 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Programming with Programmable Variational Inference
Jun 22, 2024
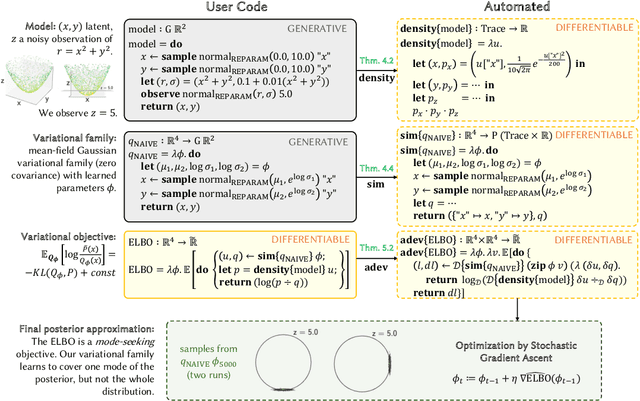

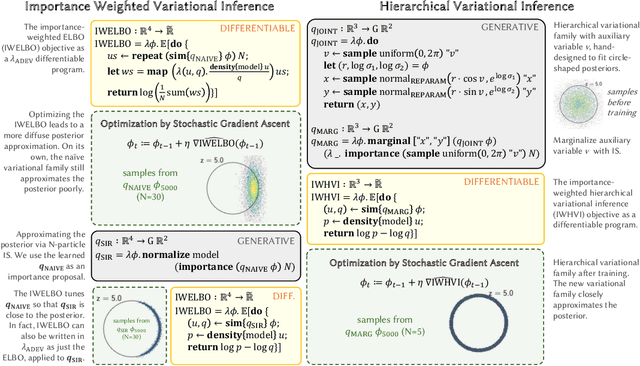
Compared to the wide array of advanced Monte Carlo methods supported by modern probabilistic programming languages (PPLs), PPL support for variational inference (VI) is less developed: users are typically limited to a predefined selection of variational objectives and gradient estimators, which are implemented monolithically (and without formal correctness arguments) in PPL backends. In this paper, we propose a more modular approach to supporting variational inference in PPLs, based on compositional program transformation. In our approach, variational objectives are expressed as programs, that may employ first-class constructs for computing densities of and expected values under user-defined models and variational families. We then transform these programs systematically into unbiased gradient estimators for optimizing the objectives they define. Our design enables modular reasoning about many interacting concerns, including automatic differentiation, density accumulation, tracing, and the application of unbiased gradient estimation strategies. Additionally, relative to existing support for VI in PPLs, our design increases expressiveness along three axes: (1) it supports an open-ended set of user-defined variational objectives, rather than a fixed menu of options; (2) it supports a combinatorial space of gradient estimation strategies, many not automated by today's PPLs; and (3) it supports a broader class of models and variational families, because it supports constructs for approximate marginalization and normalization (previously introduced only for Monte Carlo inference). We implement our approach in an extension to the Gen probabilistic programming system (genjax.vi, implemented in JAX), and evaluate on several deep generative modeling tasks, showing minimal performance overhead vs. hand-coded implementations and performance competitive with well-established open-source PPLs.
Differentiating Metropolis-Hastings to Optimize Intractable Densities
Jun 30, 2023We develop an algorithm for automatic differentiation of Metropolis-Hastings samplers, allowing us to differentiate through probabilistic inference, even if the model has discrete components within it. Our approach fuses recent advances in stochastic automatic differentiation with traditional Markov chain coupling schemes, providing an unbiased and low-variance gradient estimator. This allows us to apply gradient-based optimization to objectives expressed as expectations over intractable target densities. We demonstrate our approach by finding an ambiguous observation in a Gaussian mixture model and by maximizing the specific heat in an Ising model.
$ abla$SD: Differentiable Programming for Sparse Tensors
Mar 13, 2023
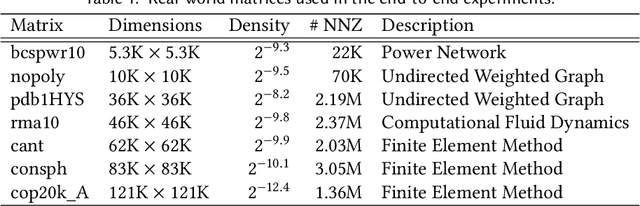
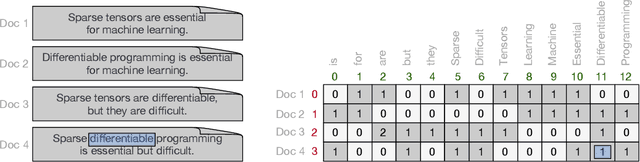
Sparse tensors are prevalent in many data-intensive applications, yet existing differentiable programming frameworks are tailored towards dense tensors. This presents a significant challenge for efficiently computing gradients through sparse tensor operations, as their irregular sparsity patterns can result in substantial memory and computational overheads. In this work, we introduce a novel framework that enables the efficient and automatic differentiation of sparse tensors, addressing this fundamental issue. Our experiments demonstrate the effectiveness of the proposed framework in terms of performance and scalability, outperforming state-of-the-art frameworks across a range of synthetic and real-world datasets. Our approach offers a promising direction for enabling efficient and scalable differentiable programming with sparse tensors, which has significant implications for numerous applications in machine learning, natural language processing, and scientific computing.
$ω$PAP Spaces: Reasoning Denotationally About Higher-Order, Recursive Probabilistic and Differentiable Programs
Feb 21, 2023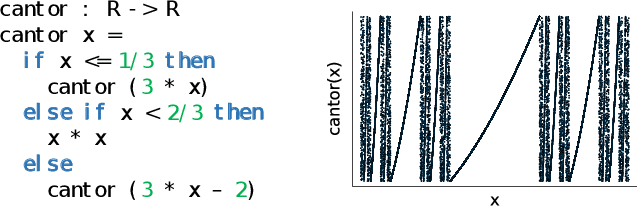


