 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward a Geometrical Understanding of Self-supervised Contrastive Learning
May 13, 2022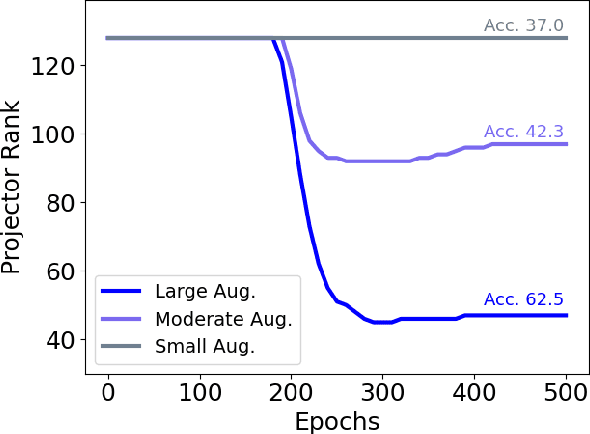

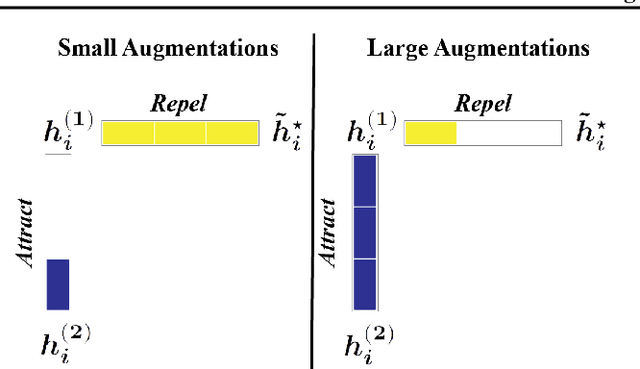

Self-supervised learning (SSL) is currently one of the premier techniques to create data representations that are actionable for transfer learning in the absence of human annotations. Despite their success, the underlying geometry of these representations remains elusive, which obfuscates the quest for more robust, trustworthy, and interpretable models. In particular, mainstream SSL techniques rely on a specific deep neural network architecture with two cascaded neural networks: the encoder and the projector. When used for transfer learning, the projector is discarded since empirical results show that its representation generalizes more poorly than the encoder's. In this paper, we investigate this curious phenomenon and analyze how the strength of the data augmentation policies affects the data embedding. We discover a non-trivial relation between the encoder, the projector, and the data augmentation strength: with increasingly larger augmentation policies, the projector, rather than the encoder, is more strongly driven to become invariant to the augmentations. It does so by eliminating crucial information about the data by learning to project it into a low-dimensional space, a noisy estimate of the data manifold tangent plane in the encoder representation. This analysis is substantiated through a geometrical perspective with theoretical and empirical results.
Spatial Transformer K-Means
Feb 16, 2022



K-means defines one of the most employed centroid-based clustering algorithms with performances tied to the data's embedding. Intricate data embeddings have been designed to push $K$-means performances at the cost of reduced theoretical guarantees and interpretability of the results. Instead, we propose preserving the intrinsic data space and augment K-means with a similarity measure invariant to non-rigid transformations. This enables (i) the reduction of intrinsic nuisances associated with the data, reducing the complexity of the clustering task and increasing performances and producing state-of-the-art results, (ii) clustering in the input space of the data, leading to a fully interpretable clustering algorithm, and (iii) the benefit of convergence guarantees.
Interpretable Image Clustering via Diffeomorphism-Aware K-Means
Dec 16, 2020



We design an interpretable clustering algorithm aware of the nonlinear structure of image manifolds. Our approach leverages the interpretability of $K$-means applied in the image space while addressing its clustering performance issues. Specifically, we develop a measure of similarity between images and centroids that encompasses a general class of deformations: diffeomorphisms, rendering the clustering invariant to them. Our work leverages the Thin-Plate Spline interpolation technique to efficiently learn diffeomorphisms best characterizing the image manifolds. Extensive numerical simulations show that our approach competes with state-of-the-art methods on various datasets.
Why do similarity matching objectives lead to Hebbian/anti-Hebbian networks?
Jul 11, 2017Modeling self-organization of neural networks for unsupervised learning using Hebbian and anti-Hebbian plasticity has a long history in neuroscience. Yet, derivations of single-layer networks with such local learning rules from principled optimization objectives became possible only recently, with the introduction of similarity matching objectives. What explains the success of similarity matching objectives in deriving neural networks with local learning rules? Here, using dimensionality reduction as an example, we introduce several variable substitutions that illuminate the success of similarity matching. We show that the full network objective may be optimized separately for each synapse using local learning rules both in the offline and online settings. We formalize the long-standing intuition of the rivalry between Hebbian and anti-Hebbian rules by formulating a min-max optimization problem. We introduce a novel dimensionality reduction objective using fractional matrix exponents. To illustrate the generality of our approach, we apply it to a novel formulation of dimensionality reduction combined with whitening. We confirm numerically that the networks with learning rules derived from principled objectives perform better than those with heuristic learning rules.