 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe kernel of graph indices for vector search
Jun 25, 2025The most popular graph indices for vector search use principles from computational geometry to build the graph. Hence, their formal graph navigability guarantees are only valid in Euclidean space. In this work, we show that machine learning can be used to build graph indices for vector search in metric and non-metric vector spaces (e.g., for inner product similarity). From this novel perspective, we introduce the Support Vector Graph (SVG), a new type of graph index that leverages kernel methods to establish the graph connectivity and that comes with formal navigability guarantees valid in metric and non-metric vector spaces. In addition, we interpret the most popular graph indices, including HNSW and DiskANN, as particular specializations of SVG and show that new indices can be derived from the principles behind this specialization. Finally, we propose SVG-L0 that incorporates an $\ell_0$ sparsity constraint into the SVG kernel method to build graphs with a bounded out-degree. This yields a principled way of implementing this practical requirement, in contrast to the traditional heuristic of simply truncating the out edges of each node. Additionally, we show that SVG-L0 has a self-tuning property that avoids the heuristic of using a set of candidates to find the out-edges of each node and that keeps its computational complexity in check.
Toward Optimal Search and Retrieval for RAG
Nov 11, 2024Retrieval-augmented generation (RAG) is a promising method for addressing some of the memory-related challenges associated with Large Language Models (LLMs). Two separate systems form the RAG pipeline, the retriever and the reader, and the impact of each on downstream task performance is not well-understood. Here, we work towards the goal of understanding how retrievers can be optimized for RAG pipelines for common tasks such as Question Answering (QA). We conduct experiments focused on the relationship between retrieval and RAG performance on QA and attributed QA and unveil a number of insights useful to practitioners developing high-performance RAG pipelines. For example, lowering search accuracy has minor implications for RAG performance while potentially increasing retrieval speed and memory efficiency.
MPIrigen: MPI Code Generation through Domain-Specific Language Models
Feb 14, 2024



The imperative need to scale computation across numerous nodes highlights the significance of efficient parallel computing, particularly in the realm of Message Passing Interface (MPI) integration. The challenging parallel programming task of generating MPI-based parallel programs has remained unexplored. This study first investigates the performance of state-of-the-art language models in generating MPI-based parallel programs. Findings reveal that widely used models such as GPT-3.5 and PolyCoder (specialized multi-lingual code models) exhibit notable performance degradation, when generating MPI-based programs compared to general-purpose programs. In contrast, domain-specific models such as MonoCoder, which are pretrained on MPI-related programming languages of C and C++, outperform larger models. Subsequently, we introduce a dedicated downstream task of MPI-based program generation by fine-tuning MonoCoder on HPCorpusMPI. We call the resulting model as MPIrigen. We propose an innovative preprocessing for completion only after observing the whole code, thus enabling better completion with a wider context. Comparative analysis against GPT-3.5 zero-shot performance, using a novel HPC-oriented evaluation method, demonstrates that MPIrigen excels in generating accurate MPI functions up to 0.8 accuracy in location and function predictions, and with more than 0.9 accuracy for argument predictions. The success of this tailored solution underscores the importance of domain-specific fine-tuning in optimizing language models for parallel computing code generation, paving the way for a new generation of automatic parallelization tools. The sources of this work are available at our GitHub MPIrigen repository: https://github.com/Scientific-Computing-Lab-NRCN/MPI-rigen
LeanVec: Search your vectors faster by making them fit
Dec 26, 2023



Modern deep learning models have the ability to generate high-dimensional vectors whose similarity reflects semantic resemblance. Thus, similarity search, i.e., the operation of retrieving those vectors in a large collection that are similar to a given query, has become a critical component of a wide range of applications that demand highly accurate and timely answers. In this setting, the high vector dimensionality puts similarity search systems under compute and memory pressure, leading to subpar performance. Additionally, cross-modal retrieval tasks have become increasingly common, e.g., where a user inputs a text query to find the most relevant images for that query. However, these queries often have different distributions than the database embeddings, making it challenging to achieve high accuracy. In this work, we present LeanVec, a framework that combines linear dimensionality reduction with vector quantization to accelerate similarity search on high-dimensional vectors while maintaining accuracy. We present LeanVec variants for in-distribution (ID) and out-of-distribution (OOD) queries. LeanVec-ID yields accuracies on par with those from recently introduced deep learning alternatives whose computational overhead precludes their usage in practice. LeanVec-OOD uses a novel technique for dimensionality reduction that considers the query and database distributions to simultaneously boost the accuracy and the performance of the framework even further (even presenting competitive results when the query and database distributions match). All in all, our extensive and varied experimental results show that LeanVec produces state-of-the-art results, with up to 3.7x improvement in search throughput and up to 4.9x faster index build time over the state of the art.