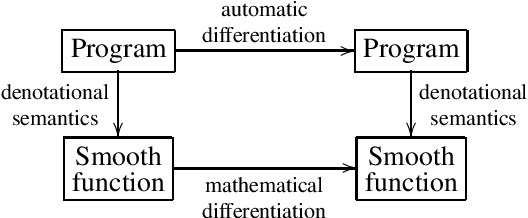
We introduce a new setting, the category of $\omega$PAP spaces, for reasoning denotationally about expressive differentiable and probabilistic programming languages. Our semantics is general enough to assign meanings to most practical probabilistic and differentiable programs, including those that use general recursion, higher-order functions, discontinuous primitives, and both discrete and continuous sampling. But crucially, it is also specific enough to exclude many pathological denotations, enabling us to establish new results about both deterministic differentiable programs and probabilistic programs. In the deterministic setting, we prove very general correctness theorems for automatic differentiation and its use within gradient descent. In the probabilistic setting, we establish the almost-everywhere differentiability of probabilistic programs' trace density functions, and the existence of convenient base measures for density computation in Monte Carlo inference. In some cases these results were previously known, but required detailed proofs with an operational flavor; by contrast, all our proofs work directly with programs' denotations.
Efficient and Sound Differentiable Programming in a Functional Array-Processing Language
Dec 20, 2022Automatic differentiation (AD) is a technique for computing the derivative of a function represented by a program. This technique is considered as the de-facto standard for computing the differentiation in many machine learning and optimisation software tools. Despite the practicality of this technique, the performance of the differentiated programs, especially for functional languages and in the presence of vectors, is suboptimal. We present an AD system for a higher-order functional array-processing language. The core functional language underlying this system simultaneously supports both source-to-source forward-mode AD and global optimisations such as loop transformations. In combination, gradient computation with forward-mode AD can be as efficient as reverse mode, and the Jacobian matrices required for numerical algorithms such as Gauss-Newton and Levenberg-Marquardt can be efficiently computed.
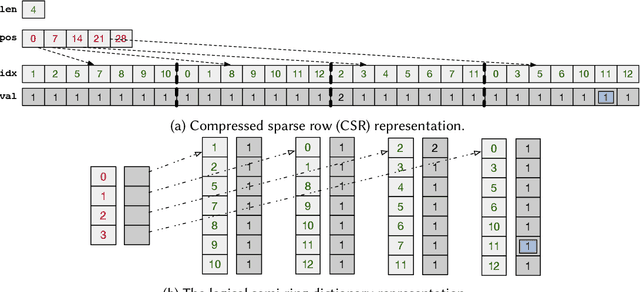
Functional Collection Programming with Semi-Ring Dictionaries
Mar 10, 2021



This paper introduces semi-ring dictionaries, a powerful class of compositional and purely functional collections that subsume other collection types such as sets, multisets, arrays, vectors, and matrices. We develop SDQL, a statically typed language centered around semi-ring dictionaries, that can encode expressions in relational algebra with aggregations, functional collections, and linear algebra. Furthermore, thanks to the semi-ring algebraic structures behind these dictionaries, SDQL unifies a wide range of optimizations commonly used in databases and linear algebra. As a result, SDQL enables efficient processing of hybrid database and linear algebra workloads, by putting together optimizations that are otherwise confined to either database systems or linear algebra frameworks. Through experimental results, we show that a handful of relational and linear algebra workloads can take advantage of the SDQL language and optimizations. Overall, we observe that SDQL achieves competitive performance to Typer and Tectorwise, which are state-of-the-art in-memory systems for (flat, not nested) relational data, and achieves an average 2x speedup over SciPy for linear algebra workloads. Finally, for hybrid workloads involving linear algebra processing over nested biomedical data, SDQL can give up to one order of magnitude speedup over Trance, a state-of-the-art nested relational engine.