 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoPhase: Juggling HLS Phase Orderings in Random Forests with Deep Reinforcement Learning
Mar 04, 2020


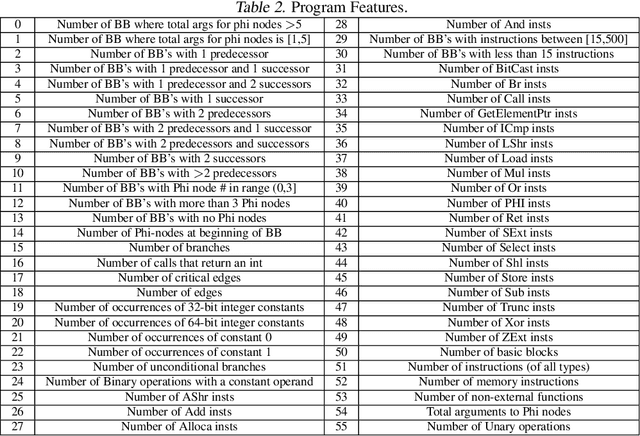
The performance of the code a compiler generates depends on the order in which it applies the optimization passes. Choosing a good order--often referred to as the phase-ordering problem, is an NP-hard problem. As a result, existing solutions rely on a variety of heuristics. In this paper, we evaluate a new technique to address the phase-ordering problem: deep reinforcement learning. To this end, we implement AutoPhase: a framework that takes a program and uses deep reinforcement learning to find a sequence of compilation passes that minimizes its execution time. Without loss of generality, we construct this framework in the context of the LLVM compiler toolchain and target high-level synthesis programs. We use random forests to quantify the correlation between the effectiveness of a given pass and the program's features. This helps us reduce the search space by avoiding phase orderings that are unlikely to improve the performance of a given program. We compare the performance of AutoPhase to state-of-the-art algorithms that address the phase-ordering problem. In our evaluation, we show that AutoPhase improves circuit performance by 28% when compared to using the -O3 compiler flag, and achieves competitive results compared to the state-of-the-art solutions, while requiring fewer samples. Furthermore, unlike existing state-of-the-art solutions, our deep reinforcement learning solution shows promising result in generalizing to real benchmarks and 12,874 different randomly generated programs, after training on a hundred randomly generated programs.
Gemmini: An Agile Systolic Array Generator Enabling Systematic Evaluations of Deep-Learning Architectures
Dec 07, 2019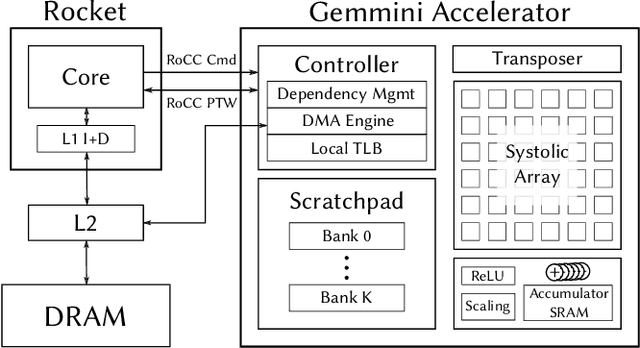
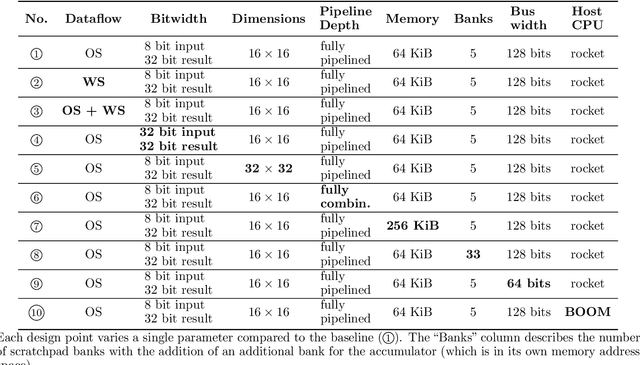
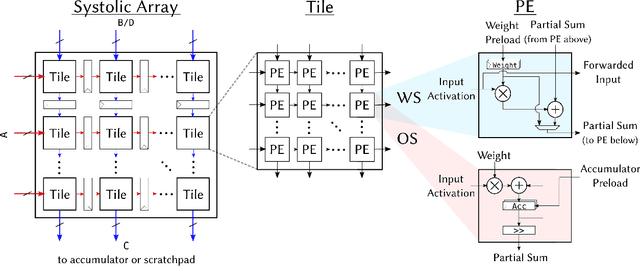
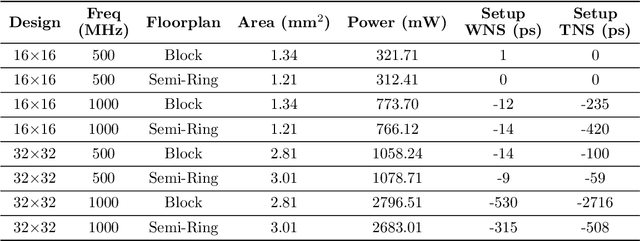
