 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Brain-to-Image Reconstruction via Fine-Grained Text Bridging
May 29, 2025Brain-to-Image reconstruction aims to recover visual stimuli perceived by humans from brain activity. However, the reconstructed visual stimuli often missing details and semantic inconsistencies, which may be attributed to insufficient semantic information. To address this issue, we propose an approach named Fine-grained Brain-to-Image reconstruction (FgB2I), which employs fine-grained text as bridge to improve image reconstruction. FgB2I comprises three key stages: detail enhancement, decoding fine-grained text descriptions, and text-bridged brain-to-image reconstruction. In the detail-enhancement stage, we leverage large vision-language models to generate fine-grained captions for visual stimuli and experimentally validate its importance. We propose three reward metrics (object accuracy, text-image semantic similarity, and image-image semantic similarity) to guide the language model in decoding fine-grained text descriptions from fMRI signals. The fine-grained text descriptions can be integrated into existing reconstruction methods to achieve fine-grained Brain-to-Image reconstruction.
C2F-TP: A Coarse-to-Fine Denoising Framework for Uncertainty-Aware Trajectory Prediction
Dec 17, 2024Accurately predicting the trajectory of vehicles is critically important for ensuring safety and reliability in autonomous driving. Although considerable research efforts have been made recently, the inherent trajectory uncertainty caused by various factors including the dynamic driving intends and the diverse driving scenarios still poses significant challenges to accurate trajectory prediction. To address this issue, we propose C2F-TP, a coarse-to-fine denoising framework for uncertainty-aware vehicle trajectory prediction. C2F-TP features an innovative two-stage coarse-to-fine prediction process. Specifically, in the spatial-temporal interaction stage, we propose a spatial-temporal interaction module to capture the inter-vehicle interactions and learn a multimodal trajectory distribution, from which a certain number of noisy trajectories are sampled. Next, in the trajectory refinement stage, we design a conditional denoising model to reduce the uncertainty of the sampled trajectories through a step-wise denoising operation. Extensive experiments are conducted on two real datasets NGSIM and highD that are widely adopted in trajectory prediction. The result demonstrates the effectiveness of our proposal.
MORTAR: A Model-based Runtime Action Repair Framework for AI-enabled Cyber-Physical Systems
Aug 07, 2024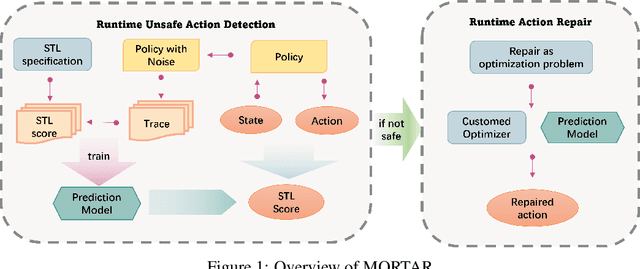



Cyber-Physical Systems (CPSs) are increasingly prevalent across various industrial and daily-life domains, with applications ranging from robotic operations to autonomous driving. With recent advancements in artificial intelligence (AI), learning-based components, especially AI controllers, have become essential in enhancing the functionality and efficiency of CPSs. However, the lack of interpretability in these AI controllers presents challenges to the safety and quality assurance of AI-enabled CPSs (AI-CPSs). Existing methods for improving the safety of AI controllers often involve neural network repair, which requires retraining with additional adversarial examples or access to detailed internal information of the neural network. Hence, these approaches have limited applicability for black-box policies, where only the inputs and outputs are accessible during operation. To overcome this, we propose MORTAR, a runtime action repair framework designed for AI-CPSs in this work. MORTAR begins by constructing a prediction model that forecasts the quality of actions proposed by the AI controller. If an unsafe action is detected, MORTAR then initiates a repair process to correct it. The generation of repaired actions is achieved through an optimization process guided by the safety estimates from the prediction model. We evaluate the effectiveness of MORTAR across various CPS tasks and AI controllers. The results demonstrate that MORTAR can efficiently improve task completion rates of AI controllers under specified safety specifications. Meanwhile, it also maintains minimal computational overhead, ensuring real-time operation of the AI-CPSs.
