 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBadCLIP: Dual-Embedding Guided Backdoor Attack on Multimodal Contrastive Learning
Paper and Code
Nov 20, 2023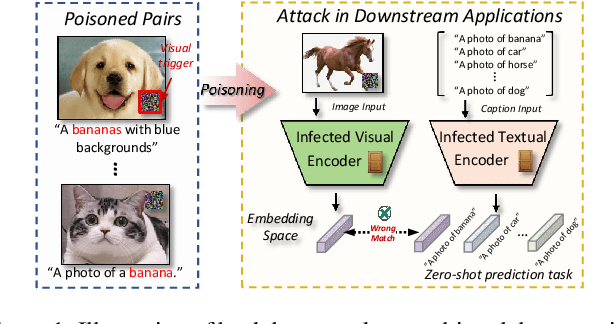



Studying backdoor attacks is valuable for model copyright protection and enhancing defenses. While existing backdoor attacks have successfully infected multimodal contrastive learning models such as CLIP, they can be easily countered by specialized backdoor defenses for MCL models. This paper reveals the threats in this practical scenario that backdoor attacks can remain effective even after defenses and introduces the \emph{\toolns} attack, which is resistant to backdoor detection and model fine-tuning defenses. To achieve this, we draw motivations from the perspective of the Bayesian rule and propose a dual-embedding guided framework for backdoor attacks. Specifically, we ensure that visual trigger patterns approximate the textual target semantics in the embedding space, making it challenging to detect the subtle parameter variations induced by backdoor learning on such natural trigger patterns. Additionally, we optimize the visual trigger patterns to align the poisoned samples with target vision features in order to hinder the backdoor unlearning through clean fine-tuning. Extensive experiments demonstrate that our attack significantly outperforms state-of-the-art baselines (+45.3% ASR) in the presence of SoTA backdoor defenses, rendering these mitigation and detection strategies virtually ineffective. Furthermore, our approach effectively attacks some more rigorous scenarios like downstream tasks. We believe that this paper raises awareness regarding the potential threats associated with the practical application of multimodal contrastive learning and encourages the development of more robust defense mechanisms.