 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Contamination Issues in Brain-to-Text Decoding
Dec 26, 2023



Decoding non-invasive cognitive signals to natural language has long been the goal of building practical brain-computer interfaces (BCIs). Recent major milestones have successfully decoded cognitive signals like functional Magnetic Resonance Imaging (fMRI) and electroencephalogram (EEG) into text under open vocabulary setting. However, how to split the datasets for training, validating, and testing in cognitive signal decoding task still remains controversial. In this paper, we conduct systematic analysis on current dataset splitting methods and find the existence of data contamination largely exaggerates model performance. Specifically, first we find the leakage of test subjects' cognitive signals corrupts the training of a robust encoder. Second, we prove the leakage of text stimuli causes the auto-regressive decoder to memorize information in test set. The decoder generates highly accurate text not because it truly understands cognitive signals. To eliminate the influence of data contamination and fairly evaluate different models' generalization ability, we propose a new splitting method for different types of cognitive datasets (e.g. fMRI, EEG). We also test the performance of SOTA Brain-to-Text decoding models under the proposed dataset splitting paradigm as baselines for further research.
An Incremental Update Framework for Online Recommenders with Data-Driven Prior
Dec 26, 2023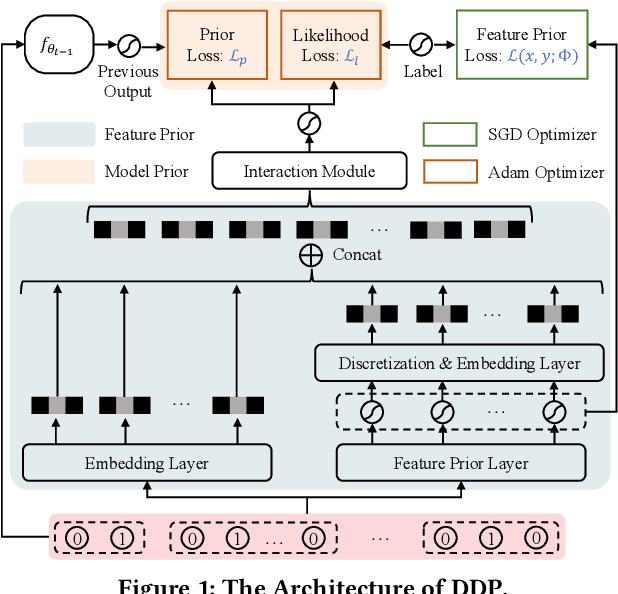
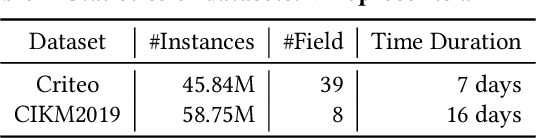
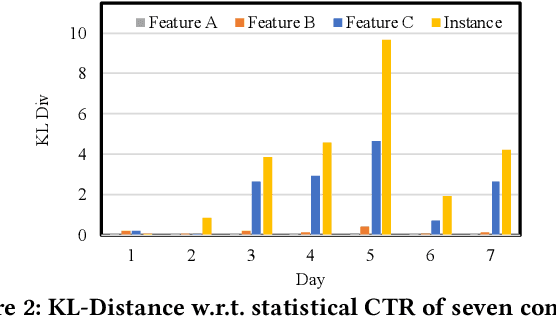
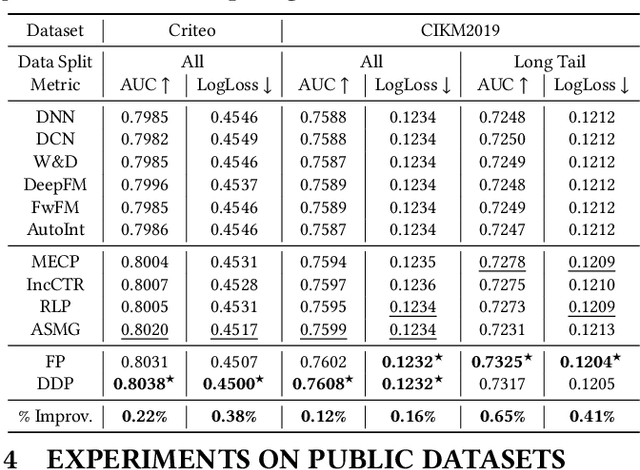
Online recommenders have attained growing interest and created great revenue for businesses. Given numerous users and items, incremental update becomes a mainstream paradigm for learning large-scale models in industrial scenarios, where only newly arrived data within a sliding window is fed into the model, meeting the strict requirements of quick response. However, this strategy would be prone to overfitting to newly arrived data. When there exists a significant drift of data distribution, the long-term information would be discarded, which harms the recommendation performance. Conventional methods address this issue through native model-based continual learning methods, without analyzing the data characteristics for online recommenders. To address the aforementioned issue, we propose an incremental update framework for online recommenders with Data-Driven Prior (DDP), which is composed of Feature Prior (FP) and Model Prior (MP). The FP performs the click estimation for each specific value to