 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Forgetting in Low Rank Adaptation
Dec 19, 2025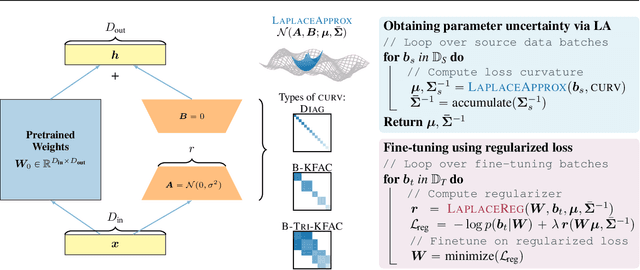

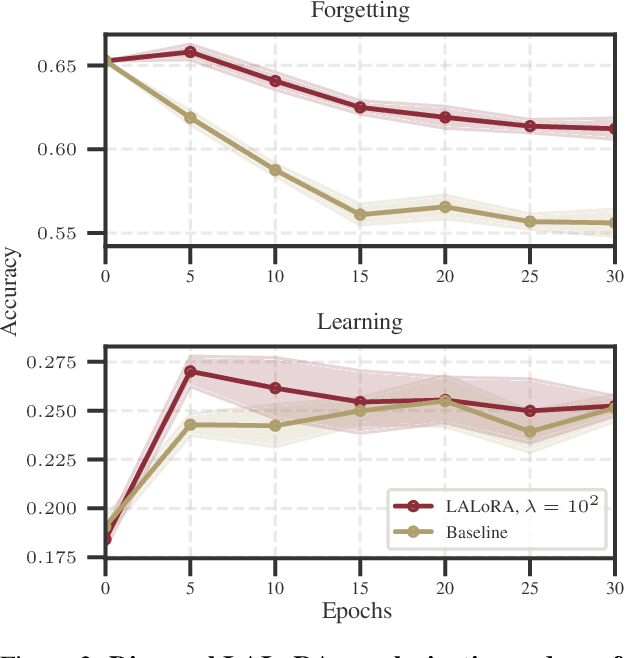
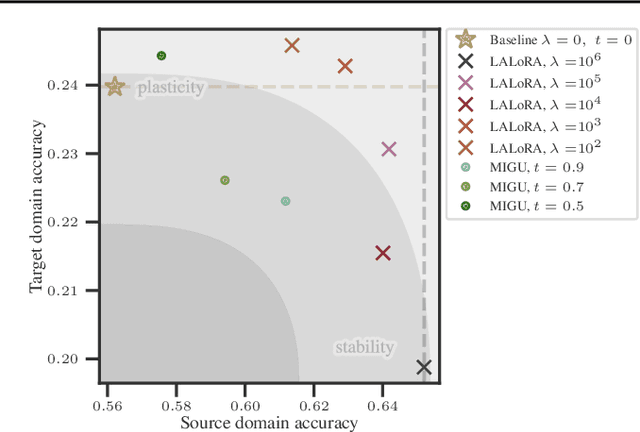
Parameter-efficient fine-tuning methods, such as Low-Rank Adaptation (LoRA), enable fast specialization of large pre-trained models to different downstream applications. However, this process often leads to catastrophic forgetting of the model's prior domain knowledge. We address this issue with LaLoRA, a weight-space regularization technique that applies a Laplace approximation to Low-Rank Adaptation. Our approach estimates the model's confidence in each parameter and constrains updates in high-curvature directions, preserving prior knowledge while enabling efficient target-domain learning. By applying the Laplace approximation only to the LoRA weights, the method remains lightweight. We evaluate LaLoRA by fine-tuning a Llama model for mathematical reasoning and demonstrate an improved learning-forgetting trade-off, which can be directly controlled via the method's regularization strength. We further explore different loss landscape curvature approximations for estimating parameter confidence, analyze the effect of the data used for the Laplace approximation, and study robustness across hyperparameters.
Weighted Conditional Flow Matching
Jul 29, 2025Conditional flow matching (CFM) has emerged as a powerful framework for training continuous normalizing flows due to its computational efficiency and effectiveness. However, standard CFM often produces paths that deviate significantly from straight-line interpolations between prior and target distributions, making generation slower and less accurate due to the need for fine discretization at inference. Recent methods enhance CFM performance by inducing shorter and straighter trajectories but typically rely on computationally expensive mini-batch optimal transport (OT). Drawing insights from entropic optimal transport (EOT), we propose Weighted Conditional Flow Matching (W-CFM), a novel approach that modifies the classical CFM loss by weighting each training pair $(x, y)$ with a Gibbs kernel. We show that this weighting recovers the entropic OT coupling up to some bias in the marginals, and we provide the conditions under which the marginals remain nearly unchanged. Moreover, we establish an equivalence between W-CFM and the minibatch OT method in the large-batch limit, showing how our method overcomes computational and performance bottlenecks linked to batch size. Empirically, we test our method on unconditional generation on various synthetic and real datasets, confirming that W-CFM achieves comparable or superior sample quality, fidelity, and diversity to other alternative baselines while maintaining the computational efficiency of vanilla CFM.
Post-Hoc Uncertainty Quantification in Pre-Trained Neural Networks via Activation-Level Gaussian Processes
Feb 28, 2025


