 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCSPNet-Joint: Efficient Joint Training Method for Traffic Sign Detection Under Extreme Conditions
Sep 25, 2023Traffic sign detection is an important research direction in intelligent driving. Unfortunately, existing methods often overlook extreme conditions such as fog, rain, and motion blur. Moreover, the end-to-end training strategy for image denoising and object detection models fails to utilize inter-model information effectively. To address these issues, we propose CCSPNet, an efficient feature extraction module based on Transformers and CNNs, which effectively leverages contextual information, achieves faster inference speed and provides stronger feature enhancement capabilities. Furthermore, we establish the correlation between object detection and image denoising tasks and propose a joint training model, CCSPNet-Joint, to improve data efficiency and generalization. Finally, to validate our approach, we create the CCTSDB-AUG dataset for traffic sign detection in extreme scenarios. Extensive experiments have shown that CCSPNet achieves state-of-the-art performance in traffic sign detection under extreme conditions. Compared to end-to-end methods, CCSPNet-Joint achieves a 5.32% improvement in precision and an 18.09% improvement in mAP@.5.
Network Pruning via Feature Shift Minimization
Jul 06, 2022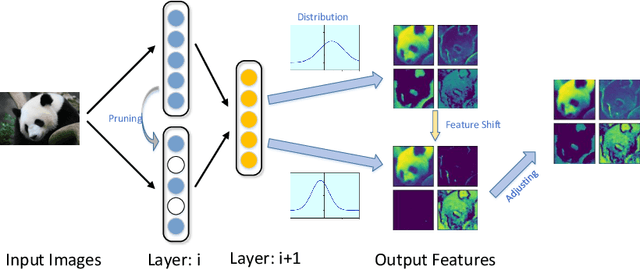
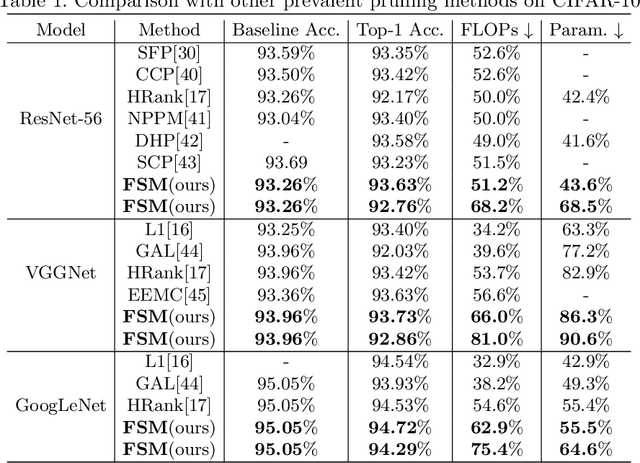
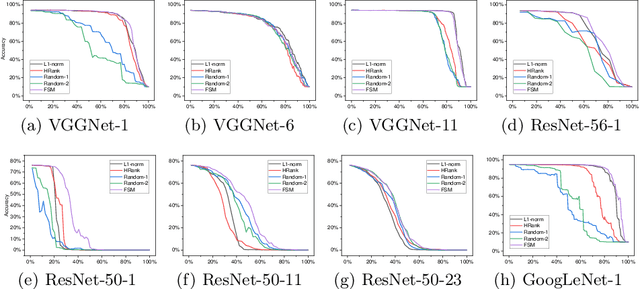
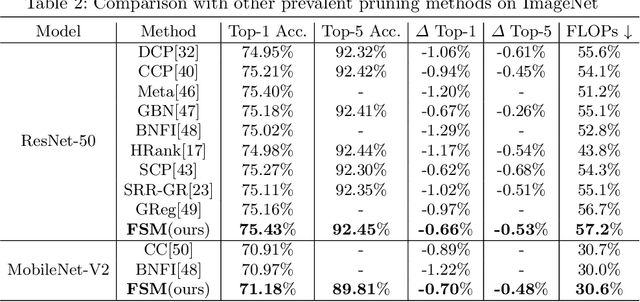
Channel pruning is widely used to reduce the complexity of deep network models. Recent pruning methods usually identify which parts of the network to discard by proposing a channel importance criterion. However, recent studies have shown that these criteria do not work well in all conditions. In this paper, we propose a novel Feature Shift Minimization (FSM) method to compress CNN models, which evaluates the feature shift by converging the information of both features and filters. Specifically, we first investigate the compression efficiency with some prevalent methods in different layer-depths and then propose the feature shift concept. Then, we introduce an approximation method to estimate the magnitude of the feature shift, since it is difficult to compute it directly. Besides, we present a distribution-optimization algorithm to compensate for the accuracy loss and improve the network compression efficiency. The proposed method yields state-of-the-art performance on various benchmark networks and datasets, verified by extensive experiments. The codes can be available at \url{https://github.com/lscgx/FSM}.
