 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Louisiana Public High School Dropout through Imbalanced Learning Techniques
Oct 29, 2019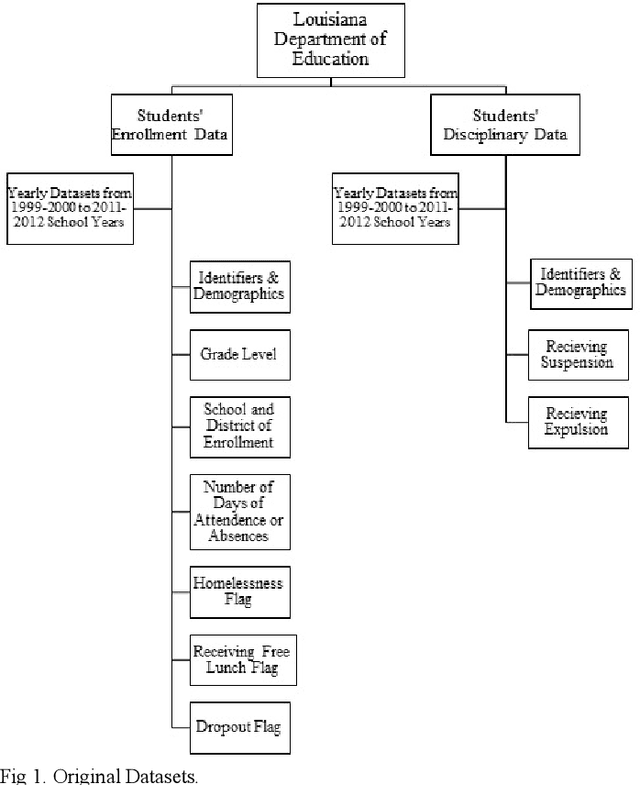
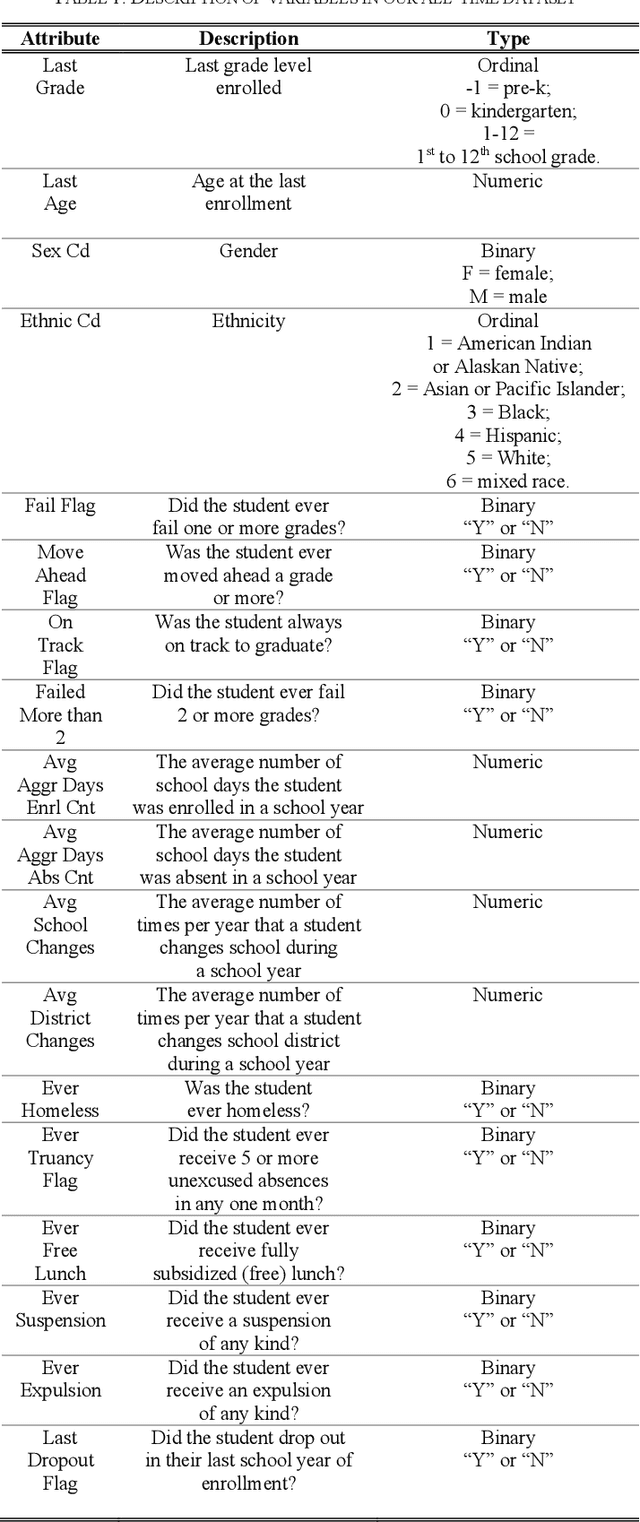
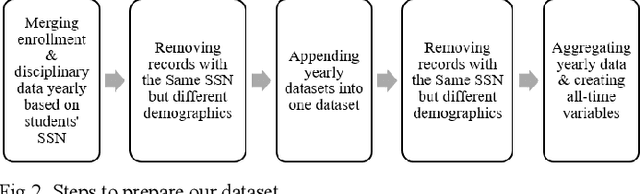
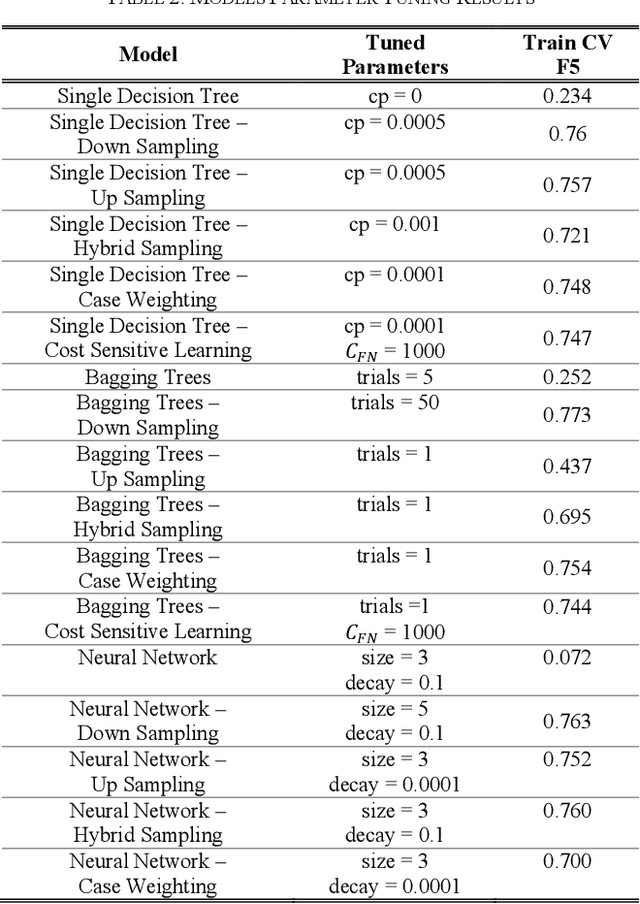
This study is motivated by the magnitude of the problem of Louisiana high school dropout and its negative impacts on individual and public well-being. Our goal is to predict students who are at risk of high school dropout, by examining Louisiana administrative dataset. Due to the imbalanced nature of the dataset, imbalanced learning techniques including resampling, case weighting, and cost-sensitive learning have been applied to enhance the prediction performance on the rare class. Performance metrics used in this study are F-measure, recall and precision of the rare class. We compare the performance of several machine learning algorithms such as neural networks, decision trees and bagging trees in combination with the imbalanced learning approaches using an administrative dataset of size of 366k+ from Louisiana Department of Education. Experiments show that application of imbalanced learning methods produces good results on recall but decreases precision, whereas base classifiers without regard of imbalanced data handling gives better precision but poor recall. Overall application of imbalanced learning techniques is beneficial, yet more studies are desired to improve precision.