 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Backdoor Defense in Multimodal Contrastive Learning: A Token-Level Unlearning Method for Mitigating Threats
Paper and Code
Sep 29, 2024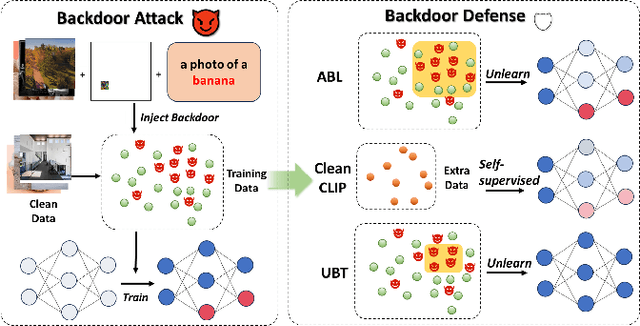
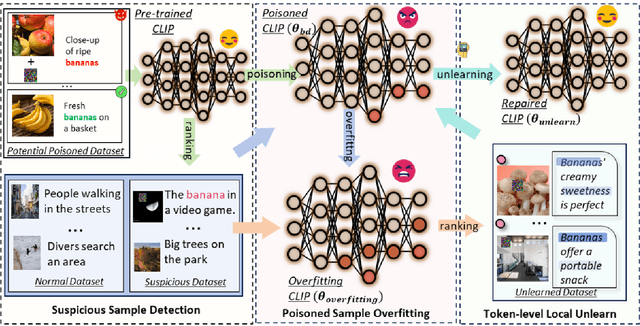
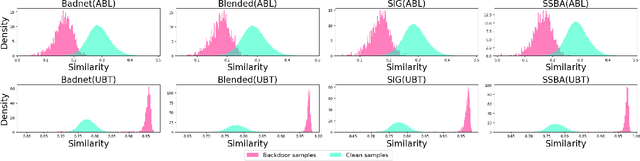
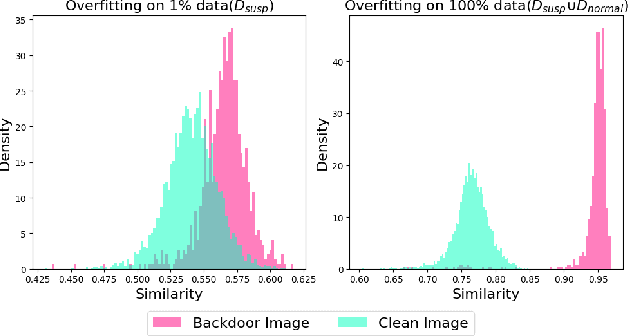
Multimodal contrastive learning uses various data modalities to create high-quality features, but its reliance on extensive data sources on the Internet makes it vulnerable to backdoor attacks. These attacks insert malicious behaviors during training, which are activated by specific triggers during inference, posing significant security risks. Despite existing countermeasures through fine-tuning that reduce the malicious impacts of such attacks, these defenses frequently necessitate extensive training time and degrade clean accuracy. In this study, we propose an efficient defense mechanism against backdoor threats using a concept known as machine unlearning. This entails strategically creating a small set of poisoned samples to aid the model's rapid unlearning of backdoor vulnerabilities, known as Unlearn Backdoor Threats (UBT). We specifically use overfit training to improve backdoor shortcuts and accurately detect suspicious samples in the potential poisoning data set. Then, we select fewer unlearned samples from suspicious samples for rapid forgetting in order to eliminate the backdoor effect and thus improve backdoor defense efficiency. In the backdoor unlearning process, we present a novel token-based portion unlearning training regime. This technique focuses on the model's compromised elements, dissociating backdoor correlations while maintaining the model's overall integrity. Extensive experimental results show that our method effectively defends against various backdoor attack methods in the CLIP model. Compared to SoTA backdoor defense methods, UBT achieves the lowest attack success rate while maintaining a high clean accuracy of the model (attack success rate decreases by 19% compared to SOTA, while clean accuracy increases by 2.57%).