Domain-Specific Code Language Models: Unraveling the Potential for HPC Codes and Tasks
Dec 20, 2023With easier access to powerful compute resources, there is a growing trend in AI for software development to develop larger language models (LLMs) to address a variety of programming tasks. Even LLMs applied to tasks from the high-performance computing (HPC) domain are huge in size and demand expensive compute resources for training. This is partly because these LLMs for HPC tasks are obtained by finetuning existing LLMs that support several natural and/or programming languages. We found this design choice confusing - why do we need large LMs trained on natural languages and programming languages unrelated to HPC for HPC-specific tasks? In this line of work, we aim to question choices made by existing LLMs by developing smaller LMs for specific domains - we call them domain-specific LMs. Specifically, we start off with HPC as a domain and build an HPC-specific LM, named MonoCoder, that is orders of magnitude smaller than existing LMs but delivers similar, if not better performance, on non-HPC and HPC tasks. Specifically, we pre-trained MonoCoder on an HPC-specific dataset (named HPCorpus) of C and C++ programs mined from GitHub. We evaluated the performance of MonoCoder against conventional multi-lingual LLMs. Results demonstrate that MonoCoder, although much smaller than existing LMs, achieves similar results on normalized-perplexity tests and much better ones in CodeBLEU competence for high-performance and parallel code generations. Furthermore, fine-tuning the base model for the specific task of parallel code generation (OpenMP parallel for pragmas) demonstrates outstanding results compared to GPT, especially when local misleading semantics are removed by our novel pre-processor Tokompiler, showcasing the ability of domain-specific models to assist in HPC-relevant tasks.
Scope is all you need: Transforming LLMs for HPC Code
Aug 18, 2023



With easier access to powerful compute resources, there is a growing trend in the field of AI for software development to develop larger and larger language models (LLMs) to address a variety of programming tasks. Even LLMs applied to tasks from the high-performance computing (HPC) domain are huge in size (e.g., billions of parameters) and demand expensive compute resources for training. We found this design choice confusing - why do we need large LLMs trained on natural languages and programming languages unrelated to HPC for HPC-specific tasks? In this line of work, we aim to question design choices made by existing LLMs by developing smaller LLMs for specific domains - we call them domain-specific LLMs. Specifically, we start off with HPC as a domain and propose a novel tokenizer named Tokompiler, designed specifically for preprocessing code in HPC and compilation-centric tasks. Tokompiler leverages knowledge of language primitives to generate language-oriented tokens, providing a context-aware understanding of code structure while avoiding human semantics attributed to code structures completely. We applied Tokompiler to pre-train two state-of-the-art models, SPT-Code and Polycoder, for a Fortran code corpus mined from GitHub. We evaluate the performance of these models against the conventional LLMs. Results demonstrate that Tokompiler significantly enhances code completion accuracy and semantic understanding compared to traditional tokenizers in normalized-perplexity tests, down to ~1 perplexity score. This research opens avenues for further advancements in domain-specific LLMs, catering to the unique demands of HPC and compilation tasks.
Similarity search in the blink of an eye with compressed indices
Apr 07, 2023Nowadays, data is represented by vectors. Retrieving those vectors, among millions and billions, that are similar to a given query is a ubiquitous problem of relevance for a wide range of applications. In this work, we present new techniques for creating faster and smaller indices to run these searches. To this end, we introduce a novel vector compression method, Locally-adaptive Vector Quantization (LVQ), that simultaneously reduces memory footprint and improves search performance, with minimal impact on search accuracy. LVQ is designed to work optimally in conjunction with graph-based indices, reducing their effective bandwidth while enabling random-access-friendly fast similarity computations. Our experimental results show that LVQ, combined with key optimizations for graph-based indices in modern datacenter systems, establishes the new state of the art in terms of performance and memory footprint. For billions of vectors, LVQ outcompetes the second-best alternatives: (1) in the low-memory regime, by up to 20.7x in throughput with up to a 3x memory footprint reduction, and (2) in the high-throughput regime by 5.8x with 1.4x less memory.