enhance the stability of the training process. The MP incorporates previous model output into the current update while strictly following the Bayes rules, resulting in a theoretically provable prior for the robust update. In this way, both the FP and MP are well integrated into the unified framework, which is model-agnostic and can accommodate various advanced interaction models. Extensive experiments on two publicly available datasets as well as an industrial dataset demonstrate the superior performance of the proposed framework.
Learning Only On Boundaries: a Physics-Informed Neural operator for Solving Parametric Partial Differential Equations in Complex Geometries
Aug 24, 2023Recently deep learning surrogates and neural operators have shown promise in solving partial differential equations (PDEs). However, they often require a large amount of training data and are limited to bounded domains. In this work, we present a novel physics-informed neural operator method to solve parametrized boundary value problems without labeled data. By reformulating the PDEs into boundary integral equations (BIEs), we can train the operator network solely on the boundary of the domain. This approach reduces the number of required sample points from $O(N^d)$ to $O(N^{d-1})$, where $d$ is the domain's dimension, leading to a significant acceleration of the training process. Additionally, our method can handle unbounded problems, which are unattainable for existing physics-informed neural networks (PINNs) and neural operators. Our numerical experiments show the effectiveness of parametrized complex geometries and unbounded problems.
Ensemble learning for Physics Informed Neural Networks: a Gradient Boosting approach
Feb 25, 2023



While the popularity of physics-informed neural networks (PINNs) is steadily rising, to this date, PINNs have not been successful in simulating multi-scale and singular perturbation problems. In this work, we present a new training paradigm referred to as "gradient boosting" (GB), which significantly enhances the performance of physics informed neural networks (PINNs). Rather than learning the solution of a given PDE using a single neural network directly, our algorithm employs a sequence of neural networks to achieve a superior outcome. This approach allows us to solve problems presenting great challenges for traditional PINNs. Our numerical experiments demonstrate the effectiveness of our algorithm through various benchmarks, including comparisons with finite element methods and PINNs. Furthermore, this work also unlocks the door to employing ensemble learning techniques in PINNs, providing opportunities for further improvement in solving PDEs.