Network Compression via Central Filter
Dec 13, 2021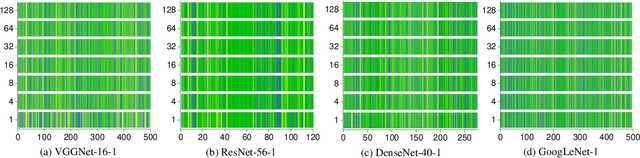
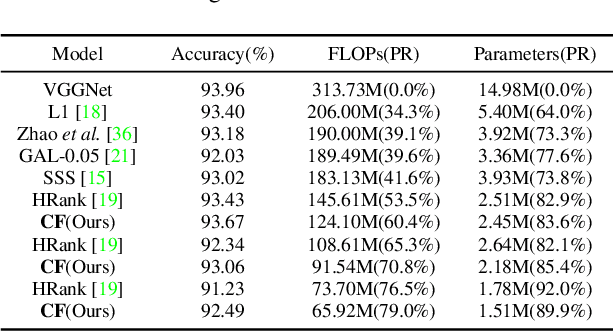
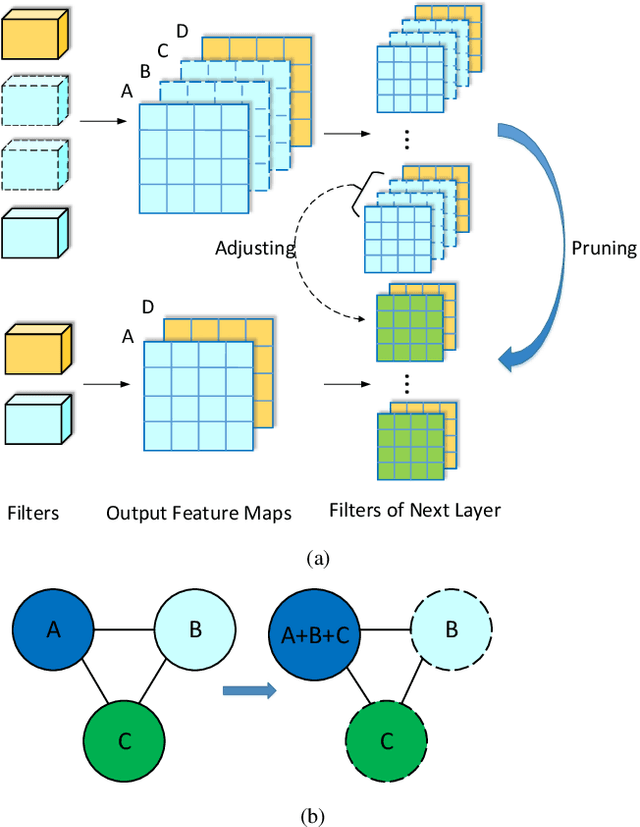
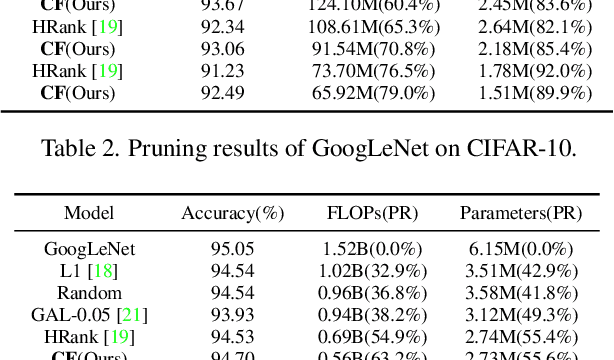
Neural network pruning has remarkable performance for reducing the complexity of deep network models. Recent network pruning methods usually focused on removing unimportant or redundant filters in the network. In this paper, by exploring the similarities between feature maps, we propose a novel filter pruning method, Central Filter (CF), which suggests that a filter is approximately equal to a set of other filters after appropriate adjustments. Our method is based on the discovery that the average similarity between feature maps changes very little, regardless of the number of input images. Based on this finding, we establish similarity graphs on feature maps and calculate the closeness centrality of each node to select the Central Filter. Moreover, we design a method to directly adjust weights in the next layer corresponding to the Central Filter, effectively minimizing the error caused by pruning. Through experiments on various benchmark networks and datasets, CF yields state-of-the-art performance. For example, with ResNet-56, CF reduces approximately 39.7% of FLOPs by removing 47.1% of the parameters, with even 0.33% accuracy improvement on CIFAR-10. With GoogLeNet, CF reduces approximately 63.2% of FLOPs by removing 55.6% of the parameters, with only a small loss of 0.35% in top-1 accuracy on CIFAR-10. With ResNet-50, CF reduces approximately 47.9% of FLOPs by removing 36.9% of the parameters, with only a small loss of 1.07% in top-1 accuracy on ImageNet. The codes can be available at https://github.com/8ubpshLR23/Central-Filter.