Box Interaction
Aug 26, 2025Existing tasks fall short in evaluating reasoning ability of Large Language Models (LLMs) in an interactive, unknown environment. This deficiency leads to the isolated assessment of deductive, inductive, and abductive reasoning, neglecting the integrated reasoning process that is indispensable for humans discovery of real world. We introduce a novel evaluation paradigm, \textit{black-box interaction}, to tackle this challenge. A black-box is defined by a hidden function that maps a specific set of inputs to outputs. LLMs are required to unravel the hidden function behind the black-box by interacting with it in given exploration turns, and reasoning over observed input-output pairs. Leveraging this idea, we build the \textsc{Oracle} benchmark which comprises 6 types of black-box task and 96 black-boxes. 19 modern LLMs are benchmarked. o3 ranks first in 5 of the 6 tasks, achieving over 70\% accuracy on most easy black-boxes. But it still struggles with some hard black-box tasks, where its average performance drops below 40\%. Further analysis indicates a universal difficulty among LLMs: They lack the high-level planning capability to develop efficient and adaptive exploration strategies for hypothesis refinement.
Improving Brain-to-Image Reconstruction via Fine-Grained Text Bridging
May 29, 2025Brain-to-Image reconstruction aims to recover visual stimuli perceived by humans from brain activity. However, the reconstructed visual stimuli often missing details and semantic inconsistencies, which may be attributed to insufficient semantic information. To address this issue, we propose an approach named Fine-grained Brain-to-Image reconstruction (FgB2I), which employs fine-grained text as bridge to improve image reconstruction. FgB2I comprises three key stages: detail enhancement, decoding fine-grained text descriptions, and text-bridged brain-to-image reconstruction. In the detail-enhancement stage, we leverage large vision-language models to generate fine-grained captions for visual stimuli and experimentally validate its importance. We propose three reward metrics (object accuracy, text-image semantic similarity, and image-image semantic similarity) to guide the language model in decoding fine-grained text descriptions from fMRI signals. The fine-grained text descriptions can be integrated into existing reconstruction methods to achieve fine-grained Brain-to-Image reconstruction.
Improve Language Model and Brain Alignment via Associative Memory
May 20, 2025Associative memory engages in the integration of relevant information for comprehension in the human cognition system. In this work, we seek to improve alignment between language models and human brain while processing speech information by integrating associative memory. After verifying the alignment between language model and brain by mapping language model activations to brain activity, the original text stimuli expanded with simulated associative memory are regarded as input to computational language models. We find the alignment between language model and brain is improved in brain regions closely related to associative memory processing. We also demonstrate large language models after specific supervised fine-tuning better align with brain response, by building the \textit{Association} dataset containing 1000 samples of stories, with instructions encouraging associative memory as input and associated content as output.
Decoding the Echoes of Vision from fMRI: Memory Disentangling for Past Semantic Information
Sep 30, 2024



The human visual system is capable of processing continuous streams of visual information, but how the brain encodes and retrieves recent visual memories during continuous visual processing remains unexplored. This study investigates the capacity of working memory to retain past information under continuous visual stimuli. And then we propose a new task Memory Disentangling, which aims to extract and decode past information from fMRI signals. To address the issue of interference from past memory information, we design a disentangled contrastive learning method inspired by the phenomenon of proactive interference. This method separates the information between adjacent fMRI signals into current and past components and decodes them into image descriptions. Experimental results demonstrate that this method effectively disentangles the information within fMRI signals. This research could advance brain-computer interfaces and mitigate the problem of low temporal resolution in fMRI.
MDD-5k: A New Diagnostic Conversation Dataset for Mental Disorders Synthesized via Neuro-Symbolic LLM Agents
Aug 22, 2024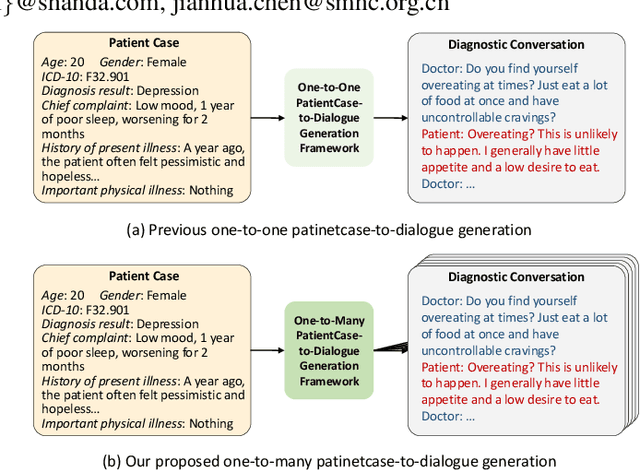