JDRec: Practical Actor-Critic Framework for Online Combinatorial Recommender System
Jul 27, 2022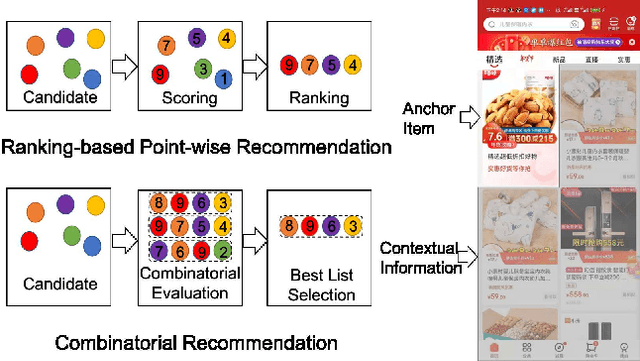

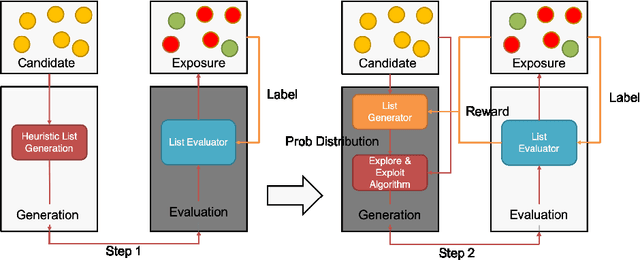

A combinatorial recommender (CR) system feeds a list of items to a user at a time in the result page, in which the user behavior is affected by both contextual information and items. The CR is formulated as a combinatorial optimization problem with the objective of maximizing the recommendation reward of the whole list. Despite its importance, it is still a challenge to build a practical CR system, due to the efficiency, dynamics, personalization requirement in online environment. In particular, we tear the problem into two sub-problems, list generation and list evaluation. Novel and practical model architectures are designed for these sub-problems aiming at jointly optimizing effectiveness and efficiency. In order to adapt to online case, a bootstrap algorithm forming an actor-critic reinforcement framework is given to explore better recommendation mode in long-term user interaction. Offline and online experiment results demonstrate