LEMoE: Advanced Mixture of Experts Adaptor for Lifelong Model Editing of Large Language Models
Jun 28, 2024Large language models (LLMs) require continual knowledge updates to stay abreast of the ever-changing world facts, prompting the formulation of lifelong model editing task. While recent years have witnessed the development of various techniques for single and batch editing, these methods either fail to apply or perform sub-optimally when faced with lifelong editing. In this paper, we introduce LEMoE, an advanced Mixture of Experts (MoE) adaptor for lifelong model editing. We first analyze the factors influencing the effectiveness of conventional MoE adaptor in lifelong editing, including catastrophic forgetting, inconsistent routing and order sensitivity. Based on these insights, we propose a tailored module insertion method to achieve lifelong editing, incorporating a novel KV anchor routing to enhance routing consistency between training and inference stage, along with a concise yet effective clustering-based editing order planning. Experimental results demonstrate the effectiveness of our method in lifelong editing, surpassing previous model editing techniques while maintaining outstanding performance in batch editing task. Our code will be available.
MEMoE: Enhancing Model Editing with Mixture of Experts Adaptors
May 29, 2024Model editing aims to efficiently alter the behavior of Large Language Models (LLMs) within a desired scope, while ensuring no adverse impact on other inputs. Recent years have witnessed various model editing methods been proposed. However, these methods either exhibit poor overall performance or struggle to strike a balance between generalization and locality. We propose MOMoE, a model editing adapter utilizing a Mixture of Experts (MoE) architecture with a knowledge anchor routing strategy. MOMoE updates knowledge using a bypass MoE structure, keeping the original parameters unchanged to preserve the general ability of LLMs. And, the knowledge anchor routing ensures that inputs requiring similar knowledge are routed to the same expert, thereby enhancing the generalization of the updated knowledge. Experimental results show the superiority of our approach over both batch editing and sequential batch editing tasks, exhibiting exceptional overall performance alongside outstanding balance between generalization and locality. Our code will be available.
Semantic are Beacons: A Semantic Perspective for Unveiling Parameter-Efficient Fine-Tuning in Knowledge Learning
May 28, 2024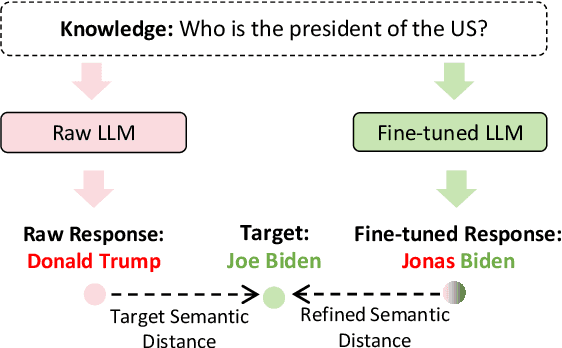
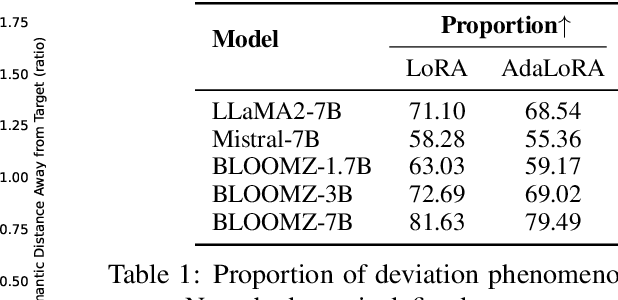
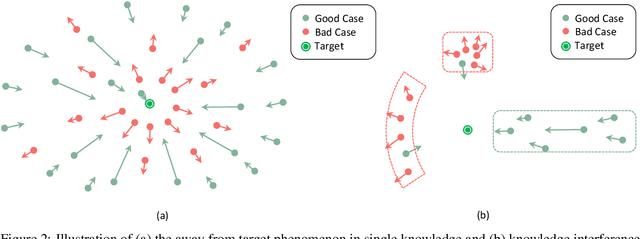
Parameter-Efficient Fine-Tuning (PEFT) methods enable efficient adaptation of Large Language Models (LLMs) to various downstream applications. However, the effectiveness of the PEFT diminishes notably when downstream tasks require accurate learning of factual knowledge. In this paper, we adopt a semantic perspective to investigate this phenomenon, uncovering the reasons behind PEFT's limitations in knowledge learning task. Our findings reveal that: (1) PEFT presents a notable risk of pushing the model away from the intended knowledge target; (2) multiple knowledge interfere with each other, and such interference suppresses the learning and expression of knowledge features. Based on these insights, we introduce a data filtering strategy to exclude data that is detrimental to knowledge learning and a re-weighted learning strategy to make the model attentive to semantic distance during knowledge learning. Experimental results demonstrate the effectiveness of the proposed method on open-source large language model, further validate the semantic challenge in PEFT, thus paving the way for future research.
