 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMPILOT: Harnessing Transformer Models for Auto Parallelization to Shared Memory Computing Paradigms
Nov 11, 2025Recent advances in large language models (LLMs) have significantly accelerated progress in code translation, enabling more accurate and efficient transformation across programming languages. While originally developed for natural language processing, LLMs have shown strong capabilities in modeling programming language syntax and semantics, outperforming traditional rule-based systems in both accuracy and flexibility. These models have streamlined cross-language conversion, reduced development overhead, and accelerated legacy code migration. In this paper, we introduce OMPILOT, a novel domain-specific encoder-decoder transformer tailored for translating C++ code into OpenMP, enabling effective shared-memory parallelization. OMPILOT leverages custom pre-training objectives that incorporate the semantics of parallel constructs and combines both unsupervised and supervised learning strategies to improve code translation robustness. Unlike previous work that focused primarily on loop-level transformations, OMPILOT operates at the function level to capture a wider semantic context. To evaluate our approach, we propose OMPBLEU, a novel composite metric specifically crafted to assess the correctness and quality of OpenMP parallel constructs, addressing limitations in conventional translation metrics.
A structure-aware framework for learning device placements on computation graphs
May 23, 2024



Existing approaches for device placement ignore the topological features of computation graphs and rely mostly on heuristic methods for graph partitioning. At the same time, they either follow a grouper-placer or an encoder-placer architecture, which requires understanding the interaction structure between code operations. To bridge the gap between encoder-placer and grouper-placer techniques, we propose a novel framework for the task of device placement, relying on smaller computation graphs extracted from the OpenVINO toolkit using reinforcement learning. The framework consists of five steps, including graph coarsening, node representation learning and policy optimization. It facilitates end-to-end training and takes into consideration the directed and acyclic nature of the computation graphs. We also propose a model variant, inspired by graph parsing networks and complex network analysis, enabling graph representation learning and personalized graph partitioning jointly, using an unspecified number of groups. To train the entire framework, we utilize reinforcement learning techniques by employing the execution time of the suggested device placements to formulate the reward. We demonstrate the flexibility and effectiveness of our approach through multiple experiments with three benchmark models, namely Inception-V3, ResNet, and BERT. The robustness of the proposed framework is also highlighted through an ablation study. The suggested placements improve the inference speed for the benchmark models by up to $58.2\%$ over CPU execution and by up to $60.24\%$ compared to other commonly used baselines.
Domain-Specific Code Language Models: Unraveling the Potential for HPC Codes and Tasks
Dec 20, 2023With easier access to powerful compute resources, there is a growing trend in AI for software development to develop larger language models (LLMs) to address a variety of programming tasks. Even LLMs applied to tasks from the high-performance computing (HPC) domain are huge in size and demand expensive compute resources for training. This is partly because these LLMs for HPC tasks are obtained by finetuning existing LLMs that support several natural and/or programming languages. We found this design choice confusing - why do we need large LMs trained on natural languages and programming languages unrelated to HPC for HPC-specific tasks? In this line of work, we aim to question choices made by existing LLMs by developing smaller LMs for specific domains - we call them domain-specific LMs. Specifically, we start off with HPC as a domain and build an HPC-specific LM, named MonoCoder, that is orders of magnitude smaller than existing LMs but delivers similar, if not better performance, on non-HPC and HPC tasks. Specifically, we pre-trained MonoCoder on an HPC-specific dataset (named HPCorpus) of C and C++ programs mined from GitHub. We evaluated the performance of MonoCoder against conventional multi-lingual LLMs. Results demonstrate that MonoCoder, although much smaller than existing LMs, achieves similar results on normalized-perplexity tests and much better ones in CodeBLEU competence for high-performance and parallel code generations. Furthermore, fine-tuning the base model for the specific task of parallel code generation (OpenMP parallel for pragmas) demonstrates outstanding results compared to GPT, especially when local misleading semantics are removed by our novel pre-processor Tokompiler, showcasing the ability of domain-specific models to assist in HPC-relevant tasks.
