 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Sound Differentiable Programming in a Functional Array-Processing Language
Dec 20, 2022Automatic differentiation (AD) is a technique for computing the derivative of a function represented by a program. This technique is considered as the de-facto standard for computing the differentiation in many machine learning and optimisation software tools. Despite the practicality of this technique, the performance of the differentiated programs, especially for functional languages and in the presence of vectors, is suboptimal. We present an AD system for a higher-order functional array-processing language. The core functional language underlying this system simultaneously supports both source-to-source forward-mode AD and global optimisations such as loop transformations. In combination, gradient computation with forward-mode AD can be as efficient as reverse mode, and the Jacobian matrices required for numerical algorithms such as Gauss-Newton and Levenberg-Marquardt can be efficiently computed.
VICause: Simultaneous Missing Value Imputation and Causal Discovery with Groups
Oct 15, 2021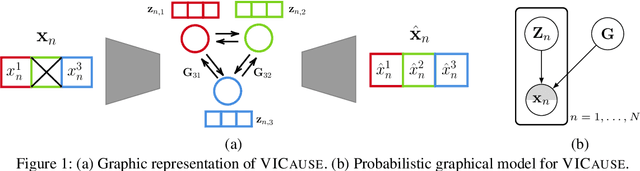
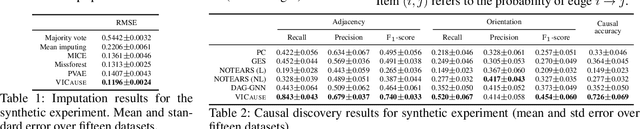
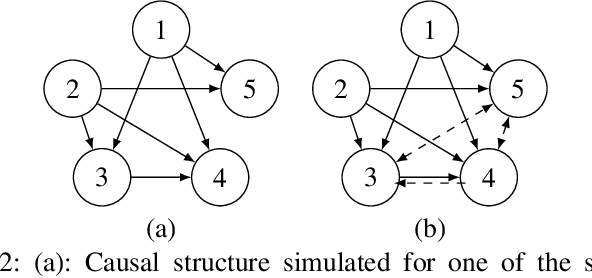
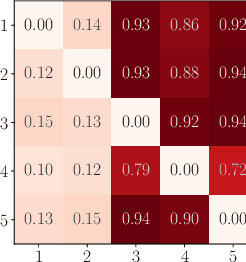
Missing values constitute an important challenge in real-world machine learning for both prediction and causal discovery tasks. However, existing imputation methods are agnostic to causality, while only few methods in traditional causal discovery can handle missing data in an efficient way. In this work we propose VICause, a novel approach to simultaneously tackle missing value imputation and causal discovery efficiently with deep learning. Particularly, we propose a generative model with a structured latent space and a graph neural network-based architecture, scaling to large number of variables. Moreover, our method can discover relationships between groups of variables which is useful in many real-world applications. VICause shows improved performance compared to popular and recent approaches in both missing value imputation and causal discovery.
CoRGi: Content-Rich Graph Neural Networks with Attention
Oct 10, 2021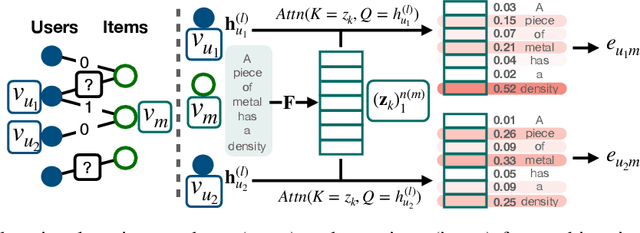

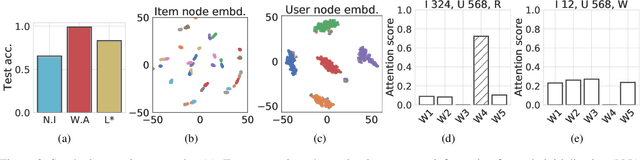
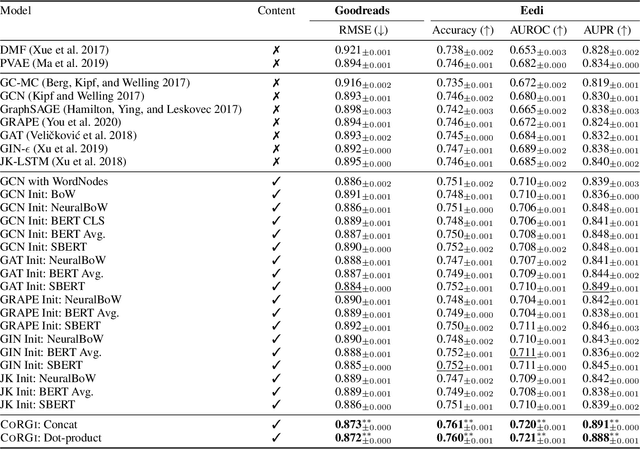
Graph representations of a target domain often project it to a set of entities (nodes) and their relations (edges). However, such projections often miss important and rich information. For example, in graph representations used in missing value imputation, items - represented as nodes - may contain rich textual information. However, when processing graphs with graph neural networks (GNN), such information is either ignored or summarized into a single vector representation used to initialize the GNN. Towards addressing this, we present CoRGi, a GNN that considers the rich data within nodes in the context of their neighbors. This is achieved by endowing CoRGi's message passing with a personalized attention mechanism over the content of each node. This way, CoRGi assigns user-item-specific attention scores with respect to the words that appear in an item's content. We evaluate CoRGi on two edge-value prediction tasks and show that CoRGi is better at making edge-value predictions over existing methods, especially on sparse regions of the graph.
Diagnostic Questions:The NeurIPS 2020 Education Challenge
Aug 03, 2020