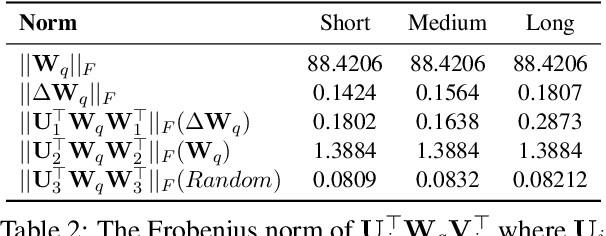
InfoDiffusion: Information Entropy Aware Diffusion Process for Non-Autoregressive Text Generation
Oct 18, 2023
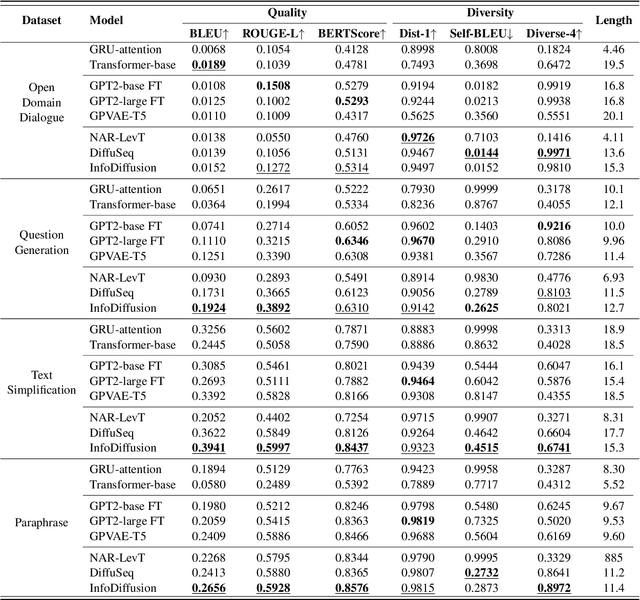
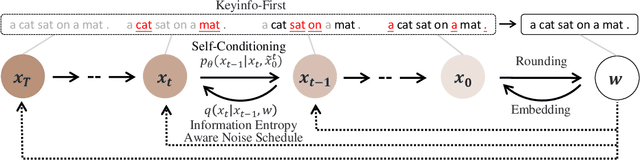
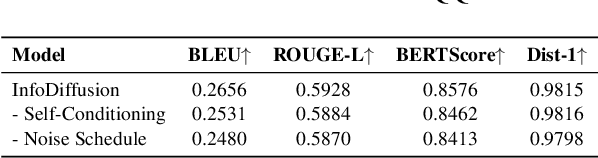
Diffusion models have garnered considerable interest in the field of text generation. Several studies have explored text diffusion models with different structures and applied them to various tasks, including named entity recognition and summarization. However, there exists a notable disparity between the "easy-first" text generation process of current diffusion models and the "keyword-first" natural text generation process of humans, which has received limited attention. To bridge this gap, we propose InfoDiffusion, a non-autoregressive text diffusion model. Our approach introduces a "keyinfo-first" generation strategy and incorporates a noise schedule based on the amount of text information. In addition, InfoDiffusion combines self-conditioning with a newly proposed partially noising model structure. Experimental results show that InfoDiffusion outperforms the baseline model in terms of generation quality and diversity, as well as exhibiting higher sampling efficiency.
