 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoPhase: Compiler Phase-Ordering for High Level Synthesis with Deep Reinforcement Learning
Paper and Code
Jan 15, 2019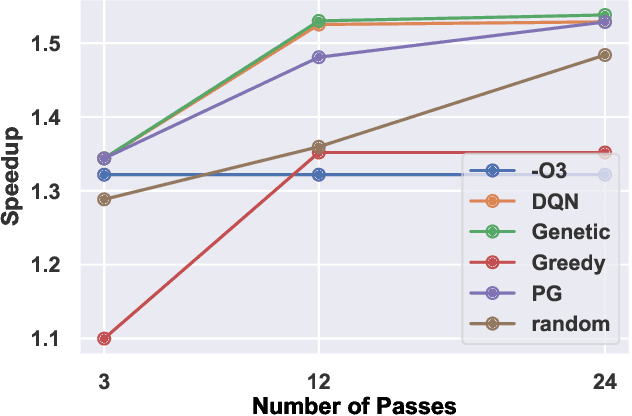
The performance of the code generated by a compiler depends on the order in which the optimization passes are applied. In the context of high-level synthesis, the quality of the generated circuit relates directly to the code generated by the front-end compiler. Unfortunately, choosing a good order--often referred to as the phase-ordering problem--is an NP-hard problem. As a result, existing solutions rely on a variety of sub-optimal heuristics. In this paper, we evaluate a new technique to address the phase-ordering problem: deep reinforcement learning. To this end, we implement a framework that takes any group of programs and finds a sequence of passes that optimize the performance of these programs. Without loss of generality, we instantiate this framework in the context of an LLVM compiler and target multiple High-Level Synthesis programs. We compare the performance of deep reinforcement learning to state-of-the-art algorithms that address the phase-ordering problem. Overall, our framework runs one to two orders of magnitude faster than these algorithms, and achieves a 16% improvement in circuit performance over the -O3 compiler flag.