 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential Mamba
Jul 08, 2025Sequence models like Transformers and RNNs often overallocate attention to irrelevant context, leading to noisy intermediate representations. This degrades LLM capabilities by promoting hallucinations, weakening long-range and retrieval abilities, and reducing robustness. Recent work has shown that differential design can mitigate this issue in Transformers, improving their effectiveness across various applications. In this paper, we explore whether these techniques, originally developed for Transformers, can be applied to Mamba, a recent architecture based on selective state-space layers that achieves Transformer-level performance with greater efficiency. We show that a naive adaptation of differential design to Mamba is insufficient and requires careful architectural modifications. To address this, we introduce a novel differential mechanism for Mamba, empirically validated on language modeling benchmarks, demonstrating improved retrieval capabilities and superior performance over vanilla Mamba. Finally, we conduct extensive ablation studies and empirical analyses to justify our design choices and provide evidence that our approach effectively mitigates the overallocation problem in Mamba-based models. Our code is publicly available.
Reactor Optimization Benchmark by Reinforcement Learning
Mar 21, 2024



Neutronic calculations for reactors are a daunting task when using Monte Carlo (MC) methods. As high-performance computing has advanced, the simulation of a reactor is nowadays more readily done, but design and optimization with multiple parameters is still a computational challenge. MC transport simulations, coupled with machine learning techniques, offer promising avenues for enhancing the efficiency and effectiveness of nuclear reactor optimization. This paper introduces a novel benchmark problem within the OpenNeoMC framework designed specifically for reinforcement learning. The benchmark involves optimizing a unit cell of a research reactor with two varying parameters (fuel density and water spacing) to maximize neutron flux while maintaining reactor criticality. The test case features distinct local optima, representing different physical regimes, thus posing a challenge for learning algorithms. Through extensive simulations utilizing evolutionary and neuroevolutionary algorithms, we demonstrate the effectiveness of reinforcement learning in navigating complex optimization landscapes with strict constraints. Furthermore, we propose acceleration techniques within the OpenNeoMC framework, including model updating and cross-section usage by RAM utilization, to expedite simulation times. Our findings emphasize the importance of machine learning integration in reactor optimization and contribute to advancing methodologies for addressing intricate optimization challenges in nuclear engineering. The sources of this work are available at our GitHub repository: https://github.com/Scientific-Computing-Lab-NRCN/RLOpenNeoMC
MPIrigen: MPI Code Generation through Domain-Specific Language Models
Feb 14, 2024



The imperative need to scale computation across numerous nodes highlights the significance of efficient parallel computing, particularly in the realm of Message Passing Interface (MPI) integration. The challenging parallel programming task of generating MPI-based parallel programs has remained unexplored. This study first investigates the performance of state-of-the-art language models in generating MPI-based parallel programs. Findings reveal that widely used models such as GPT-3.5 and PolyCoder (specialized multi-lingual code models) exhibit notable performance degradation, when generating MPI-based programs compared to general-purpose programs. In contrast, domain-specific models such as MonoCoder, which are pretrained on MPI-related programming languages of C and C++, outperform larger models. Subsequently, we introduce a dedicated downstream task of MPI-based program generation by fine-tuning MonoCoder on HPCorpusMPI. We call the resulting model as MPIrigen. We propose an innovative preprocessing for completion only after observing the whole code, thus enabling better completion with a wider context. Comparative analysis against GPT-3.5 zero-shot performance, using a novel HPC-oriented evaluation method, demonstrates that MPIrigen excels in generating accurate MPI functions up to 0.8 accuracy in location and function predictions, and with more than 0.9 accuracy for argument predictions. The success of this tailored solution underscores the importance of domain-specific fine-tuning in optimizing language models for parallel computing code generation, paving the way for a new generation of automatic parallelization tools. The sources of this work are available at our GitHub MPIrigen repository: https://github.com/Scientific-Computing-Lab-NRCN/MPI-rigen
Domain-Specific Code Language Models: Unraveling the Potential for HPC Codes and Tasks
Dec 20, 2023With easier access to powerful compute resources, there is a growing trend in AI for software development to develop larger language models (LLMs) to address a variety of programming tasks. Even LLMs applied to tasks from the high-performance computing (HPC) domain are huge in size and demand expensive compute resources for training. This is partly because these LLMs for HPC tasks are obtained by finetuning existing LLMs that support several natural and/or programming languages. We found this design choice confusing - why do we need large LMs trained on natural languages and programming languages unrelated to HPC for HPC-specific tasks? In this line of work, we aim to question choices made by existing LLMs by developing smaller LMs for specific domains - we call them domain-specific LMs. Specifically, we start off with HPC as a domain and build an HPC-specific LM, named MonoCoder, that is orders of magnitude smaller than existing LMs but delivers similar, if not better performance, on non-HPC and HPC tasks. Specifically, we pre-trained MonoCoder on an HPC-specific dataset (named HPCorpus) of C and C++ programs mined from GitHub. We evaluated the performance of MonoCoder against conventional multi-lingual LLMs. Results demonstrate that MonoCoder, although much smaller than existing LMs, achieves similar results on normalized-perplexity tests and much better ones in CodeBLEU competence for high-performance and parallel code generations. Furthermore, fine-tuning the base model for the specific task of parallel code generation (OpenMP parallel for pragmas) demonstrates outstanding results compared to GPT, especially when local misleading semantics are removed by our novel pre-processor Tokompiler, showcasing the ability of domain-specific models to assist in HPC-relevant tasks.
Scope is all you need: Transforming LLMs for HPC Code
Aug 18, 2023