3D Shuffle-Mixer: An Efficient Context-Aware Vision Learner of Transformer-MLP Paradigm for Dense Prediction in Medical Volume
Apr 14, 2022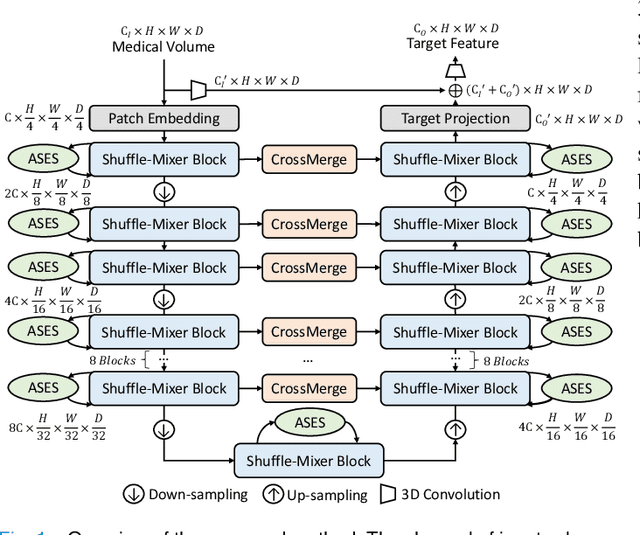
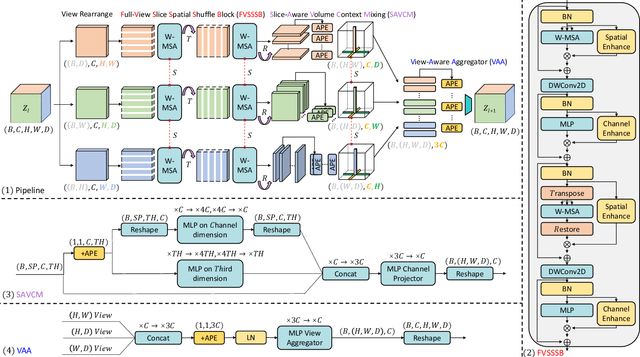
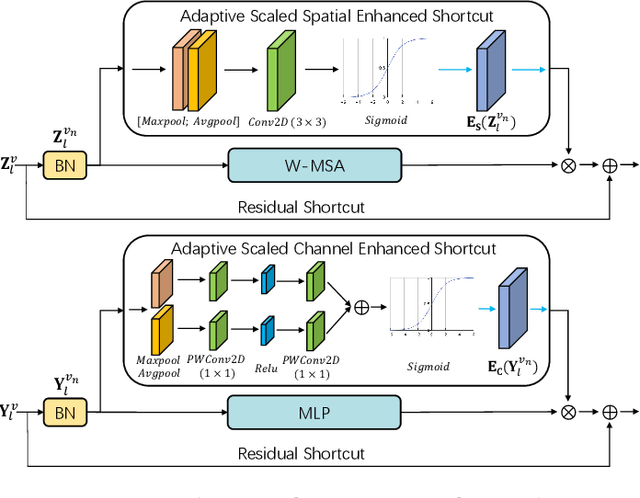
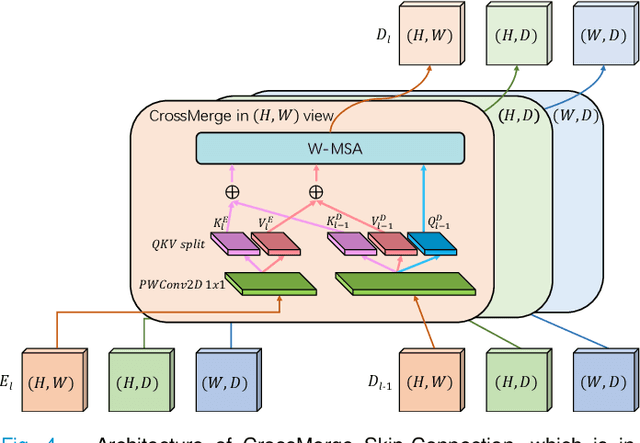
Dense prediction in medical volume provides enriched guidance for clinical analysis. CNN backbones have met bottleneck due to lack of long-range dependencies and global context modeling power. Recent works proposed to combine vision transformer with CNN, due to its strong global capture ability and learning capability. However, most works are limited to simply applying pure transformer with several fatal flaws (i.e., lack of inductive bias, heavy computation and little consideration for 3D data). Therefore, designing an elegant and efficient vision transformer learner for dense prediction in medical volume is promising and challenging. In this paper, we propose a novel 3D Shuffle-Mixer network of a new Local Vision Transformer-MLP paradigm for medical dense prediction. In our network, a local vision transformer block is utilized to shuffle and learn spatial context from full-view slices of rearranged volume, a residual axial-MLP is designed to mix and capture remaining volume context in a slice-aware manner, and a MLP view aggregator is employed to project the learned full-view rich context to the volume feature in a view-aware manner. Moreover, an Adaptive Scaled Enhanced Shortcut is proposed for local vision transformer to enhance feature along spatial and channel dimensions adaptively, and a CrossMerge is proposed to skip-connects the multi-scale feature appropriately in the pyramid architecture. Extensive experiments demonstrate the proposed model outperforms other state-of-the-art medical dense prediction methods.
