 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgepTSE-T: Presentation Target Speaker Extraction using Unaligned Text Cues
Nov 05, 2024



TSE aims to extract the clean speech of the target speaker in an audio mixture, thus eliminating irrelevant background noise and speech. While prior work has explored various auxiliary cues including pre-recorded speech, visual information (e.g., lip motions and gestures), and spatial information, the acquisition and selection of such strong cues are infeasible in many practical scenarios. Unlike all existing work, in this paper, we condition the TSE algorithm on semantic cues extracted from limited and unaligned text content, such as condensed points from a presentation slide. This method is particularly useful in scenarios like meetings, poster sessions, or lecture presentations, where acquiring other cues in real-time is challenging. To this end, we design two different networks. Specifically, our proposed TPE fuses audio features with content-based semantic cues to facilitate time-frequency mask generation to filter out extraneous noise, while another proposal, namely TSR, employs the contrastive learning technique to associate blindly separated speech signals with semantic cues. The experimental results show the efficacy in accurately identifying the target speaker by utilizing semantic cues derived from limited and unaligned text, resulting in SI-SDRi of 12.16 dB, SDRi of 12.66 dB, PESQi of 0.830 and STOIi of 0.150, respectively. Dataset and source code will be publicly available. Project demo page: https://slideTSE.github.io/.
Boosting Multi-Modal E-commerce Attribute Value Extraction via Unified Learning Scheme and Dynamic Range Minimization
Jul 15, 2022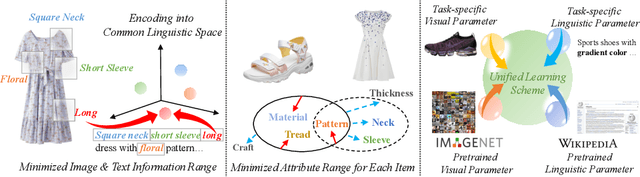
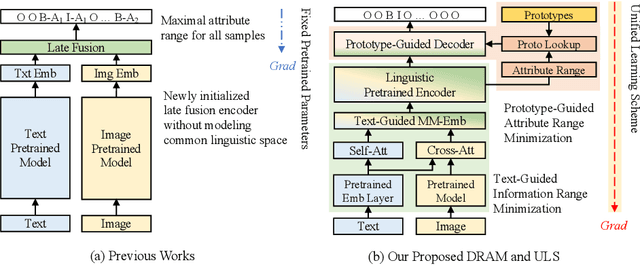
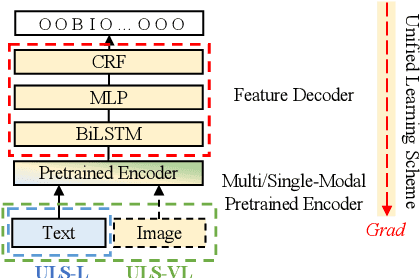

With the prosperity of e-commerce industry, various modalities, e.g., vision and language, are utilized to describe product items. It is an enormous challenge to understand such diversified data, especially via extracting the attribute-value pairs in text sequences with the aid of helpful image regions. Although a series of previous works have been dedicated to this task, there remain seldomly investigated obstacles that hinder further improvements: 1) Parameters from up-stream single-modal pretraining are inadequately applied, without proper jointly fine-tuning in a down-stream multi-modal task. 2) To select descriptive parts of images, a simple late fusion is widely applied, regardless of priori knowledge that language-related information should be encoded into a common linguistic embedding space by stronger encoders. 3) Due to diversity across products, their attribute sets tend to vary greatly, but current approaches predict with an unnecessary maximal range and lead to more potential false positives. To address these issues, we propose in this paper a novel approach to boost multi-modal e-commerce attribute value extraction via unified learning scheme and dynamic range minimization: 1) Firstly, a unified scheme is designed to jointly train a multi-modal task with pretrained single-modal parameters. 2) Secondly, a text-guided information range minimization method is proposed to adaptively encode descriptive parts of each modality into an identical space with a powerful pretrained linguistic model. 3) Moreover, a prototype-guided attribute range minimization method is proposed to first determine the proper attribute set of the current product, and then select prototypes to guide the prediction of the chosen attributes. Experiments on the popular multi-modal e-commerce benchmarks show that our approach achieves superior performance over the other state-of-the-art techniques.