With easier access to powerful compute resources, there is a growing trend in the field of AI for software development to develop larger and larger language models (LLMs) to address a variety of programming tasks. Even LLMs applied to tasks from the high-performance computing (HPC) domain are huge in size (e.g., billions of parameters) and demand expensive compute resources for training. We found this design choice confusing - why do we need large LLMs trained on natural languages and programming languages unrelated to HPC for HPC-specific tasks? In this line of work, we aim to question design choices made by existing LLMs by developing smaller LLMs for specific domains - we call them domain-specific LLMs. Specifically, we start off with HPC as a domain and propose a novel tokenizer named Tokompiler, designed specifically for preprocessing code in HPC and compilation-centric tasks. Tokompiler leverages knowledge of language primitives to generate language-oriented tokens, providing a context-aware understanding of code structure while avoiding human semantics attributed to code structures completely. We applied Tokompiler to pre-train two state-of-the-art models, SPT-Code and Polycoder, for a Fortran code corpus mined from GitHub. We evaluate the performance of these models against the conventional LLMs. Results demonstrate that Tokompiler significantly enhances code completion accuracy and semantic understanding compared to traditional tokenizers in normalized-perplexity tests, down to ~1 perplexity score. This research opens avenues for further advancements in domain-specific LLMs, catering to the unique demands of HPC and compilation tasks.
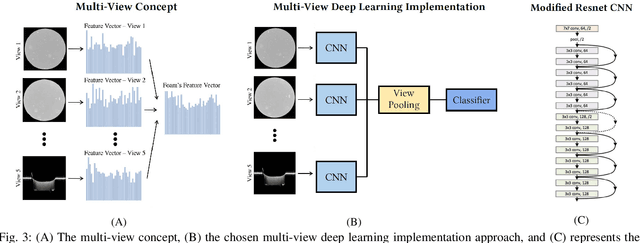
Explainable Multi-View Deep Networks Methodology for Experimental Physics
Aug 17, 2023



Physical experiments often involve multiple imaging representations, such as X-ray scans and microscopic images. Deep learning models have been widely used for supervised analysis in these experiments. Combining different image representations is frequently required to analyze and make a decision properly. Consequently, multi-view data has emerged - datasets where each sample is described by views from different angles, sources, or modalities. These problems are addressed with the concept of multi-view learning. Understanding the decision-making process of deep learning models is essential for reliable and credible analysis. Hence, many explainability methods have been devised recently. Nonetheless, there is a lack of proper explainability in multi-view models, which are challenging to explain due to their architectures. In this paper, we suggest different multi-view architectures for the vision domain, each suited to another problem, and we also present a methodology for explaining these models. To demonstrate the effectiveness of our methodology, we focus on the domain of High Energy Density Physics (HEDP) experiments, where multiple imaging representations are used to assess the quality of foam samples. We apply our methodology to classify the foam samples quality using the suggested multi-view architectures. Through experimental results, we showcase the improvement of accurate architecture choice on both accuracy - 78% to 84% and AUC - 83% to 93% and present a trade-off between performance and explainability. Specifically, we demonstrate that our approach enables the explanation of individual one-view models, providing insights into the decision-making process of each view. This understanding enhances the interpretability of the overall multi-view model. The sources of this work are available at: https://github.com/Scientific-Computing-Lab-NRCN/Multi-View-Explainability.
Advising OpenMP Parallelization via a Graph-Based Approach with Transformers
May 16, 2023