Fusion of medical imaging and electronic health records with attention and multi-head machanisms
Dec 22, 2021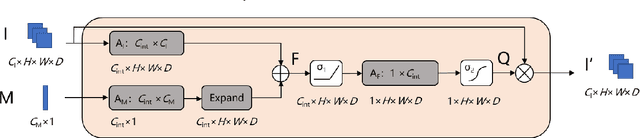
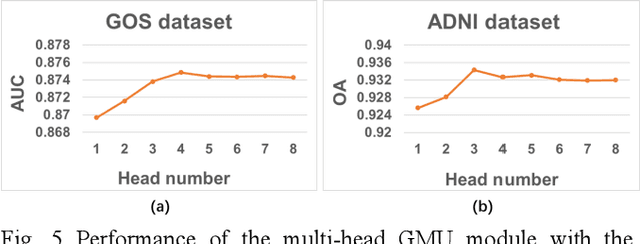
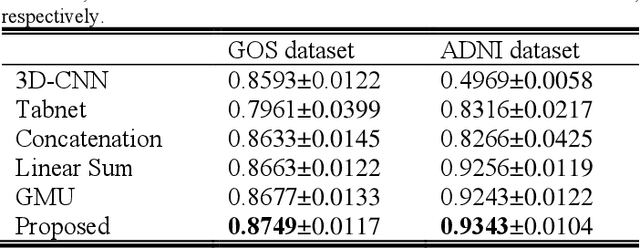

Doctors often make diagonostic decisions based on patient's image scans, such as magnetic resonance imaging (MRI), and patient's electronic health records (EHR) such as age, gender, blood pressure and so on. Despite a lot of automatic methods have been proposed for either image or text analysis in computer vision or natural language research areas, much fewer studies have been developed for the fusion of medical image and EHR data for medical problems. Among existing early or intermediate fusion methods, concatenation of features from both modalities is still a mainstream. For a better exploiting of image and EHR data, we propose a multi-modal attention module which use EHR data to help the selection of important regions during image feature extraction process conducted by traditional CNN. Moreover, we propose to incorporate multi-head machnism to gated multimodal unit (GMU) to make it able to parallelly fuse image and EHR features in different subspaces. With the help of the two modules, existing CNN architecture can be enhanced using both modalities. Experiments on predicting Glasgow outcome scale (GOS) of intracerebral hemorrhage patients and classifying Alzheimer's Disease showed the proposed method can automatically focus on task-related areas and achieve better results by making better use of image and EHR features.