Toward a Geometrical Understanding of Self-supervised Contrastive Learning
May 13, 2022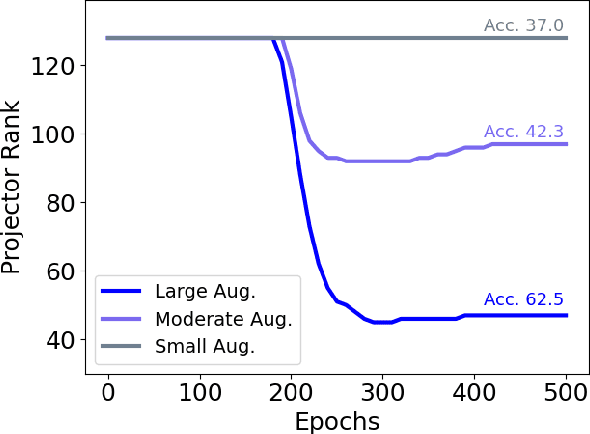

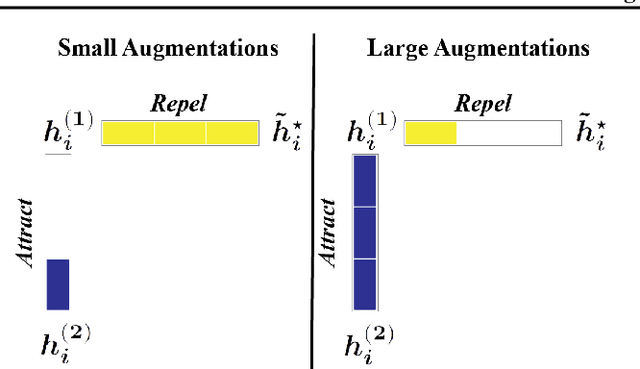

Self-supervised learning (SSL) is currently one of the premier techniques to create data representations that are actionable for transfer learning in the absence of human annotations. Despite their success, the underlying geometry of these representations remains elusive, which obfuscates the quest for more robust, trustworthy, and interpretable models. In particular, mainstream SSL techniques rely on a specific deep neural network architecture with two cascaded neural networks: the encoder and the projector. When used for transfer learning, the projector is discarded since empirical results show that its representation generalizes more poorly than the encoder's. In this paper, we investigate this curious phenomenon and analyze how the strength of the data augmentation policies affects the data embedding. We discover a non-trivial relation between the encoder, the projector, and the data augmentation strength: with increasingly larger augmentation policies, the projector, rather than the encoder, is more strongly driven to become invariant to the augmentations. It does so by eliminating crucial information about the data by learning to project it into a low-dimensional space, a noisy estimate of the data manifold tangent plane in the encoder representation. This analysis is substantiated through a geometrical perspective with theoretical and empirical results.
Procrustean Orthogonal Sparse Hashing
Jun 08, 2020
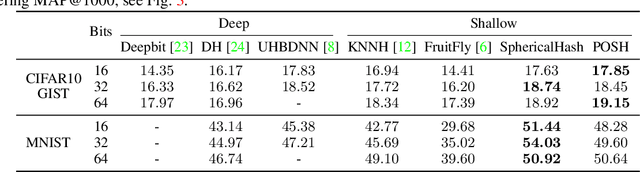

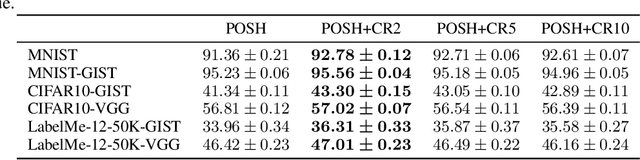
Hashing is one of the most popular methods for similarity search because of its speed and efficiency. Dense binary hashing is prevalent in the literature. Recently, insect olfaction was shown to be structurally and functionally analogous to sparse hashing [6]. Here, we prove that this biological mechanism is the solution to a well-posed optimization problem. Furthermore, we show that orthogonality increases the accuracy of sparse hashing. Next, we present a novel method, Procrustean Orthogonal Sparse Hashing (POSH), that unifies these findings, learning an orthogonal transform from training data compatible with the sparse hashing mechanism. We provide theoretical evidence of the shortcomings of Optimal Sparse Lifting (OSL) [22] and BioHash [30], two related olfaction-inspired methods, and propose two new methods, Binary OSL and SphericalHash, to address these deficiencies. We compare POSH, Binary OSL, and SphericalHash to several state-of-the-art hashing methods and provide empirical results for the superiority of the proposed methods across a wide range of standard benchmarks and parameter settings.