Leveraging Reinforcement Learning and Large Language Models for Code Optimization
Dec 09, 2023



Code optimization is a daunting task that requires a significant level of expertise from experienced programmers. This level of expertise is not sufficient when compared to the rapid development of new hardware architectures. Towards advancing the whole code optimization process, recent approaches rely on machine learning and artificial intelligence techniques. This paper introduces a new framework to decrease the complexity of code optimization. The proposed framework builds on large language models (LLMs) and reinforcement learning (RL) and enables LLMs to receive feedback from their environment (i.e., unit tests) during the fine-tuning process. We compare our framework with existing state-of-the-art models and show that it is more efficient with respect to speed and computational usage, as a result of the decrement in training steps and its applicability to models with fewer parameters. Additionally, our framework reduces the possibility of logical and syntactical errors. Toward evaluating our approach, we run several experiments on the PIE dataset using a CodeT5 language model and RRHF, a new reinforcement learning algorithm. We adopt a variety of evaluation metrics with regards to optimization quality, and speedup. The evaluation results demonstrate that the proposed framework has similar results in comparison with existing models using shorter training times and smaller pre-trained models. In particular, we accomplish an increase of 5.6% and 2.2 over the baseline models concerning the %OP T and SP metrics.
End-to-end Mapping in Heterogeneous Systems Using Graph Representation Learning
Apr 25, 2022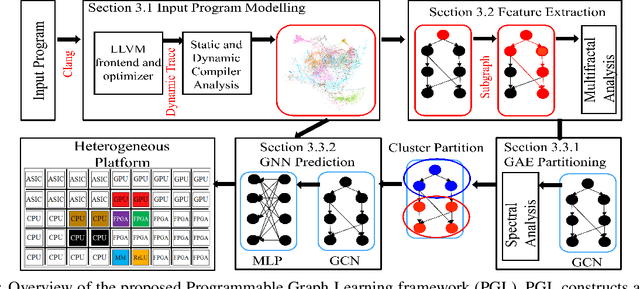
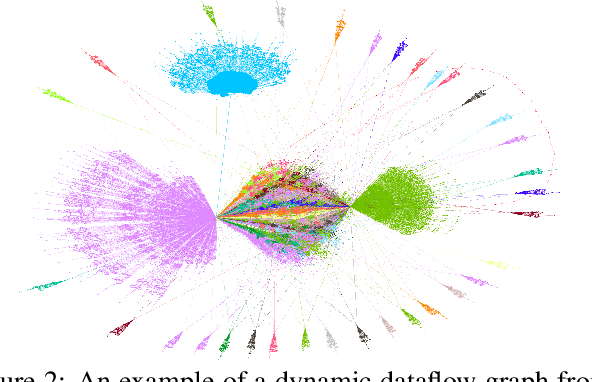
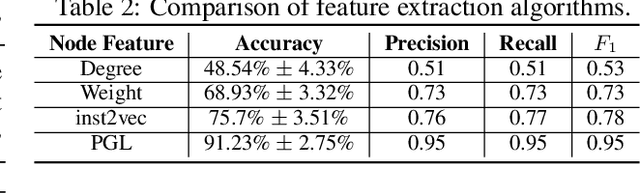
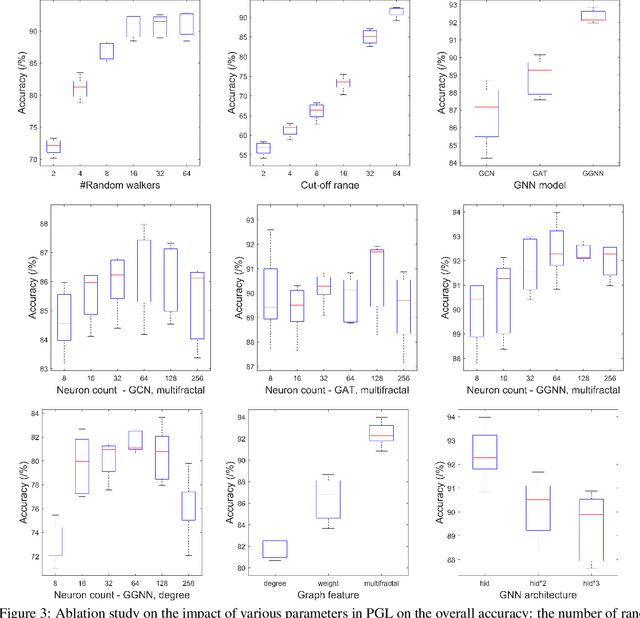
To enable heterogeneous computing systems with autonomous programming and optimization capabilities, we propose a unified, end-to-end, programmable graph representation learning (PGL) framework that is capable of mining the complexity of high-level programs down to the universal intermediate representation, extracting the specific computational patterns and predicting which code segments would run best on a specific core in heterogeneous hardware platforms. The proposed framework extracts multi-fractal topological features from code graphs, utilizes graph autoencoders to learn how to partition the graph into computational kernels, and exploits graph neural networks (GNN) to predict the correct assignment to a processor type. In the evaluation, we validate the PGL framework and demonstrate a maximum speedup of 6.42x compared to the thread-based execution, and 2.02x compared to the state-of-the-art technique.
