 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster, Cheaper, More Accurate: Specialised Knowledge Tracing Models Outperform LLMs
Mar 03, 2026Predicting future student responses to questions is particularly valuable for educational learning platforms where it enables effective interventions. One of the key approaches to do this has been through the use of knowledge tracing (KT) models. These are small, domain-specific, temporal models trained on student question-response data. KT models are optimised for high accuracy on specific educational domains and have fast inference and scalable deployments. The rise of Large Language Models (LLMs) motivates us to ask the following questions: (1) How well can LLMs perform at predicting students' future responses to questions? (2) Are LLMs scalable for this domain? (3) How do LLMs compare to KT models on this domain-specific task? In this paper, we compare multiple LLMs and KT models across predictive performance, deployment cost, and inference speed to answer the above questions. We show that KT models outperform LLMs with respect to accuracy and F1 scores on this domain-specific task. Further, we demonstrate that LLMs are orders of magnitude slower than KT models and cost orders of magnitude more to deploy. This highlights the importance of domain-specific models for education prediction tasks and the fact that current closed source LLMs should not be used as a universal solution for all tasks.
Letting Tutor Personas "Speak Up" for LLMs: Learning Steering Vectors from Dialogue via Preference Optimization
Feb 07, 2026With the emergence of large language models (LLMs) as a powerful class of generative artificial intelligence (AI), their use in tutoring has become increasingly prominent. Prior works on LLM-based tutoring typically learn a single tutor policy and do not capture the diversity of tutoring styles. In real-world tutor-student interactions, pedagogical intent is realized through adaptive instructional strategies, with tutors varying the level of scaffolding, instructional directiveness, feedback, and affective support in response to learners' needs. These differences can all impact dialogue dynamics and student engagement. In this paper, we explore how tutor personas embedded in human tutor-student dialogues can be used to guide LLM behavior without relying on explicitly prompted instructions. We modify Bidirectional Preference Optimization (BiPO) to learn a steering vector, an activation-space direction that steers model responses towards certain tutor personas. We find that this steering vector captures tutor-specific variation across dialogue contexts, improving semantic alignment with ground-truth tutor utterances and increasing preference-based evaluations, while largely preserving lexical similarity. Analysis of the learned directional coefficients further reveals interpretable structure across tutors, corresponding to consistent differences in tutoring behavior. These results demonstrate that activation steering offers an effective and interpretable way for controlling tutor-specific variation in LLMs using signals derived directly from human dialogue data.
Misconception Diagnosis From Student-Tutor Dialogue: Generate, Retrieve, Rerank
Feb 02, 2026Timely and accurate identification of student misconceptions is key to improving learning outcomes and pre-empting the compounding of student errors. However, this task is highly dependent on the effort and intuition of the teacher. In this work, we present a novel approach for detecting misconceptions from student-tutor dialogues using large language models (LLMs). First, we use a fine-tuned LLM to generate plausible misconceptions, and then retrieve the most promising candidates among these using embedding similarity with the input dialogue. These candidates are then assessed and re-ranked by another fine-tuned LLM to improve misconception relevance. Empirically, we evaluate our system on real dialogues from an educational tutoring platform. We consider multiple base LLM models including LLaMA, Qwen and Claude on zero-shot and fine-tuned settings. We find that our approach improves predictive performance over baseline models and that fine-tuning improves both generated misconception quality and can outperform larger closed-source models. Finally, we conduct ablation studies to both validate the importance of our generation and reranking steps on misconception generation quality.
