 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Clean and Balanced Subset for Noisy Long-tailed Classification
Paper and Code
Apr 10, 2024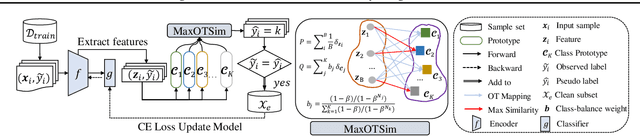
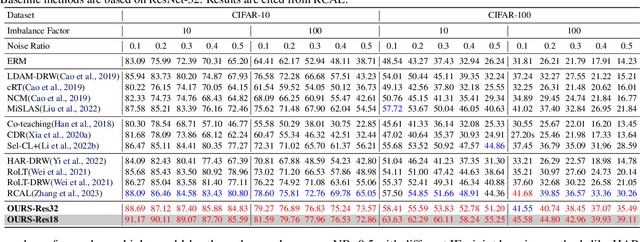
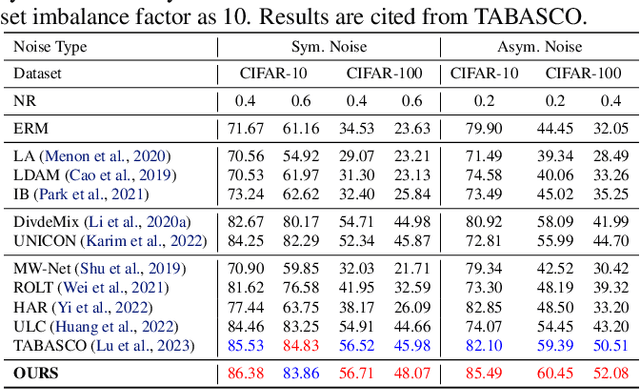
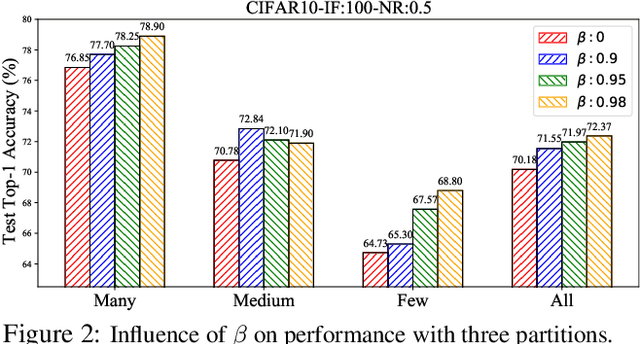
Real-world datasets usually are class-imbalanced and corrupted by label noise. To solve the joint issue of long-tailed distribution and label noise, most previous works usually aim to design a noise detector to distinguish the noisy and clean samples. Despite their effectiveness, they may be limited in handling the joint issue effectively in a unified way. In this work, we develop a novel pseudo labeling method using class prototypes from the perspective of distribution matching, which can be solved with optimal transport (OT). By setting a manually-specific probability measure and using a learned transport plan to pseudo-label the training samples, the proposed method can reduce the side-effects of noisy and long-tailed data simultaneously. Then we introduce a simple yet effective filter criteria by combining the observed labels and pseudo labels to obtain a more balanced and less noisy subset for a robust model training. Extensive experiments demonstrate that our method can extract this class-balanced subset with clean labels, which brings effective performance gains for long-tailed classification with label noise.