Advances in deep learning and neural networks have resulted in the rapid development of hardware accelerators that support them. A large majority of ASIC accelerators, however, target a single hardware design point to accelerate the main computational kernels of deep neural networks such as convolutions or matrix multiplication. On the other hand, the spectrum of use-cases for neural network accelerators, ranging from edge devices to cloud, presents a prime opportunity for agile hardware design and generator methodologies. We present Gemmini -- an open source and agile systolic array generator enabling systematic evaluations of deep-learning architectures. Gemmini generates a custom ASIC accelerator for matrix multiplication based on a systolic array architecture, complete with additional functions for neural network inference. Gemmini runs with the RISC-V ISA, and is integrated with the Rocket Chip System-on-Chip generator ecosystem, including Rocket in-order cores and BOOM out-of-order cores. Through an elaborate design space exploration case study, this work demonstrates the selection processes of various parameters for the use-case of inference on edge devices. Selected design points achieve two to three orders of magnitude speedup in deep neural network inference compared to the baseline execution on a host processor. Gemmini-generated accelerators were used in the fabrication of test systems-on-chip in TSMC 16nm and Intel 22FFL process technologies.
A View on Deep Reinforcement Learning in System Optimization
Sep 04, 2019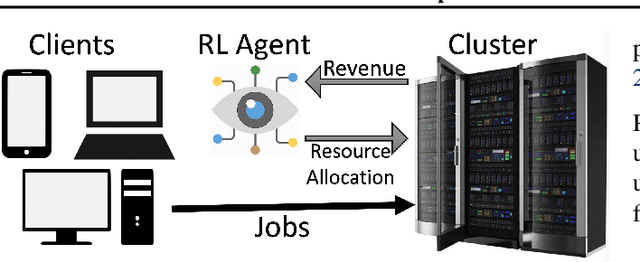
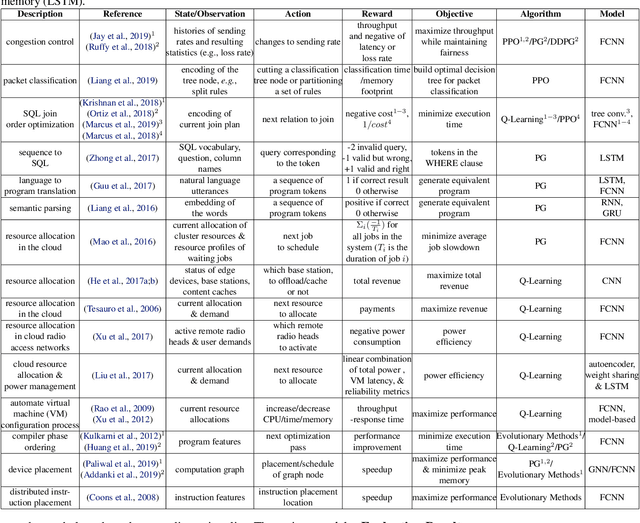
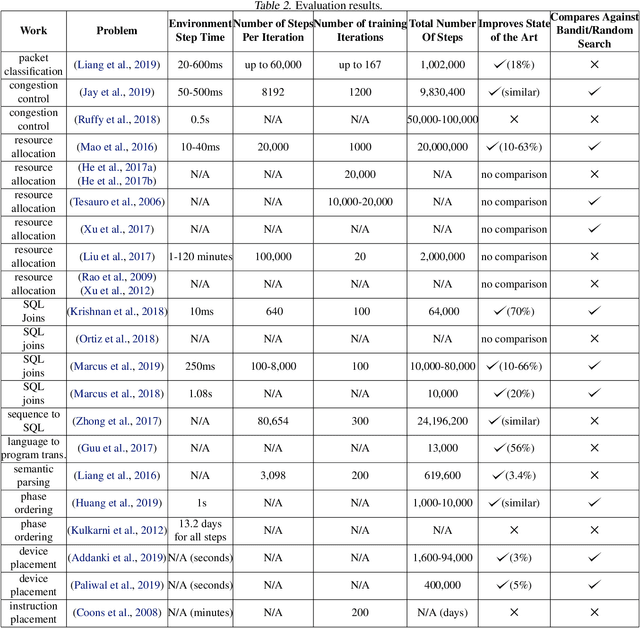
Many real-world systems problems require reasoning about the long term consequences of actions taken to configure and manage the system. These problems with delayed and often sequentially aggregated reward, are often inherently reinforcement learning problems and present the opportunity to leverage the recent substantial advances in deep reinforcement learning. However, in some cases, it is not clear why deep reinforcement learning is a good fit for the