Simulated Students in Tutoring Dialogues: Substance or Illusion?
Jan 07, 2026Advances in large language models (LLMs) enable many new innovations in education. However, evaluating the effectiveness of new technology requires real students, which is time-consuming and hard to scale up. Therefore, many recent works on LLM-powered tutoring solutions have used simulated students for both training and evaluation, often via simple prompting. Surprisingly, little work has been done to ensure or even measure the quality of simulated students. In this work, we formally define the student simulation task, propose a set of evaluation metrics that span linguistic, behavioral, and cognitive aspects, and benchmark a wide range of student simulation methods on these metrics. We experiment on a real-world math tutoring dialogue dataset, where both automated and human evaluation results show that prompting strategies for student simulation perform poorly; supervised fine-tuning and preference optimization yield much better but still limited performance, motivating future work on this challenging task.
AI tutoring can safely and effectively support students: An exploratory RCT in UK classrooms
Dec 29, 2025One-to-one tutoring is widely considered the gold standard for personalized education, yet it remains prohibitively expensive to scale. To evaluate whether generative AI might help expand access to this resource, we conducted an exploratory randomized controlled trial (RCT) with $N = 165$ students across five UK secondary schools. We integrated LearnLM -- a generative AI model fine-tuned for pedagogy -- into chat-based tutoring sessions on the Eedi mathematics platform. In the RCT, expert tutors directly supervised LearnLM, with the remit to revise each message it drafted until they would be satisfied sending it themselves. LearnLM proved to be a reliable source of pedagogical instruction, with supervising tutors approving 76.4% of its drafted messages making zero or minimal edits (i.e., changing only one or two characters). This translated into effective tutoring support: students guided by LearnLM performed at least as well as students chatting with human tutors on each learning outcome we measured. In fact, students who received support from LearnLM were 5.5 percentage points more likely to solve novel problems on subsequent topics (with a success rate of 66.2%) than those who received tutoring from human tutors alone (rate of 60.7%). In interviews, tutors highlighted LearnLM's strength at drafting Socratic questions that encouraged deeper reflection from students, with multiple tutors even reporting that they learned new pedagogical practices from the model. Overall, our results suggest that pedagogically fine-tuned AI tutoring systems may play a promising role in delivering effective, individualized learning support at scale.
PIIvot: A Lightweight NLP Anonymization Framework for Question-Anchored Tutoring Dialogues
May 22, 2025Personally identifiable information (PII) anonymization is a high-stakes task that poses a barrier to many open-science data sharing initiatives. While PII identification has made large strides in recent years, in practice, error thresholds and the recall/precision trade-off still limit the uptake of these anonymization pipelines. We present PIIvot, a lighter-weight framework for PII anonymization that leverages knowledge of the data context to simplify the PII detection problem. To demonstrate its effectiveness, we also contribute QATD-2k, the largest open-source real-world tutoring dataset of its kind, to support the demand for quality educational dialogue data.
LookAlike: Consistent Distractor Generation in Math MCQs
May 03, 2025



