 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIND: Unified Inquiry and Diagnosis RL with Criteria Grounded Clinical Supports for Psychiatric Consultation
Mar 04, 2026Large language models (LLMs) have advanced medical dialogue systems, yet psychiatric consultation poses substantially higher demands due to subjective ambiguity and comorbidity complexity: an agent must continuously extract psychopathological cues from incomplete and inconsistent patient reports in multi-turn interactions and perform rigorous differential diagnostic reasoning. However, existing methods face two fundamental challenges. First, without criteria-grounded clinical supports, they are prone to unsupported clinical assertions when symptoms are atypical or underspecified. Second, in multi-turn interactions, they struggle to mitigate inquiry drift (off-topic or low-yield questioning) and optimize questioning strategies. To address these challenges, we propose MIND, a unified inquiry--diagnosis reinforcement learning framework for psychiatric consultation. Specifically, we build a Criteria-Grounded Psychiatric Reasoning Bank (PRB) that summarizes dialogue context into clinical retrieval states, retrieves semantically similar reference consultations, and distills reusable criteria-grounded clinical supports to guide criteria-aligned inquiry and reasoning. Building on this foundation, MIND enforces explicit clinical reasoning with rubric-based process rewards to provide fine-grained supervision over intermediate decision steps, and incorporates a value-aware trajectory rectification mechanism to jointly improve information acquisition and diagnostic decision-making across turns. Extensive experiments demonstrate that MIND consistently outperforms strong baselines in diagnostic accuracy, empathetic interaction quality, interpretability, and generalization.
LingxiDiagBench: A Multi-Agent Framework for Benchmarking LLMs in Chinese Psychiatric Consultation and Diagnosis
Feb 11, 2026Mental disorders are highly prevalent worldwide, but the shortage of psychiatrists and the inherent subjectivity of interview-based diagnosis create substantial barriers to timely and consistent mental-health assessment. Progress in AI-assisted psychiatric diagnosis is constrained by the absence of benchmarks that simultaneously provide realistic patient simulation, clinician-verified diagnostic labels, and support for dynamic multi-turn consultation. We present LingxiDiagBench, a large-scale multi-agent benchmark that evaluates LLMs on both static diagnostic inference and dynamic multi-turn psychiatric consultation in Chinese. At its core is LingxiDiag-16K, a dataset of 16,000 EMR-aligned synthetic consultation dialogues designed to reproduce real clinical demographic and diagnostic distributions across 12 ICD-10 psychiatric categories. Through extensive experiments across state-of-the-art LLMs, we establish key findings: (1) although LLMs achieve high accuracy on binary depression--anxiety classification (up to 92.3%), performance deteriorates substantially for depression--anxiety comorbidity recognition (43.0%) and 12-way differential diagnosis (28.5%); (2) dynamic consultation often underperforms static evaluation, indicating that ineffective information-gathering strategies significantly impair downstream diagnostic reasoning; (3) consultation quality assessed by LLM-as-a-Judge shows only moderate correlation with diagnostic accuracy, suggesting that well-structured questioning alone does not ensure correct diagnostic decisions. We release LingxiDiag-16K and the full evaluation framework to support reproducible research at https://github.com/Lingxi-mental-health/LingxiDiagBench.
