 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHA-FGOVD: Highlighting Fine-grained Attributes via Explicit Linear Composition for Open-Vocabulary Object Detection
Paper and Code
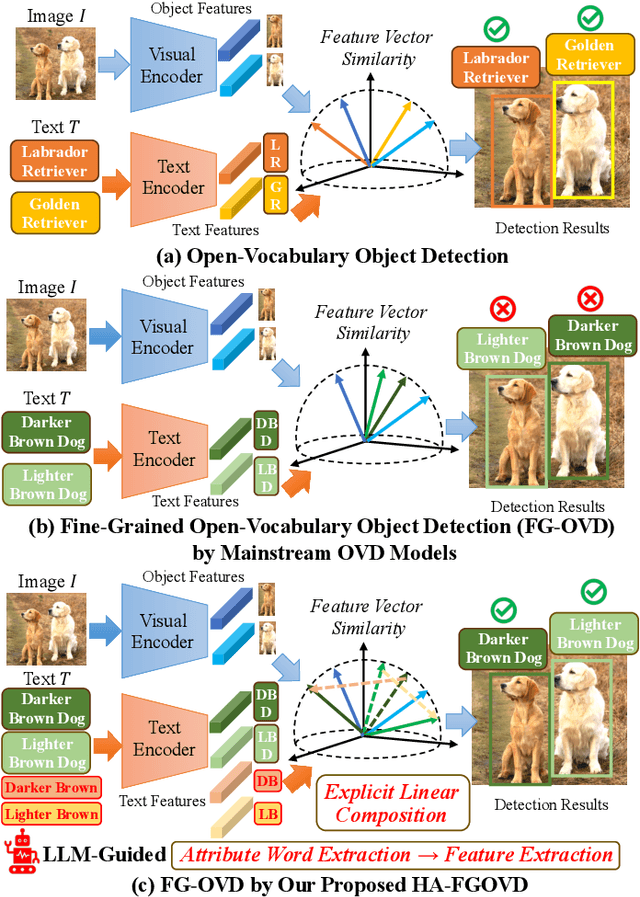
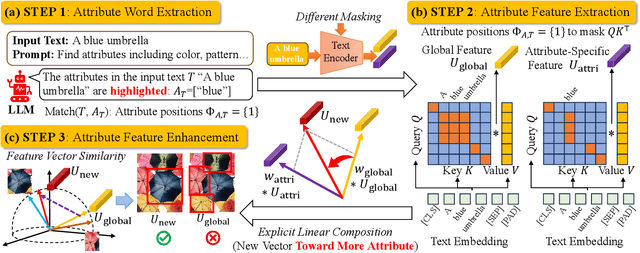

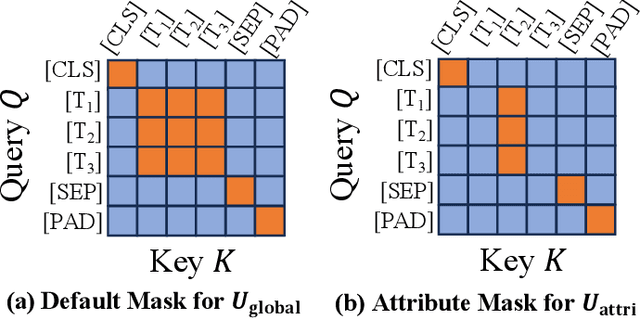
Open-vocabulary object detection (OVD) models are considered to be Large Multi-modal Models (LMM), due to their extensive training data and a large number of parameters. Mainstream OVD models prioritize object coarse-grained category rather than focus on their fine-grained attributes, e.g., colors or materials, thus failed to identify objects specified with certain attributes. However, OVD models are pretrained on large-scale image-text pairs with rich attribute words, whose latent feature space can represent the global text feature as a linear composition of fine-grained attribute tokens without highlighting them. Therefore, we propose in this paper a universal and explicit approach for frozen mainstream OVD models that boosts their attribute-level detection capabilities by highlighting fine-grained attributes in explicit linear space. Firstly, a LLM is leveraged to highlight attribute words within the input text as a zero-shot prompted task. Secondly, by strategically adjusting the token masks, the text encoders of OVD models extract both global text and attribute-specific features, which are then explicitly composited as two vectors in linear space to form the new attribute-highlighted feature for detection tasks, where corresponding scalars are hand-crafted or learned to reweight both two vectors. Notably, these scalars can be seamlessly transferred among different OVD models, which proves that such an explicit linear composition is universal. Empirical evaluation on the FG-OVD dataset demonstrates that our proposed method uniformly improves fine-grained attribute-level OVD of various mainstream models and achieves new state-of-the-art performance.