Large language models (LLMs) are increasingly used to generate distractors for multiple-choice questions (MCQs), especially in domains like math education. However, existing approaches are limited in ensuring that the generated distractors are consistent with common student errors. We propose LookAlike, a method that improves error-distractor consistency via preference optimization. Our two main innovations are: (a) mining synthetic preference pairs from model inconsistencies, and (b) alternating supervised fine-tuning (SFT) with Direct Preference Optimization (DPO) to stabilize training. Unlike prior work that relies on heuristics or manually annotated preference data, LookAlike uses its own generation inconsistencies as dispreferred samples, thus enabling scalable and stable training. Evaluated on a real-world dataset of 1,400+ math MCQs, LookAlike achieves 51.6% accuracy in distractor generation and 57.2% in error generation under LLM-as-a-judge evaluation, outperforming an existing state-of-the-art method (45.6% / 47.7%). These improvements highlight the effectiveness of preference-based regularization and inconsistency mining for generating consistent math MCQ distractors at scale.
DiVERT: Distractor Generation with Variational Errors Represented as Text for Math Multiple-choice Questions
Jun 27, 2024



High-quality distractors are crucial to both the assessment and pedagogical value of multiple-choice questions (MCQs), where manually crafting ones that anticipate knowledge deficiencies or misconceptions among real students is difficult. Meanwhile, automated distractor generation, even with the help of large language models (LLMs), remains challenging for subjects like math. It is crucial to not only identify plausible distractors but also understand the error behind them. In this paper, we introduce DiVERT (Distractor Generation with Variational Errors Represented as Text), a novel variational approach that learns an interpretable representation of errors behind distractors in math MCQs. Through experiments on a real-world math MCQ dataset with 1,434 questions used by hundreds of thousands of students, we show that DiVERT, despite using a base open-source LLM with 7B parameters, outperforms state-of-the-art approaches using GPT-4o on downstream distractor generation. We also conduct a human evaluation with math educators and find that DiVERT leads to error labels that are of comparable quality to human-authored ones.
Math Multiple Choice Question Generation via Human-Large Language Model Collaboration
May 01, 2024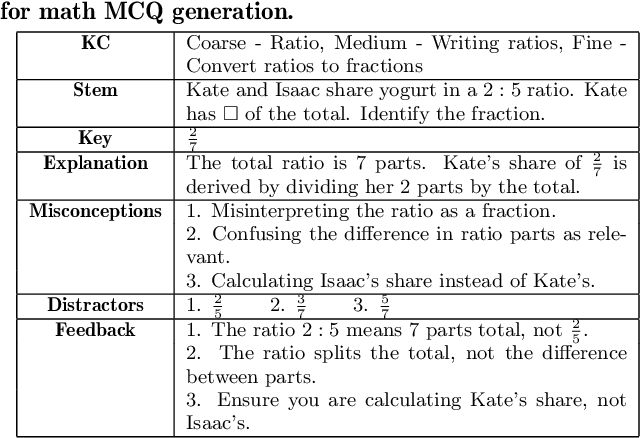

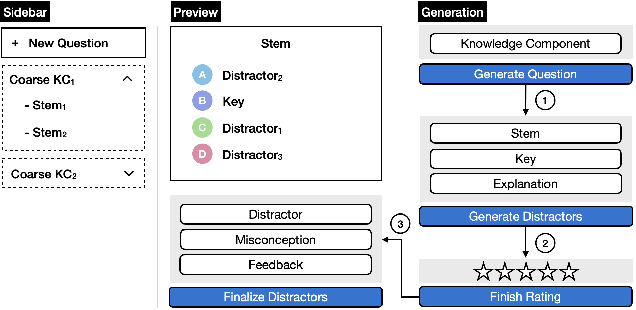

Multiple choice questions (MCQs) are a popular method for evaluating students' knowledge due to their efficiency in administration and grading. Crafting high-quality math MCQs is a labor-intensive process that requires educators to formulate precise stems and plausible distractors. Recent advances in large language models (LLMs) have sparked interest in automating MCQ creation, but challenges persist in ensuring mathematical accuracy and addressing student errors. This paper introduces a prototype tool designed to facilitate collaboration between LLMs and educators for streamlining the math MCQ generation process. We conduct a pilot study involving math educators to investigate how the tool can help them simplify the process of crafting high-quality math MCQs. We found that while LLMs can generate well-formulated question stems, their ability to generate distractors that capture common student errors and misconceptions is limited. Nevertheless, a human-AI collaboration has the potential to enhance the efficiency and effectiveness of MCQ generation.
Exploring Automated Distractor Generation for Math Multiple-choice Questions via Large Language Models
Apr 05, 2024



Multiple-choice questions (MCQs) are ubiquitous in almost all levels of education since they are easy to administer, grade, and are a reliable format in assessments and practices. One of the most important aspects of MCQs is the distractors, i.e., incorrect options that are designed to target common errors or misconceptions among real students. To date, the task of crafting high-quality distractors largely remains a labor and time-intensive process for teachers and learning content designers, which has limited scalability. In this work, we study the task of automated distractor generation in the domain of math MCQs and explore a wide variety of large language model (LLM)-based approaches, from in-context learning to fine-tuning. We conduct extensive experiments using a real-world math MCQ dataset and find that although LLMs can generate some mathematically valid distractors, they are less adept at anticipating common errors or misconceptions among real students.