 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStepORLM: A Self-Evolving Framework With Generative Process Supervision For Operations Research Language Models
Sep 26, 2025Large Language Models (LLMs) have shown promising capabilities for solving Operations Research (OR) problems. While reinforcement learning serves as a powerful paradigm for LLM training on OR problems, existing works generally face two key limitations. First, outcome reward suffers from the credit assignment problem, where correct final answers can reinforce flawed reasoning. Second, conventional discriminative process supervision is myopic, failing to evaluate the interdependent steps of OR modeling holistically. To this end, we introduce StepORLM, a novel self-evolving framework with generative process supervision. At its core, StepORLM features a co-evolutionary loop where a policy model and a generative process reward model (GenPRM) iteratively improve on each other. This loop is driven by a dual-feedback mechanism: definitive, outcome-based verification from an external solver, and nuanced, holistic process evaluation from the GenPRM. The combined signal is used to align the policy via Weighted Direct Preference Optimization (W-DPO) and simultaneously refine the GenPRM. Our resulting 8B-parameter StepORLM establishes a new state-of-the-art across six benchmarks, significantly outperforming vastly larger generalist models, agentic methods, and specialized baselines. Moreover, the co-evolved GenPRM is able to act as a powerful and universally applicable process verifier, substantially boosting the inference scaling performance of both our own model and other existing LLMs.
Auto-Formulating Dynamic Programming Problems with Large Language Models
Jul 15, 2025Dynamic programming (DP) is a fundamental method in operations research, but formulating DP models has traditionally required expert knowledge of both the problem context and DP techniques. Large Language Models (LLMs) offer the potential to automate this process. However, DP problems pose unique challenges due to their inherently stochastic transitions and the limited availability of training data. These factors make it difficult to directly apply existing LLM-based models or frameworks developed for other optimization problems, such as linear or integer programming. We introduce DP-Bench, the first benchmark covering a wide range of textbook-level DP problems to enable systematic evaluation. We present Dynamic Programming Language Model (DPLM), a 7B-parameter specialized model that achieves performance comparable to state-of-the-art LLMs like OpenAI's o1 and DeepSeek-R1, and surpasses them on hard problems. Central to DPLM's effectiveness is DualReflect, our novel synthetic data generation pipeline, designed to scale up training data from a limited set of initial examples. DualReflect combines forward generation for diversity and backward generation for reliability. Our results reveal a key insight: backward generation is favored in low-data regimes for its strong correctness guarantees, while forward generation, though lacking such guarantees, becomes increasingly valuable at scale for introducing diverse formulations. This trade-off highlights the complementary strengths of both approaches and the importance of combining them.
Can LLMs Formally Reason as Abstract Interpreters for Program Analysis?
Mar 16, 2025LLMs have demonstrated impressive capabilities in code generation and comprehension, but their potential in being able to perform program analysis in a formal, automatic manner remains under-explored. To that end, we systematically investigate whether LLMs can reason about programs using a program analysis framework called abstract interpretation. We prompt LLMs to follow two different strategies, denoted as Compositional and Fixed Point Equation, to formally reason in the style of abstract interpretation, which has never been done before to the best of our knowledge. We validate our approach using state-of-the-art LLMs on 22 challenging benchmark programs from the Software Verification Competition (SV-COMP) 2019 dataset, widely used in program analysis. Our results show that our strategies are able to elicit abstract interpretation-based reasoning in the tested models, but LLMs are susceptible to logical errors, especially while interpreting complex program structures, as well as general hallucinations. This highlights key areas for improvement in the formal reasoning capabilities of LLMs.
VEGA: Learning Interleaved Image-Text Comprehension in Vision-Language Large Models
Jun 14, 2024The swift progress of Multi-modal Large Models (MLLMs) has showcased their impressive ability to tackle tasks blending vision and language. Yet, most current models and benchmarks cater to scenarios with a narrow scope of visual and textual contexts. These models often fall short when faced with complex comprehension tasks, which involve navigating through a plethora of irrelevant and potentially misleading information in both text and image forms. To bridge this gap, we introduce a new, more demanding task known as Interleaved Image-Text Comprehension (IITC). This task challenges models to discern and disregard superfluous elements in both images and text to accurately answer questions and to follow intricate instructions to pinpoint the relevant image. In support of this task, we further craft a new VEGA dataset, tailored for the IITC task on scientific content, and devised a subtask, Image-Text Association (ITA), to refine image-text correlation skills. Our evaluation of four leading closed-source models, as well as various open-source models using VEGA, underscores the rigorous nature of IITC. Even the most advanced models, such as Gemini-1.5-pro and GPT4V, only achieved modest success. By employing a multi-task, multi-scale post-training strategy, we have set a robust baseline for MLLMs on the IITC task, attaining an $85.8\%$ accuracy rate in image association and a $0.508$ Rouge score. These results validate the effectiveness of our dataset in improving MLLMs capabilities for nuanced image-text comprehension.