A single-layer RNN can approximate stacked and bidirectional RNNs, and topologies in between
Aug 30, 2019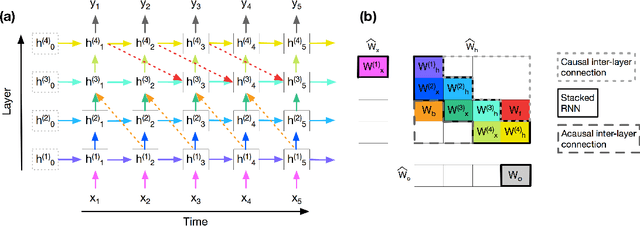
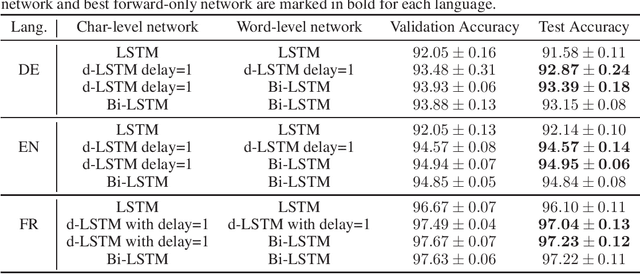
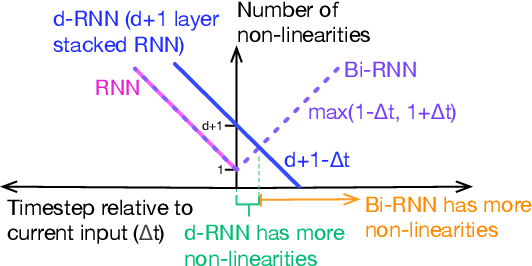
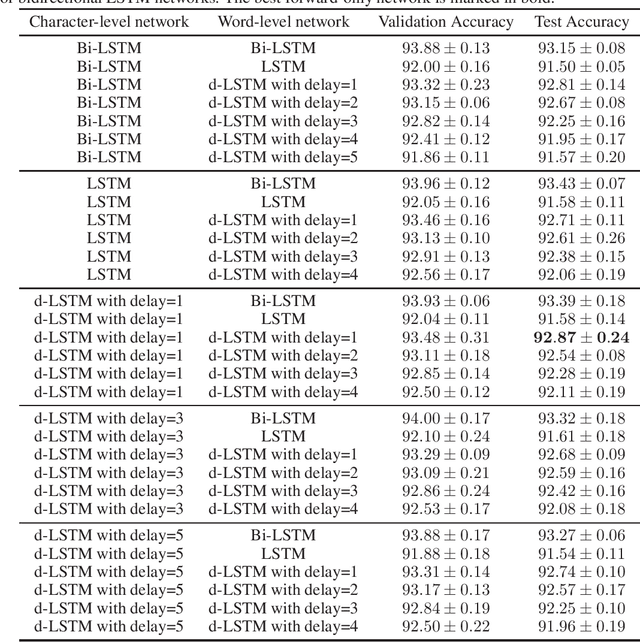
To enhance the expressiveness and representational capacity of recurrent neural networks (RNN), a large body of work has emerged exploring stacked architectures with additional topological modifications like shortcut connections or bidirectionality. However, choosing the best network for a particular problem requires a combinatorial search over architectures and their hyperparameters. In this work, we show that a single-layer RNN can perfectly mimic an arbitrarily deep stacked RNN under specific constraints on its weight matrix and a delay between input and output. This obviates the need to manually select hyperparameters like the number of layers. Additionally, we show that weakening weight constraints while keeping the delay gives rise to partial acausality in the single-layer RNN, much like a bidirectional network. Synthetic experiments confirm that the delayed RNN can mimic bidirectional networks in perfectly solving some acausal tasks, outperforming them in others. Finally, we show that in a challenging language processing task, the delayed RNN performs within 0.3\% of the accuracy of the bidirectional network while reducing computational costs.