the efficacy of proposed JDRec framework. JDRec has been applied in online JD recommendation, improving click through rate by 2.6% and synthetical value for the platform by 5.03%. We will publish the large-scale dataset used in this study to contribute to the research community.
Gating-adapted Wavelet Multiresolution Analysis for Exposure Sequence Modeling in CTR prediction
Apr 29, 2022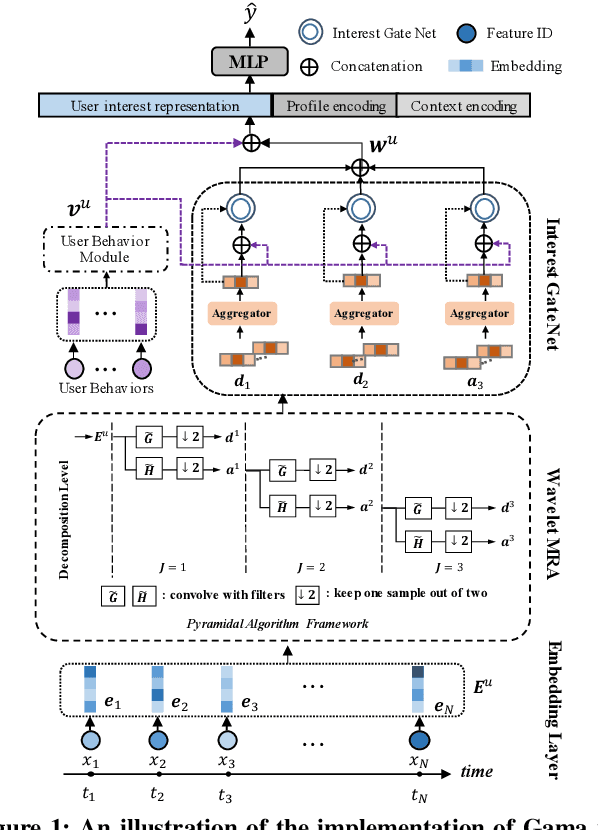

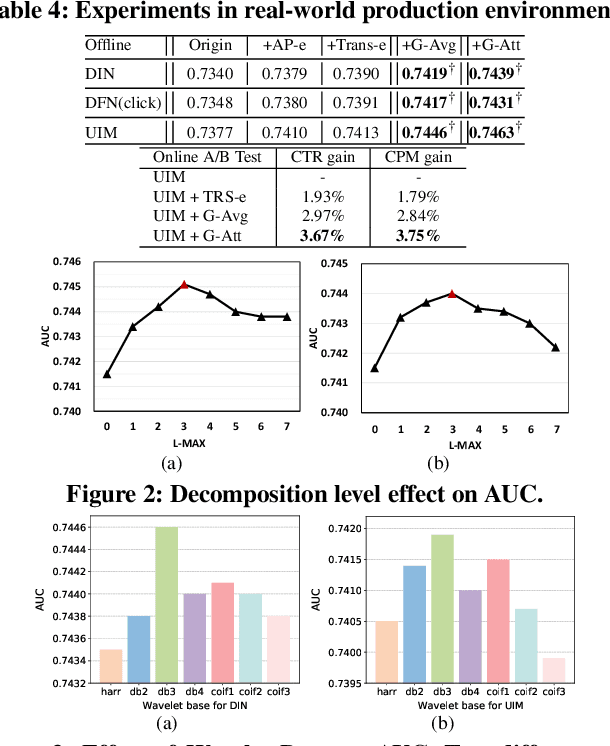
The exposure sequence is being actively studied for user interest modeling in Click-Through Rate (CTR) prediction. However, the existing methods for exposure sequence modeling bring extensive computational burden and neglect noise problems, resulting in an excessively latency and the limited performance in online recommenders. In this paper, we propose to address the high latency and noise problems via Gating-adapted wavelet multiresolution analysis (Gama), which can effectively denoise the extremely long exposure sequence and adaptively capture the implied multi-dimension user interest with linear computational complexity. This is the first attempt