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
May 31, 2024



In the quest for artificial general intelligence, Multi-modal Large Language Models (MLLMs) have emerged as a focal point in recent advancements. However, the predominant focus remains on developing their capabilities in static image understanding. The potential of MLLMs in processing sequential visual data is still insufficiently explored, highlighting the absence of a comprehensive, high-quality assessment of their performance. In this paper, we introduce Video-MME, the first-ever full-spectrum, Multi-Modal Evaluation benchmark of MLLMs in Video analysis. Our work distinguishes from existing benchmarks through four key features: 1) Diversity in video types, spanning 6 primary visual domains with 30 subfields to ensure broad scenario generalizability; 2) Duration in temporal dimension, encompassing both short-, medium-, and long-term videos, ranging from 11 seconds to 1 hour, for robust contextual dynamics; 3) Breadth in data modalities, integrating multi-modal inputs besides video frames, including subtitles and audios, to unveil the all-round capabilities of MLLMs; 4) Quality in annotations, utilizing rigorous manual labeling by expert annotators to facilitate precise and reliable model assessment. 900 videos with a total of 256 hours are manually selected and annotated by repeatedly viewing all the video content, resulting in 2,700 question-answer pairs. With Video-MME, we extensively evaluate various state-of-the-art MLLMs, including GPT-4 series and Gemini 1.5 Pro, as well as open-source image models like InternVL-Chat-V1.5 and video models like LLaVA-NeXT-Video. Our experiments reveal that Gemini 1.5 Pro is the best-performing commercial model, significantly outperforming the open-source models. Our dataset along with these findings underscores the need for further improvements in handling longer sequences and multi-modal data. Project Page: https://video-mme.github.io
Exploring Neuron Interactions and Emergence in LLMs: From the Multifractal Analysis Perspective
Feb 14, 2024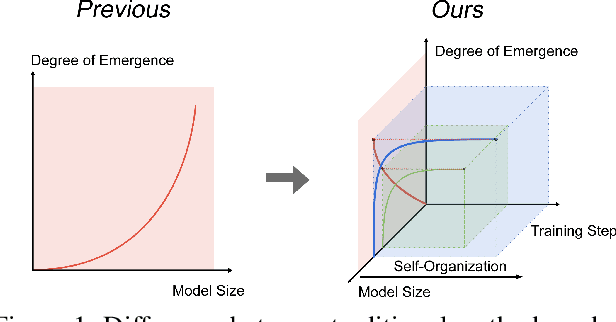
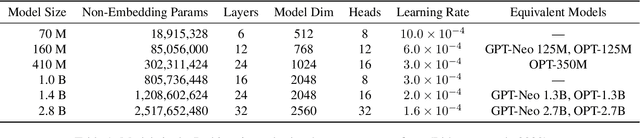

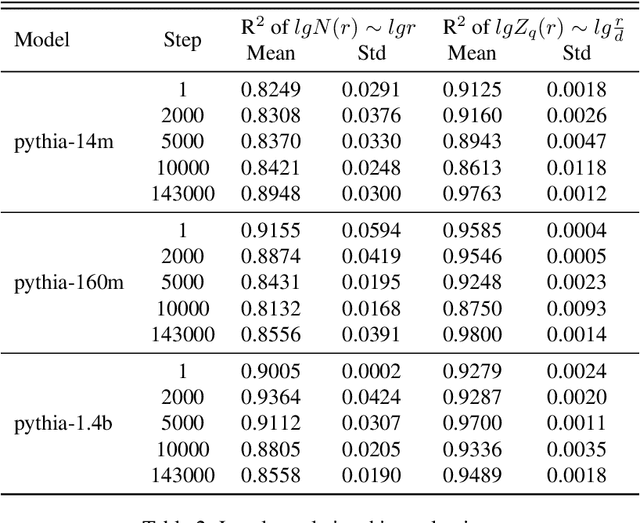
Prior studies on the emergence in large models have primarily focused on how the functional capabilities of large language models (LLMs) scale with model size. Our research, however, transcends this traditional paradigm, aiming to deepen our understanding of the emergence within LLMs by placing a special emphasis not just on the model size but more significantly on the complex behavior of neuron interactions during the training process. By introducing the concepts of "self-organization" and "multifractal analysis," we explore how neuron interactions dynamically evolve during training, leading to "emergence," mirroring the phenomenon in natural systems where simple micro-level interactions give rise to complex macro-level behaviors. To quantitatively analyze the continuously evolving interactions among neurons in large models during training, we propose the Neuron-based Multifractal Analysis (NeuroMFA). Utilizing NeuroMFA, we conduct a comprehensive examination of the emergent behavior in LLMs through the lens of both model size and training process, paving new avenues for research into the emergence in large models.
