 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Video Moment Retrieval with Point-Level Supervision
Paper and Code
May 23, 2023


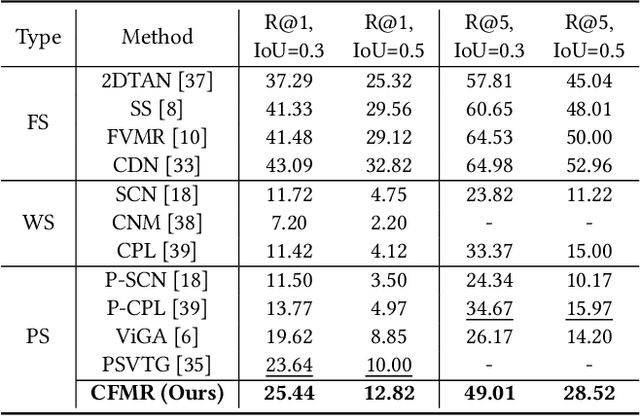
Video Moment Retrieval (VMR) aims at retrieving the most relevant events from an untrimmed video with natural language queries. Existing VMR methods suffer from two defects: (1) massive expensive temporal annotations are required to obtain satisfying performance; (2) complicated cross-modal interaction modules are deployed, which lead to high computational cost and low efficiency for the retrieval process. To address these issues, we propose a novel method termed Cheaper and Faster Moment Retrieval (CFMR), which well balances the retrieval accuracy, efficiency, and annotation cost for VMR. Specifically, our proposed CFMR method learns from point-level supervision where each annotation is a single frame randomly located within the target moment. It is 6 times cheaper than the conventional annotations of event boundaries. Furthermore, we also design a concept-based multimodal alignment mechanism to bypass the usage of cross-modal interaction modules during the inference process, remarkably improving retrieval efficiency. The experimental results on three widely used VMR benchmarks demonstrate the proposed CFMR method establishes new state-of-the-art with point-level supervision. Moreover, it significantly accelerates the retrieval speed with more than 100 times FLOPs compared to existing approaches with point-level supervision.