to integrate non-parametric multiresolution analysis technique into deep neural networks to model user exposure sequence. Extensive experiments on large scale benchmark dataset and real production dataset confirm the effectiveness of Gama for exposure sequence modeling, especially in cold-start scenarios. Benefited from its low latency and high effecitveness, Gama has been deployed in our real large-scale industrial recommender, successfully serving over hundreds of millions users.
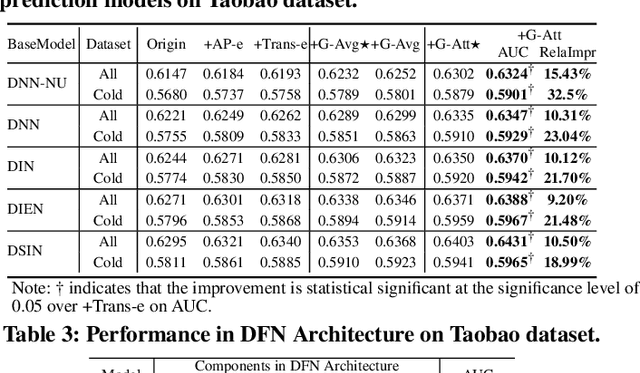
Alleviating Cold-start Problem in CTR Prediction with A Variational Embedding Learning Framework
Jan 17, 2022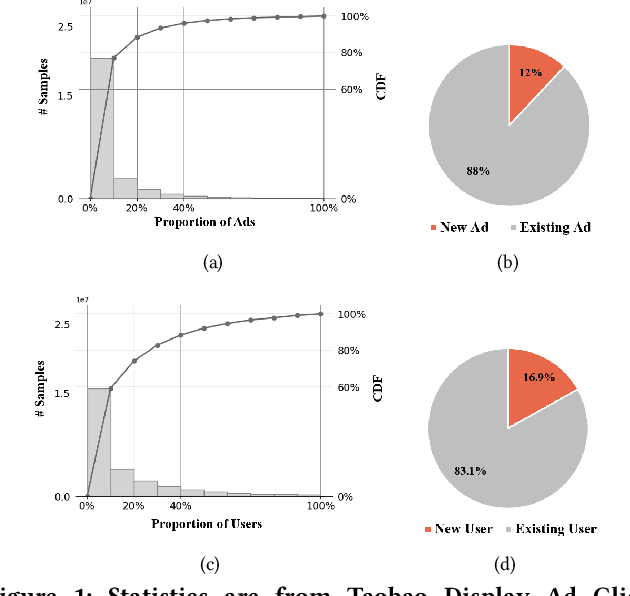

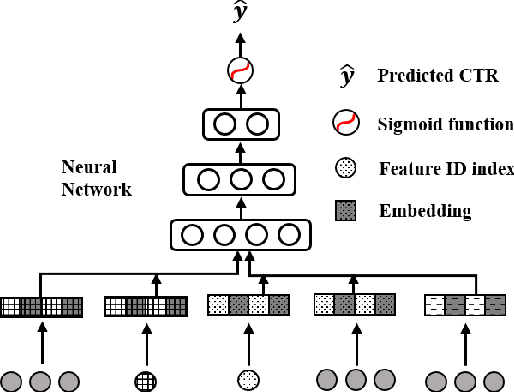
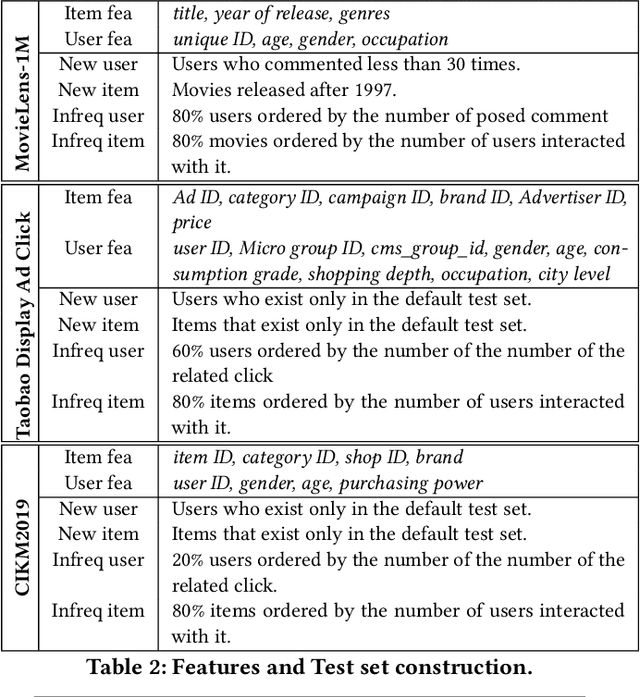
We propose a general Variational Embedding Learning Framework (VELF) for alleviating the severe cold-start problem in CTR prediction. VELF addresses the cold start problem via alleviating over-fits caused by data-sparsity in two ways: learning probabilistic embedding, and incorporating trainable and regularized priors which utilize the rich side information of