A View on Deep Reinforcement Learning in System Optimization
Sep 04, 2019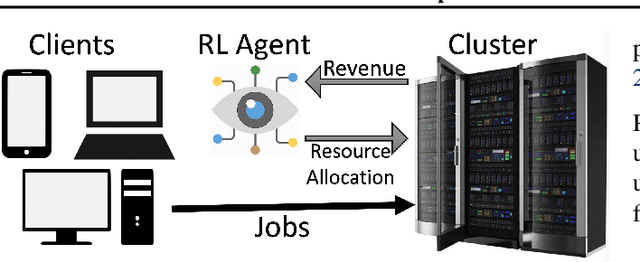
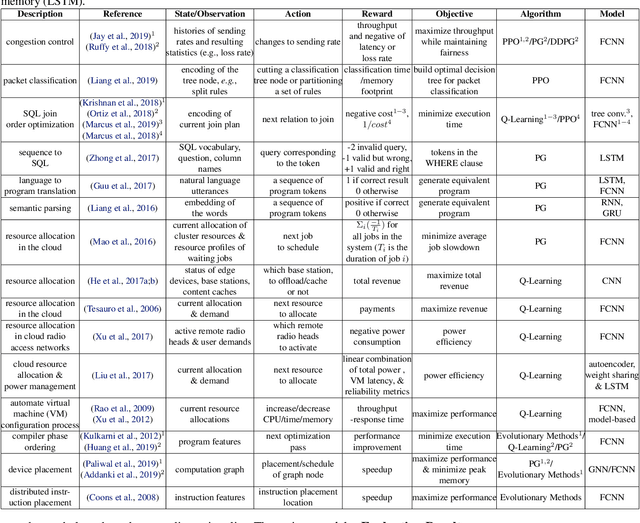
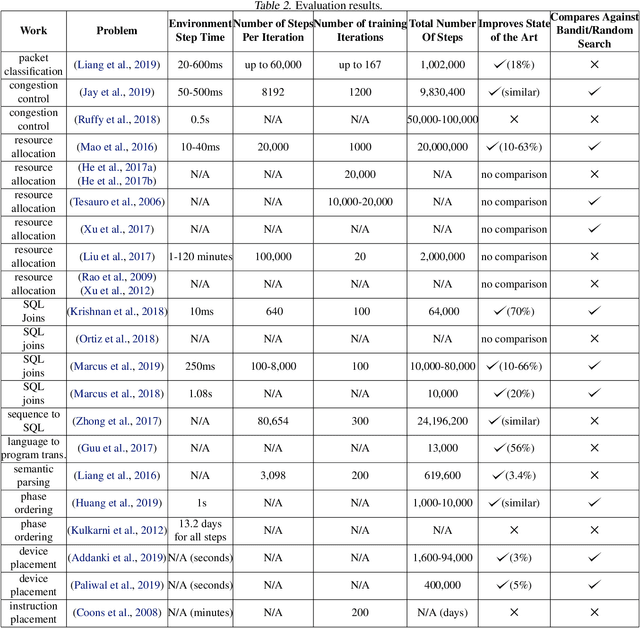
Many real-world systems problems require reasoning about the long term consequences of actions taken to configure and manage the system. These problems with delayed and often sequentially aggregated reward, are often inherently reinforcement learning problems and present the opportunity to leverage the recent substantial advances in deep reinforcement learning. However, in some cases, it is not clear why deep reinforcement learning is a good fit for the problem. Sometimes, it does not perform better than the state-of-the-art solutions. And in other cases, random search or greedy algorithms could outperform deep reinforcement learning. In this paper, we review, discuss, and evaluate the recent trends of using deep reinforcement learning in system optimization. We propose a set of essential metrics to guide future works in evaluating the efficacy of using deep reinforcement learning in system optimization. Our evaluation includes challenges, the types of problems, their formulation in the deep reinforcement learning setting, embedding, the model used, efficiency, and robustness. We conclude with a discussion on open challenges and potential directions for pushing further the integration of reinforcement learning in system optimization.