MDD-5k: A New Diagnostic Conversation Dataset for Mental Disorders Synthesized via Neuro-Symbolic LLM Agents
Aug 22, 2024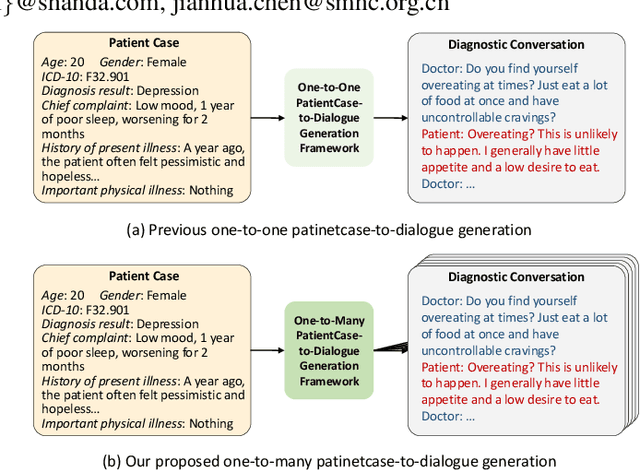

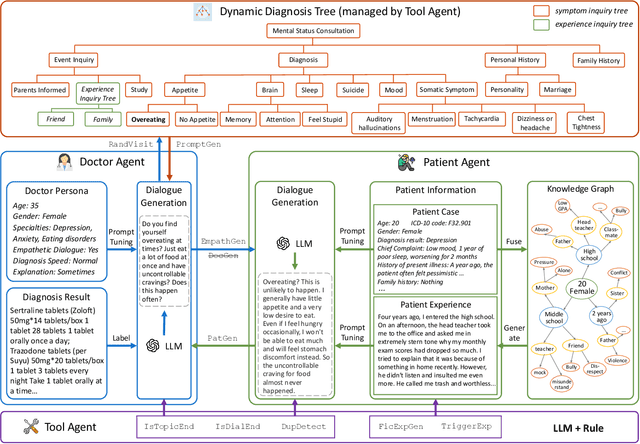

The clinical diagnosis of most mental disorders primarily relies on the conversations between psychiatrist and patient. The creation of such diagnostic conversation datasets is promising to boost the AI mental healthcare community. However, directly collecting the conversations in real diagnosis scenarios is near impossible due to stringent privacy and ethical considerations. To address this issue, we seek to synthesize diagnostic conversation by exploiting anonymous patient cases that are easier to access. Specifically, we design a neuro-symbolic multi-agent framework for synthesizing the diagnostic conversation of mental disorders with large language models. It takes patient case as input and is capable of generating multiple diverse conversations with one single patient case. The framework basically involves the interaction between a doctor agent and a patient agent, and achieves text generation under symbolic control via a dynamic diagnosis tree from a tool agent. By applying the proposed framework, we develop the largest Chinese mental disorders diagnosis dataset MDD-5k, which is built upon 1000 cleaned real patient cases by cooperating with a pioneering psychiatric hospital, and contains 5000 high-quality long conversations with diagnosis results as labels. To the best of our knowledge, it's also the first labelled Chinese mental disorders diagnosis dataset. Human evaluation demonstrates the proposed MDD-5k dataset successfully simulates human-like diagnostic process of mental disorders. The dataset and code will become publicly accessible in https://github.com/lemonsis/MDD-5k.
Generalised Latent Assimilation in Heterogeneous Reduced Spaces with Machine Learning Surrogate Models
Apr 08, 2022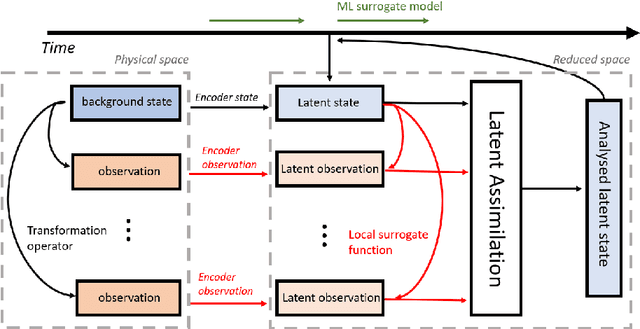
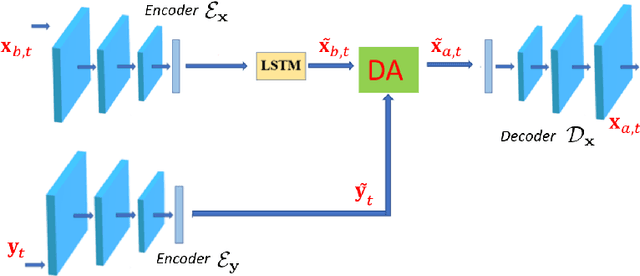

Reduced-order modelling and low-dimensional surrogate models generated using machine learning algorithms have been widely applied in high-dimensional dynamical systems to improve the algorithmic efficiency. In this paper, we develop a system which combines reduced-order surrogate models with a novel data assimilation (DA) technique used to incorporate real-time observations from different physical spaces. We make use of local smooth surrogate functions which link the space of encoded system variables and the one of current observations to perform variational DA with a low computational cost. The new system, named Generalised Latent Assimilation can benefit both the efficiency provided by the reduced-order modelling and the accuracy of data assimilation. A theoretical analysis of the difference between surrogate and original assimilation cost function is also provided in this paper where an upper bound, depending on the size of the local training set, is given. The new approach is tested on a high-dimensional CFD application of a two-phase liquid flow with non-linear observation operators that current Latent Assimilation methods can not handle. Numerical results demonstrate that the proposed assimilation approach can significantly improve the reconstruction and prediction accuracy of the deep learning surrogate model which is nearly 1000 times faster than the CFD simulation.