Leveraging Reinforcement Learning and Large Language Models for Code Optimization
Dec 09, 2023



Code optimization is a daunting task that requires a significant level of expertise from experienced programmers. This level of expertise is not sufficient when compared to the rapid development of new hardware architectures. Towards advancing the whole code optimization process, recent approaches rely on machine learning and artificial intelligence techniques. This paper introduces a new framework to decrease the complexity of code optimization. The proposed framework builds on large language models (LLMs) and reinforcement learning (RL) and enables LLMs to receive feedback from their environment (i.e., unit tests) during the fine-tuning process. We compare our framework with existing state-of-the-art models and show that it is more efficient with respect to speed and computational usage, as a result of the decrement in training steps and its applicability to models with fewer parameters. Additionally, our framework reduces the possibility of logical and syntactical errors. Toward evaluating our approach, we run several experiments on the PIE dataset using a CodeT5 language model and RRHF, a new reinforcement learning algorithm. We adopt a variety of evaluation metrics with regards to optimization quality, and speedup. The evaluation results demonstrate that the proposed framework has similar results in comparison with existing models using shorter training times and smaller pre-trained models. In particular, we accomplish an increase of 5.6% and 2.2 over the baseline models concerning the %OP T and SP metrics.
On Strengthening and Defending Graph Reconstruction Attack with Markov Chain Approximation
Jun 15, 2023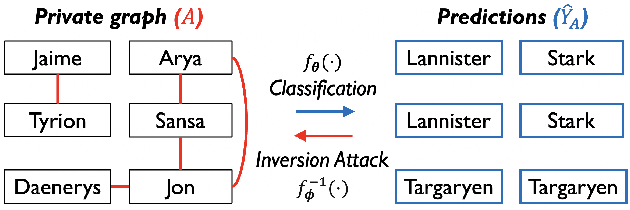
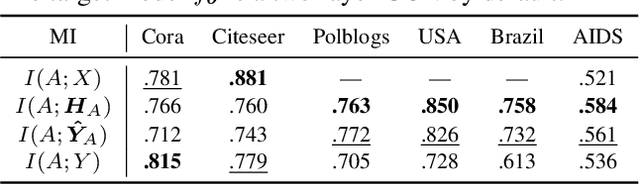
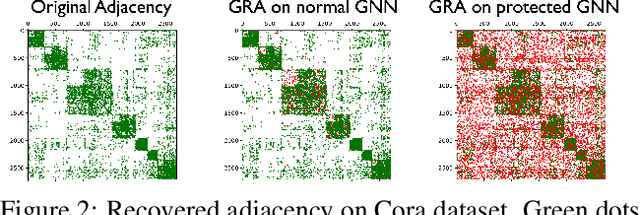

Although powerful graph neural networks (GNNs) have boosted numerous real-world applications, the potential privacy risk is still underexplored. To close this gap, we perform the first comprehensive study of graph reconstruction attack that aims to reconstruct the adjacency of nodes. We show that a range of factors in GNNs can lead to the surprising leakage of private links. Especially by taking GNNs as a Markov chain and attacking GNNs via a flexible chain approximation, we systematically explore the underneath principles of graph reconstruction attack, and propose two information theory-guided mechanisms: (1) the chain-based attack method with adaptive designs for extracting more private information; (2) the chain-based defense method that sharply reduces the attack fidelity with moderate accuracy loss. Such two objectives disclose a critical belief that to recover better in attack, you must extract more multi-aspect knowledge from the trained GNN; while to learn safer for defense, you must forget more link-sensitive information in training GNNs. Empirically, we achieve state-of-the-art results on six datasets and three common GNNs. The code is publicly available at: https://github.com/tmlr-group/MC-GRA.