There is an ever-present need for shared memory parallelization schemes to exploit the full potential of multi-core architectures. The most common parallelization API addressing this need today is OpenMP. Nevertheless, writing parallel code manually is complex and effort-intensive. Thus, many deterministic source-to-source (S2S) compilers have emerged, intending to automate the process of translating serial to parallel code. However, recent studies have shown that these compilers are impractical in many scenarios. In this work, we combine the latest advancements in the field of AI and natural language processing (NLP) with the vast amount of open-source code to address the problem of automatic parallelization. Specifically, we propose a novel approach, called OMPify, to detect and predict the OpenMP pragmas and shared-memory attributes in parallel code, given its serial version. OMPify is based on a Transformer-based model that leverages a graph-based representation of source code that exploits the inherent structure of code. We evaluated our tool by predicting the parallelization pragmas and attributes of a large corpus of (over 54,000) snippets of serial code written in C and C++ languages (Open-OMP-Plus). Our results demonstrate that OMPify outperforms existing approaches, the general-purposed and popular ChatGPT and targeted PragFormer models, in terms of F1 score and accuracy. Specifically, OMPify achieves up to 90% accuracy on commonly-used OpenMP benchmark tests such as NAS, SPEC, and PolyBench. Additionally, we performed an ablation study to assess the impact of different model components and present interesting insights derived from the study. Lastly, we also explored the potential of using data augmentation and curriculum learning techniques to improve the model's robustness and generalization capabilities.
MPI-rical: Data-Driven MPI Distributed Parallelism Assistance with Transformers
May 16, 2023Automatic source-to-source parallelization of serial code for shared and distributed memory systems is a challenging task in high-performance computing. While many attempts were made to translate serial code into parallel code for a shared memory environment (usually using OpenMP), none has managed to do so for a distributed memory environment. In this paper, we propose a novel approach, called MPI-rical, for automated MPI code generation using a transformer-based model trained on approximately 25,000 serial code snippets and their corresponding parallelized MPI code out of more than 50,000 code snippets in our corpus (MPICodeCorpus). To evaluate the performance of the model, we first break down the serial code to MPI-based parallel code translation problem into two sub-problems and develop two research objectives: code completion defined as given a location in the source code, predict the MPI function for that location, and code translation defined as predicting an MPI function as well as its location in the source code. We evaluate MPI-rical on MPICodeCorpus dataset and on real-world scientific code benchmarks and compare its performance between the code completion and translation tasks. Our experimental results show that while MPI-rical performs better on the code completion task than the code translation task, the latter is better suited for real-world programming assistance, in which the tool suggests the need for an MPI function regardless of prior knowledge. Overall, our approach represents a significant step forward in automating the parallelization of serial code for distributed memory systems, which can save valuable time and resources for software developers and researchers. The source code used in this work, as well as other relevant sources, are available at: https://github.com/Scientific-Computing-Lab-NRCN/MPI-rical
Hate Speech Targets Detection in Parler using BERT
Apr 03, 2023Online social networks have become a fundamental component of our everyday life. Unfortunately, these platforms are also a stage for hate speech. Popular social networks have regularized rules against hate speech. Consequently, social networks like Parler and Gab advocating and claiming to be free speech platforms have evolved. These platforms have become a district for hate speech against diverse targets. We present in our paper a pipeline for detecting hate speech and its targets and use it for creating Parler hate targets' distribution. The pipeline consists of two models; one for hate speech detection and the second for target classification, both based on BERT with Back-Translation and data pre-processing for improved results. The source code used in this work, as well as other relevant sources, are available at: https://github.com/NadavSc/HateRecognition.git
Determining HEDP Foams' Quality with Multi-View Deep Learning Classification
Aug 10, 2022

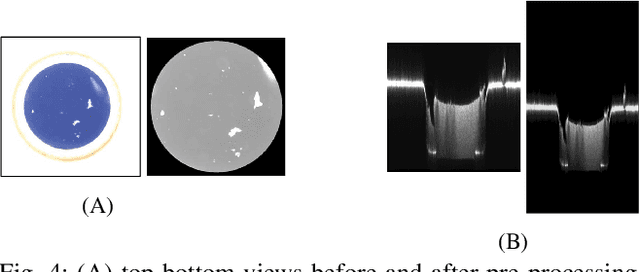
High energy density physics (HEDP) experiments commonly involve a dynamic wave-front propagating inside a low-density foam. This effect affects its density and hence, its transparency. A common problem in foam production is the creation of defective foams. Accurate information on their dimension and homogeneity is required to classify the foams' quality. Therefore, those parameters are being characterized using a 3D-measuring laser confocal microscope. For each foam, five images are taken: two 2D images representing the top and bottom surface foam planes and three images of side cross-sections from 3D scannings. An expert has to do the complicated, harsh, and exhausting work of manually classifying the foam's quality through the image set and only then determine whether the foam can be used in experiments or not. Currently, quality has two binary levels of normal vs. defective. At the same time, experts are commonly required to classify a sub-class of normal-defective, i.e., foams that are defective but might be sufficient for the needed experiment. This sub-class is problematic due to inconclusive judgment that is primarily intuitive. In this work, we present a novel state-of-the-art multi-view deep learning classification model that mimics the physicist's perspective by automatically determining the foams' quality classification and thus aids the expert. Our model achieved 86\% accuracy on upper and lower surface foam planes and 82\% on the entire set, suggesting interesting heuristics to the problem. A significant added value in this work is the ability to regress the foam quality instead of binary deduction and even explain the decision visually. The source code used in this work, as well as other relevant sources, are available at: https://github.com/Scientific-Computing-Lab-NRCN/Multi-View-Foams.git