cold start users and advertisements (Ads). The two techniques are naturally integrated into a variational inference framework, forming an end-to-end training process. Abundant empirical tests on benchmark datasets well demonstrate the advantages of our proposed VELF. Besides, extended experiments confirmed that our parameterized and regularized priors provide more generalization capability than traditional fixed priors.
A Physics-Informed Neural Network Framework For Partial Differential Equations on 3D Surfaces: Time-Dependent Problems
Mar 19, 2021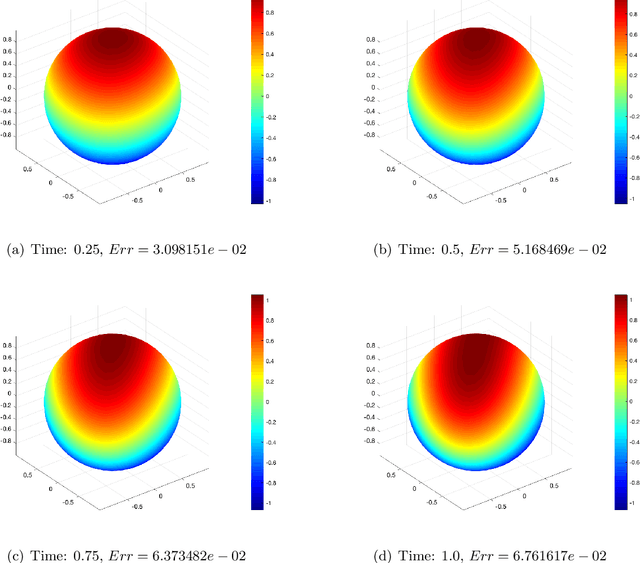
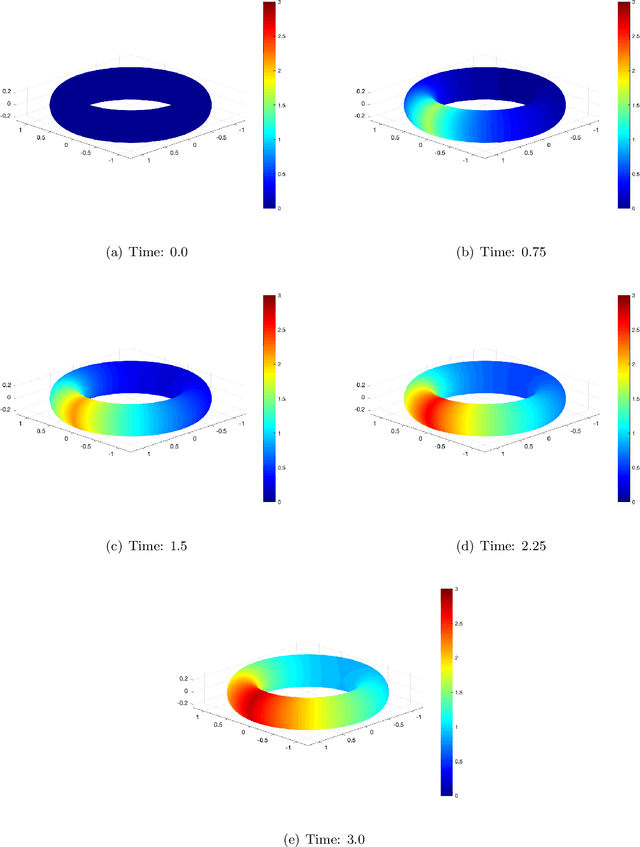
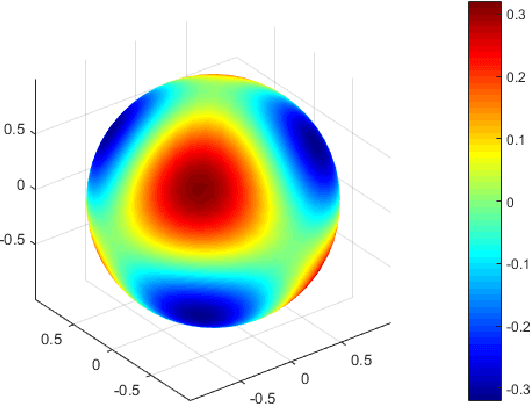
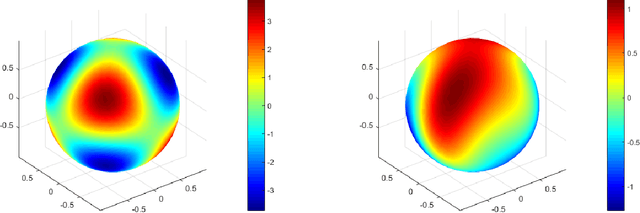
In this paper, we show a physics-informed neural network solver for the time-dependent surface PDEs. Unlike the traditional numerical solver, no extension of PDE and mesh on the surface is needed. We show a simplified prior estimate of the surface differential operators so that PINN's loss value will be an indicator of the residue of the surface PDEs. Numerical experiments verify efficacy of our algorithm.