Digital technologies are becoming increasingly prevalent in education, enabling personalized, high quality education resources to be accessible by students across the world. Importantly, among these resources are diagnostic questions: the answers that the students give to these questions reveal key information about the specific nature of misconceptions that the students may hold. Analyzing the massive quantities of data stemming from students' interactions with these diagnostic questions can help us more accurately understand the students' learning status and thus allow us to automate learning curriculum recommendations. In this competition, participants will focus on the students' answer records to these multiple-choice diagnostic questions, with the aim of 1) accurately predicting which answers the students provide; 2) accurately predicting which questions have high quality; and 3) determining a personalized sequence of questions for each student that best predicts the student's answers. These tasks closely mimic the goals of a real-world educational platform and are highly representative of the educational challenges faced today. We provide over 20 million examples of students' answers to mathematics questions from Eedi, a leading educational platform which thousands of students interact with daily around the globe. Participants to this competition have a chance to make a lasting, real-world impact on the quality of personalized education for millions of students across the world.
Large-Scale Educational Question Analysis with Partial Variational Auto-encoders
Mar 12, 2020
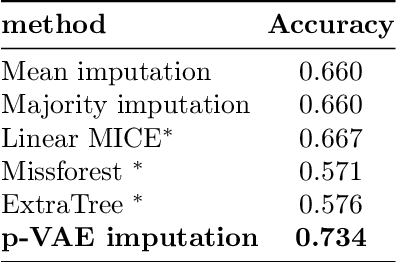
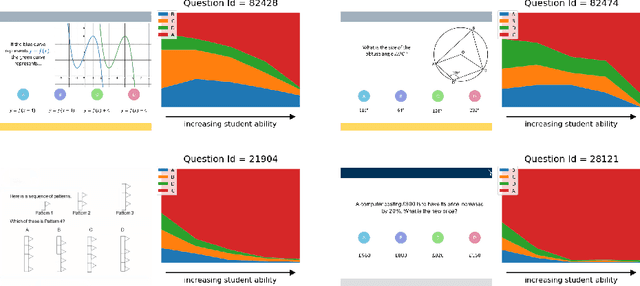
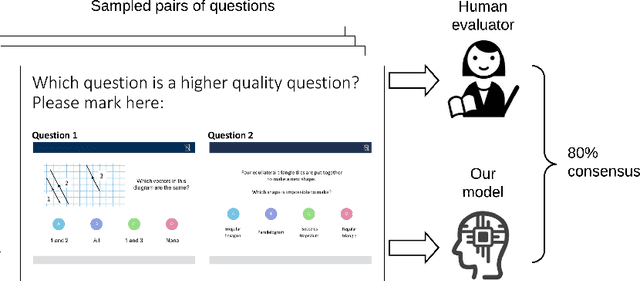
Online education platforms enable teachers to share a large number of educational resources such as questions to form exercises and quizzes for students. With large volumes of such crowd-sourced questions, quantifying the properties of these questions in crowd-sourced online education platforms is of great importance to enable both teachers and students to find high-quality and suitable resources. In this work, we propose a framework for large-scale question analysis. We utilize the state-of-the-art Bayesian deep learning method, in particular partial variational auto-encoders, to analyze real-world educational data. We also develop novel objectives to quantify question quality and difficulty. We apply our proposed framework to a real-world cohort with millions of question-answer pairs from an online education platform. Our framework not only demonstrates promising results in terms of statistical metrics but also obtains highly consistent results with domain expert evaluation.
Efficient Differentiable Programming in a Functional Array-Processing Language
Jun 06, 2018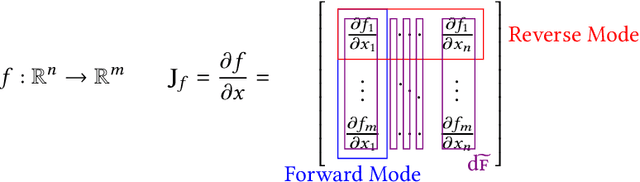

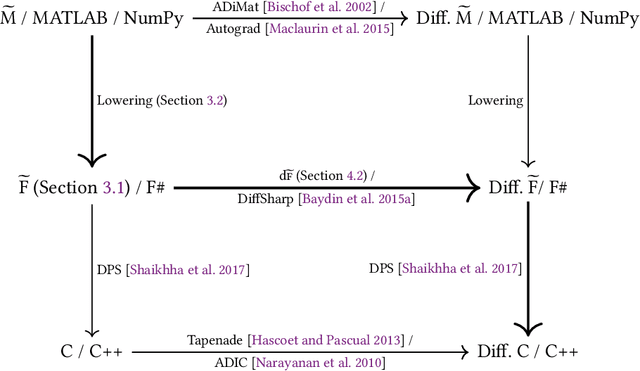

We present a system for the automatic differentiation of a higher-order functional array-processing language. The core functional language underlying this system simultaneously supports both source-to-source automatic differentiation and global optimizations such as loop transformations. Thanks to this feature, we demonstrate how for some real-world machine learning and computer vision benchmarks, the system outperforms the state-of-the-art automatic differentiation tools.