 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion of medical imaging and electronic health records with attention and multi-head machanisms
Paper and Code
Dec 22, 2021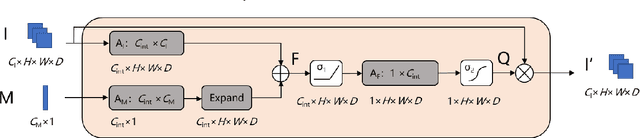
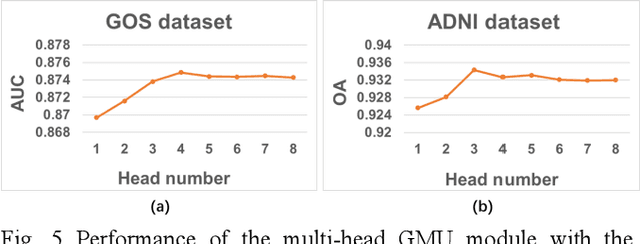
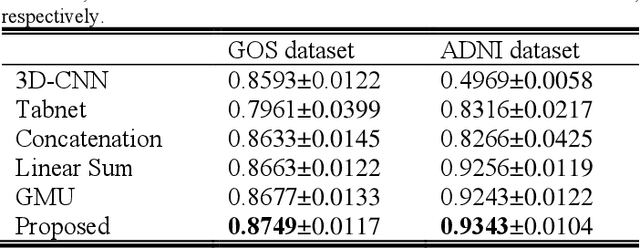

Doctors often make diagonostic decisions based on patient's image scans, such as magnetic resonance imaging (MRI), and patient's electronic health records (EHR) such as age, gender, blood pressure and so on. Despite a lot of automatic methods have been proposed for either image or text analysis in computer vision or natural language research areas, much fewer studies have been developed for the fusion of medical image and EHR data for medical problems. Among existing early or intermediate fusion methods, concatenation of features from both modalities is still a mainstream. For a better exploiting of image and EHR data, we propose a multi-modal attention module which use EHR data to help the selection of important regions during image feature extraction process conducted by traditional CNN. Moreover, we propose to incorporate multi-head machnism to gated multimodal unit (GMU) to make it able to parallelly fuse image and EHR features in different subspaces. With the help of the two modules, existing CNN architecture can be enhanced using both modalities. Experiments on predicting Glasgow outcome scale (GOS) of intracerebral hemorrhage patients and classifying Alzheimer's Disease showed the proposed method can automatically focus on task-related areas and achieve better results by making better use of image and EHR features.