NVIDIA SimNet^{TM}: an AI-accelerated multi-physics simulation framework
Dec 14, 2020

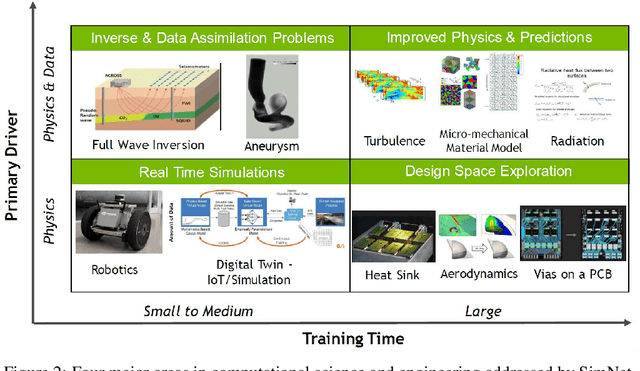

We present SimNet, an AI-driven multi-physics simulation framework, to accelerate simulations across a wide range of disciplines in science and engineering. Compared to traditional numerical solvers, SimNet addresses a wide range of use cases - coupled forward simulations without any training data, inverse and data assimilation problems. SimNet offers fast turnaround time by enabling parameterized system representation that solves for multiple configurations simultaneously, as opposed to the traditional solvers that solve for one configuration at a time. SimNet is integrated with parameterized constructive solid geometry as well as STL modules to generate point clouds. Furthermore, it is customizable with APIs that enable user extensions to geometry, physics and network architecture. It has advanced network architectures that are optimized for high-performance GPU computing, and offers scalable performance for multi-GPU and multi-Node implementation with accelerated linear algebra as well as FP32, FP64 and TF32 computations. In this paper we review the neural network solver methodology, the SimNet architecture, and the various features that are needed for effective solution of the PDEs. We present real-world use cases that range from challenging forward multi-physics simulations with turbulence and complex 3D geometries, to industrial design optimization and inverse problems that are not addressed efficiently by the traditional solvers. Extensive comparisons of SimNet results with open source and commercial solvers show good correlation.
Dual Attention Network for Scene Segmentation
Sep 16, 2018

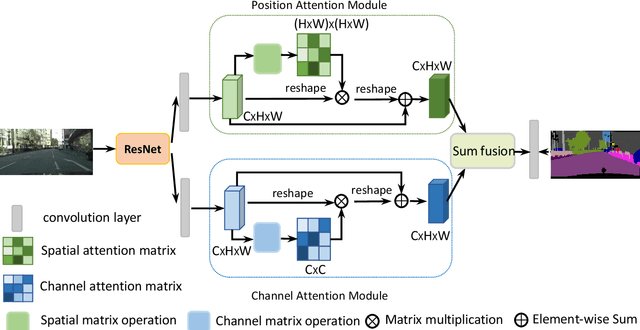
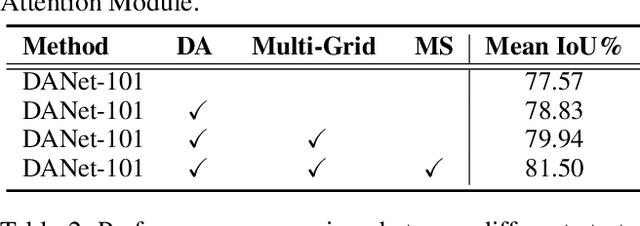
In this paper, we address the scene segmentation task by capturing rich contextual dependencies based on the selfattention mechanism. Unlike previous works that capture contexts by multi-scale features fusion, we propose a Dual Attention Networks (DANet) to adaptively integrate local features with their global dependencies. Specifically, we append two types of attention modules on top of traditional dilated FCN, which model the semantic interdependencies in spatial and channel dimensions respectively. The position attention module selectively aggregates the features at each position by a weighted sum of the features at all positions. Similar features would be related to each other regardless of their distances. Meanwhile, the channel attention module selectively emphasizes interdependent channel maps by integrating associated features among all channel maps. We sum the outputs of the two attention modules to further improve feature representation which contributes to more precise segmentation results. We achieve new state-of-the-art segmentation performance on three challenging scene segmentation datasets, i.e., Cityscapes, PASCAL Context and COCO Stuff dataset. In particular, a Mean IoU score of 81.5% on Cityscapes test set is achieved without using coarse data. We make the code and trained model publicly available at https://github.com/junfu1115/DANet