 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerging Smarter, Generalizing Better: Enhancing Model Merging on OOD Data
Jun 10, 2025Multi-task learning (MTL) concurrently trains a model on diverse task datasets to exploit common features, thereby improving overall performance across the tasks. Recent studies have dedicated efforts to merging multiple independent model parameters into a unified model for MTL, thus circumventing the need for training data and expanding the scope of applicable scenarios of MTL. However, current approaches to model merging predominantly concentrate on enhancing performance within in-domain (ID) datasets, often overlooking their efficacy on out-of-domain (OOD) datasets. In this work, we proposed LwPTV (Layer-wise Pruning Task Vector) by building a saliency score, measuring the redundancy of parameters in task vectors. Designed in this way ours can achieve mask vector for each task and thus perform layer-wise pruning on the task vectors, only keeping the pre-trained model parameters at the corresponding layer in merged model. Owing to its flexibility, our method can be seamlessly integrated with most of existing model merging methods to improve their performance on OOD tasks. Extensive experiments demonstrate that the application of our method results in substantial enhancements in OOD performance while preserving the ability on ID tasks.
FedAWA: Adaptive Optimization of Aggregation Weights in Federated Learning Using Client Vectors
Mar 20, 2025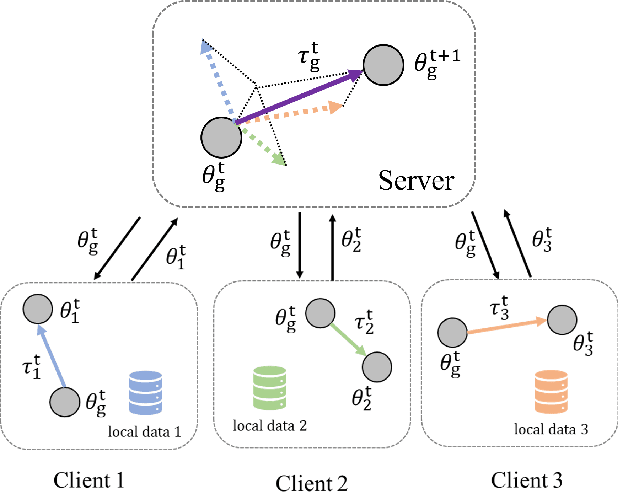
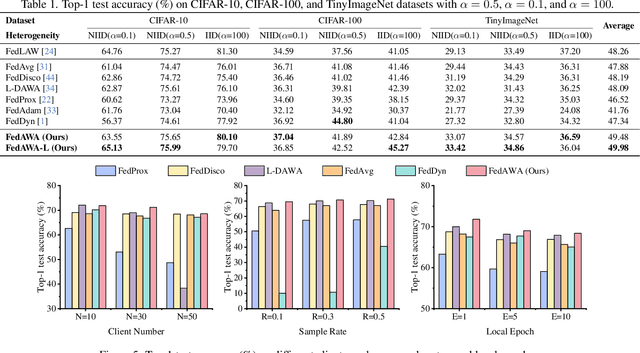
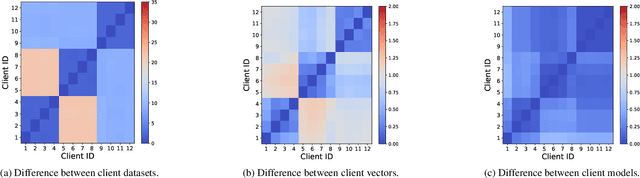
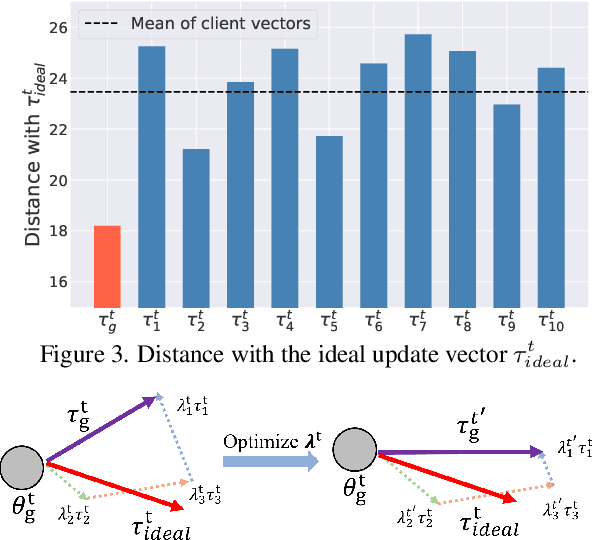
Federated Learning (FL) has emerged as a promising framework for distributed machine learning, enabling collaborative model training without sharing local data, thereby preserving privacy and enhancing security. However, data heterogeneity resulting from differences across user behaviors, preferences, and device characteristics poses a significant challenge for federated learning. Most previous works overlook the adjustment of aggregation weights, relying solely on dataset size for weight assignment, which often leads to unstable convergence and reduced model performance. Recently, several studies have sought to refine aggregation strategies by incorporating dataset characteristics and model alignment. However, adaptively adjusting aggregation weights while ensuring data security-without requiring additional proxy data-remains a significant challenge. In this work, we propose Federated learning with Adaptive Weight Aggregation (FedAWA), a novel method that adaptively adjusts aggregation weights based on client vectors during the learning process. The client vector captures the direction of model updates, reflecting local data variations, and is used to optimize the aggregation weight without requiring additional datasets or violating privacy. By assigning higher aggregation weights to local models whose updates align closely with the global optimization direction, FedAWA enhances the stability and generalization of the global model. Extensive experiments under diverse scenarios demonstrate the superiority of our method, providing a promising solution to the challenges of data heterogeneity in federated learning.
FedLWS: Federated Learning with Adaptive Layer-wise Weight Shrinking
Mar 19, 2025In Federated Learning (FL), weighted aggregation of local models is conducted to generate a new global model, and the aggregation weights are typically normalized to 1. A recent study identifies the global weight shrinking effect in FL, indicating an enhancement in the global model's generalization when the sum of weights (i.e., the shrinking factor) is smaller than 1, where how to learn the shrinking factor becomes crucial. However, principled approaches to this solution have not been carefully studied from the adequate consideration of privacy concerns and layer-wise distinctions. To this end, we propose a novel model aggregation strategy, Federated Learning with Adaptive Layer-wise Weight Shrinking (FedLWS), which adaptively designs the shrinking factor in a layer-wise manner and avoids optimizing the shrinking factors on a proxy dataset. We initially explored the factors affecting the shrinking factor during the training process. Then we calculate the layer-wise shrinking factors by considering the distinctions among each layer of the global model. FedLWS can be easily incorporated with various existing methods due to its flexibility. Extensive experiments under diverse scenarios demonstrate the superiority of our method over several state-of-the-art approaches, providing a promising tool for enhancing the global model in FL.