problem. Sometimes, it does not perform better than the state-of-the-art solutions. And in other cases, random search or greedy algorithms could outperform deep reinforcement learning. In this paper, we review, discuss, and evaluate the recent trends of using deep reinforcement learning in system optimization. We propose a set of essential metrics to guide future works in evaluating the efficacy of using deep reinforcement learning in system optimization. Our evaluation includes challenges, the types of problems, their formulation in the deep reinforcement learning setting, embedding, the model used, efficiency, and robustness. We conclude with a discussion on open challenges and potential directions for pushing further the integration of reinforcement learning in system optimization.
AutoPhase: Compiler Phase-Ordering for High Level Synthesis with Deep Reinforcement Learning
Jan 15, 2019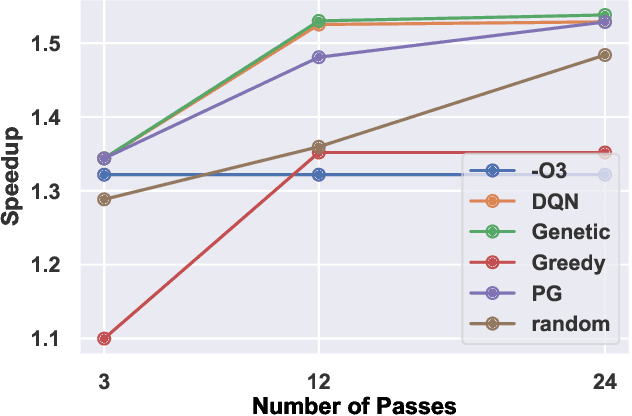
The performance of the code generated by a compiler depends on the order in which the optimization passes are applied. In the context of high-level synthesis, the quality of the generated circuit relates directly to the code generated by the front-end compiler. Unfortunately, choosing a good order--often referred to as the phase-ordering problem--is an NP-hard problem. As a result, existing solutions rely on a variety of sub-optimal heuristics. In this paper, we evaluate a new technique to address the phase-ordering problem: deep reinforcement learning. To this end, we implement a framework that takes any group of programs and finds a sequence of passes that optimize the performance of these programs. Without loss of generality, we instantiate this framework in the context of an LLVM compiler and target multiple High-Level Synthesis programs. We compare the performance of deep reinforcement learning to state-of-the-art algorithms that address the phase-ordering problem. Overall, our framework runs one to two orders of magnitude faster than these algorithms, and achieves a 16% improvement in circuit performance over the -O3 compiler flag.