Predicting Louisiana Public High School Dropout through Imbalanced Learning Techniques
Oct 29, 2019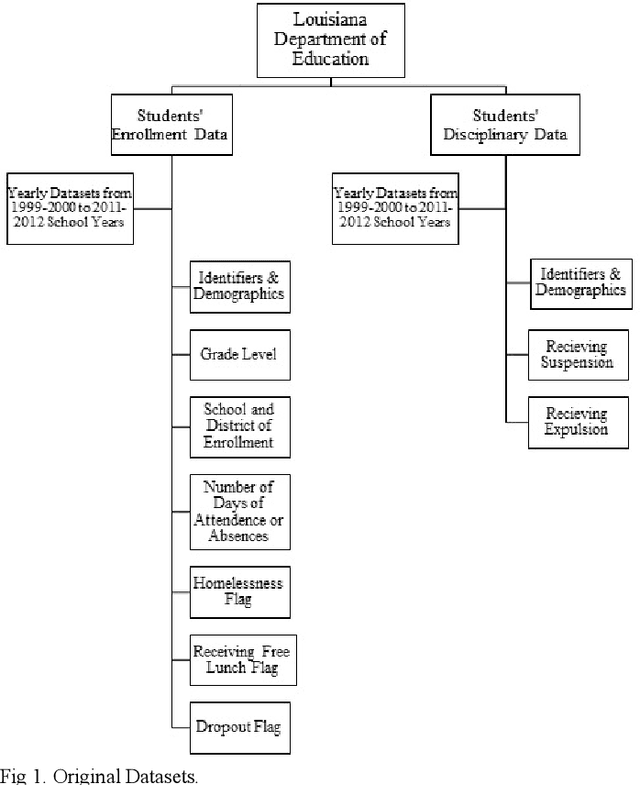
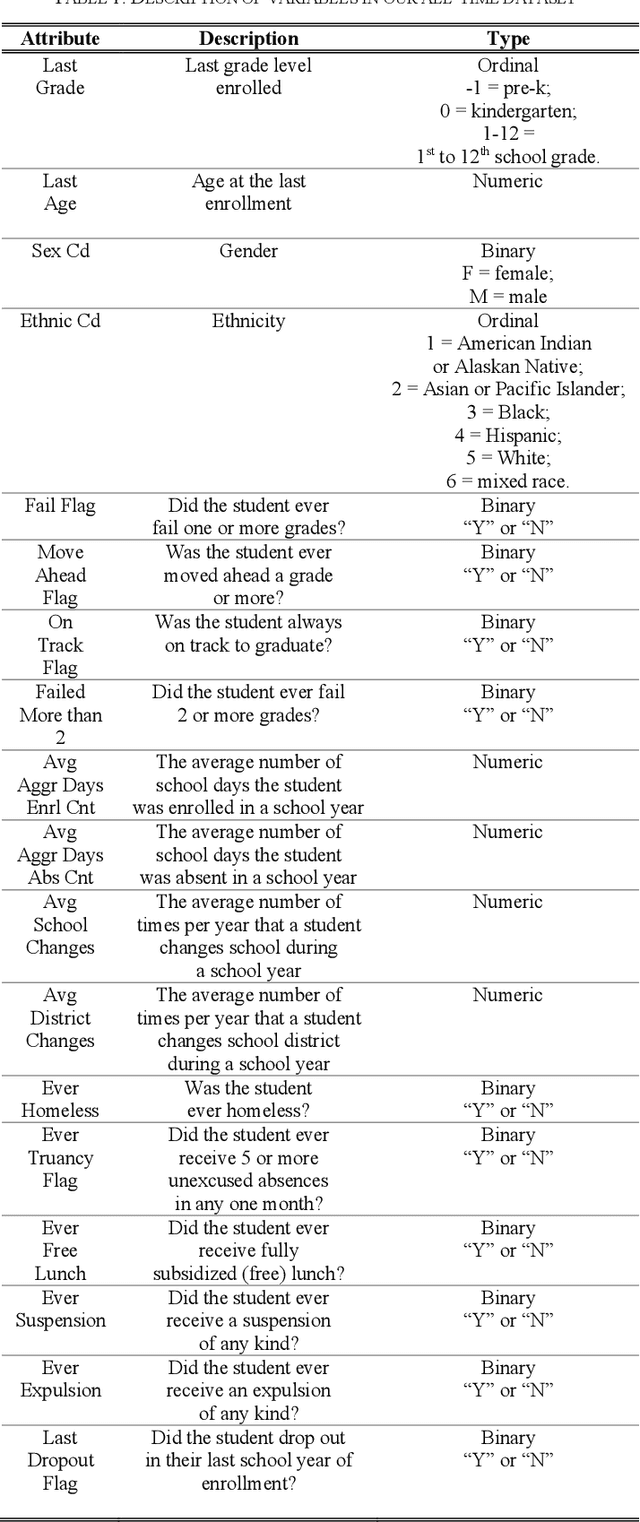
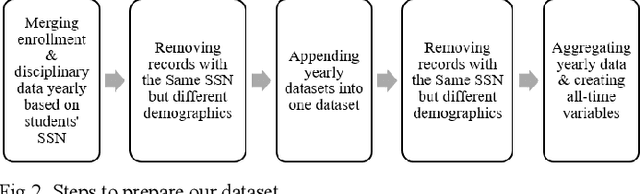
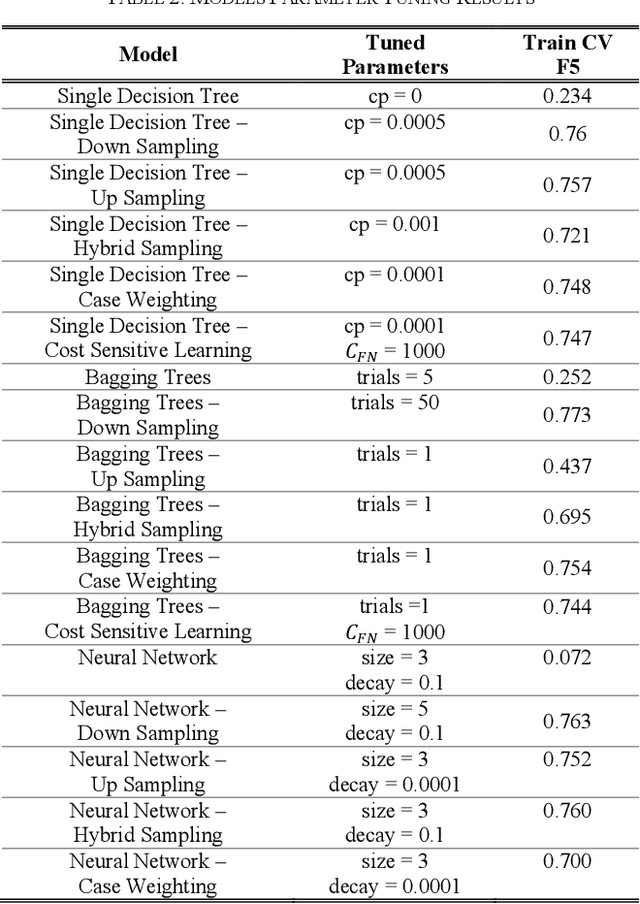
This study is motivated by the magnitude of the problem of Louisiana high school dropout and its negative impacts on individual and public well-being. Our goal is to predict students who are at risk of high school dropout, by examining Louisiana administrative dataset. Due to the imbalanced nature of the dataset, imbalanced learning techniques including resampling, case weighting, and cost-sensitive learning have been applied to enhance the prediction performance on the rare class. Performance metrics used in this study are F-measure, recall and precision of the rare class. We compare the performance of several machine learning algorithms such as neural networks, decision trees and bagging trees in combination with the imbalanced learning approaches using an administrative dataset of size of 366k+ from Louisiana Department of Education. Experiments show that application of imbalanced learning methods produces good results on recall but decreases precision, whereas base classifiers without regard of imbalanced data handling gives better precision but poor recall. Overall application of imbalanced learning techniques is beneficial, yet more studies are desired to improve precision.
Multimodal Classification with Deep Convolutional-Recurrent Neural Networks for Electroencephalography
Jul 24, 2018



Electroencephalography (EEG) has become the most significant input signal for brain computer interface (BCI) based systems. However, it is very difficult to obtain satisfactory classification accuracy due to traditional methods can not fully exploit multimodal information. Herein, we propose a novel approach to modeling cognitive events from EEG data by reducing it to a video classification problem, which is designed to preserve the multimodal information of EEG. In addition, optical flow is introduced to represent the variant information of EEG. We train a deep neural network (DNN) with convolutional neural network (CNN) and recurrent neural network (RNN) for the EEG classification task by using EEG video and optical flow. The experiments demonstrate that our approach has many advantages, such as more robustness and more accuracy in EEG classification tasks. According to our approach, we designed a mixed BCI-based rehabilitation support system to help stroke patients perform some basic operations.
* 10 pages, 6 figures