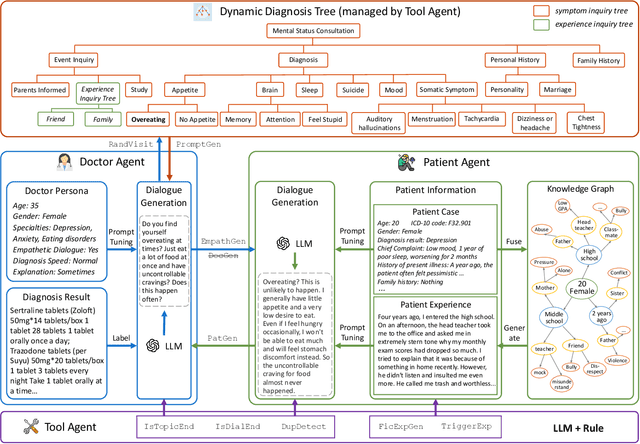

The clinical diagnosis of most mental disorders primarily relies on the conversations between psychiatrist and patient. The creation of such diagnostic conversation datasets is promising to boost the AI mental healthcare community. However, directly collecting the conversations in real diagnosis scenarios is near impossible due to stringent privacy and ethical considerations. To address this issue, we seek to synthesize diagnostic conversation by exploiting anonymous patient cases that are easier to access. Specifically, we design a neuro-symbolic multi-agent framework for synthesizing the diagnostic conversation of mental disorders with large language models. It takes patient case as input and is capable of generating multiple diverse conversations with one single patient case. The framework basically involves the interaction between a doctor agent and a patient agent, and achieves text generation under symbolic control via a dynamic diagnosis tree from a tool agent. By applying the proposed framework, we develop the largest Chinese mental disorders diagnosis dataset MDD-5k, which is built upon 1000 cleaned real patient cases by cooperating with a pioneering psychiatric hospital, and contains 5000 high-quality long conversations with diagnosis results as labels. To the best of our knowledge, it's also the first labelled Chinese mental disorders diagnosis dataset. Human evaluation demonstrates the proposed MDD-5k dataset successfully simulates human-like diagnostic process of mental disorders. The dataset and code will become publicly accessible in https://github.com/lemonsis/MDD-5k.
Language Reconstruction with Brain Predictive Coding from fMRI Data
May 19, 2024
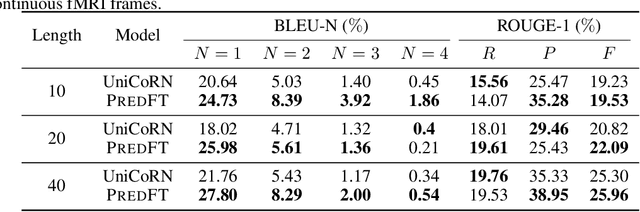


Many recent studies have shown that the perception of speech can be decoded from brain signals and subsequently reconstructed as continuous language. However, there is a lack of neurological basis for how the semantic information embedded within brain signals can be used more effectively to guide language reconstruction. The theory of predictive coding suggests that human brain naturally engages in continuously predicting future word representations that span multiple timescales. This implies that the decoding of brain signals could potentially be associated with a predictable future. To explore the predictive coding theory within the context of language reconstruction, this paper proposes a novel model \textsc{PredFT} for jointly modeling neural decoding and brain prediction. It consists of a main decoding network for language reconstruction and a side network for predictive coding. The side network obtains brain predictive coding representation from related brain regions of interest with a multi-head self-attention module. This representation is fused into the main decoding network with cross-attention to facilitate the language models' generation process. Experiments are conducted on the largest naturalistic language comprehension fMRI dataset Narratives. \textsc{PredFT} achieves current state-of-the-art decoding performance with a maximum BLEU-1 score of $27.8\%$.
Data Contamination Issues in Brain-to-Text Decoding
Dec 26, 2023



Decoding non-invasive cognitive signals to natural language has long been the goal of building practical brain-computer interfaces (BCIs). Recent major milestones have successfully decoded cognitive signals like functional Magnetic Resonance Imaging (fMRI) and electroencephalogram (EEG) into text under open vocabulary setting. However, how to split the datasets for training, validating, and testing in cognitive signal decoding task still remains controversial. In this paper, we conduct systematic analysis on current dataset splitting methods and find the existence of data contamination largely exaggerates model performance. Specifically, first we find the leakage of test subjects' cognitive signals corrupts the training of a robust encoder. Second, we prove the leakage of text stimuli causes the auto-regressive decoder to memorize information in test set. The decoder generates highly accurate text not because it truly understands cognitive signals. To eliminate the influence of data contamination and fairly evaluate different models' generalization ability, we propose a new splitting method for different types of cognitive datasets (e.g. fMRI, EEG). We also test the performance of SOTA Brain-to-Text decoding models under the proposed dataset splitting paradigm as baselines for further research.
CTRLStruct: Dialogue Structure Learning for Open-Domain Response Generation
Mar 02, 2023



Dialogue structure discovery is essential in dialogue generation. Well-structured topic flow can leverage background information and predict future topics to help generate controllable and explainable responses. However, most previous work focused on dialogue structure learning in task-oriented dialogue other than open-domain dialogue which is more complicated and challenging. In this paper, we present a new framework CTRLStruct for dialogue structure learning to effectively explore topic-level dialogue clusters as well as their transitions with unlabelled information. Precisely, dialogue utterances encoded by bi-directional Transformer are further trained through a special designed contrastive learning task to improve representation. Then we perform clustering to utterance-level representations and form topic-level clusters that can be considered as vertices in dialogue structure graph. The edges in the graph indicating transition probability between vertices are calculated by mimicking expert behavior in datasets. Finally, dialogue structure graph is integrated into dialogue model to perform controlled response generation. Experiments on two popular open-domain dialogue datasets show our model can generate more coherent responses compared to some excellent dialogue models, as well as outperform some typical sentence embedding methods in dialogue utterance representation. Code is available in GitHub.