Uncertainty quantification in neural networks through methods such as Dropout, Bayesian neural networks and Laplace approximations is either prone to underfitting or computationally demanding, rendering these approaches impractical for large-scale datasets. In this work, we address these shortcomings by shifting the focus from uncertainty in the weight space to uncertainty at the activation level, via Gaussian processes. More specifically, we introduce the Gaussian Process Activation function (GAPA) to capture neuron-level uncertainties. Our approach operates in a post-hoc manner, preserving the original mean predictions of the pre-trained neural network and thereby avoiding the underfitting issues commonly encountered in previous methods. We propose two methods. The first, GAPA-Free, employs empirical kernel learning from the training data for the hyperparameters and is highly efficient during training. The second, GAPA-Variational, learns the hyperparameters via gradient descent on the kernels, thus affording greater flexibility. Empirical results demonstrate that GAPA-Variational outperforms the Laplace approximation on most datasets in at least one of the uncertainty quantification metrics.
Observation Noise and Initialization in Wide Neural Networks
Feb 03, 2025Performing gradient descent in a wide neural network is equivalent to computing the posterior mean of a Gaussian Process with the Neural Tangent Kernel (NTK-GP), for a specific choice of prior mean and with zero observation noise. However, existing formulations of this result have two limitations: i) the resultant NTK-GP assumes no noise in the observed target variables, which can result in suboptimal predictions with noisy data; ii) it is unclear how to extend the equivalence to an arbitrary prior mean, a crucial aspect of formulating a well-specified model. To address the first limitation, we introduce a regularizer into the neural network's training objective, formally showing its correspondence to incorporating observation noise into the NTK-GP model. To address the second, we introduce a \textit{shifted network} that enables arbitrary prior mean functions. This approach allows us to perform gradient descent on a single neural network, without expensive ensembling or kernel matrix inversion. Our theoretical insights are validated empirically, with experiments exploring different values of observation noise and network architectures.
Uncertainty Modeling in Graph Neural Networks via Stochastic Differential Equations
Sep 01, 2024



We address the problem of learning uncertainty-aware representations for graph-structured data. While Graph Neural Ordinary Differential Equations (GNODE) are effective in learning node representations, they fail to quantify uncertainty. To address this, we introduce Latent Graph Neural Stochastic Differential Equations (LGNSDE), which enhance GNODE by embedding randomness through Brownian motion to quantify uncertainty. We provide theoretical guarantees for LGNSDE and empirically show better performance in uncertainty quantification.
Feature Attribution with Necessity and Sufficiency via Dual-stage Perturbation Test for Causal Explanation
Feb 13, 2024We investigate the problem of explainability in machine learning.To address this problem, Feature Attribution Methods (FAMs) measure the contribution of each feature through a perturbation test, where the difference in prediction is compared under different perturbations.However, such perturbation tests may not accurately distinguish the contributions of different features, when their change in prediction is the same after perturbation.In order to enhance the ability of FAMs to distinguish different features' contributions in this challenging setting, we propose to utilize the probability (PNS) that perturbing a feature is a necessary and sufficient cause for the prediction to change as a measure of feature importance.Our approach, Feature Attribution with Necessity and Sufficiency (FANS), computes the PNS via a perturbation test involving two stages (factual and interventional).In practice, to generate counterfactual samples, we use a resampling-based approach on the observed samples to approximate the required conditional distribution.Finally, we combine FANS and gradient-based optimization to extract the subset with the largest PNS.We demonstrate that FANS outperforms existing feature attribution methods on six benchmarks.
Graph Neural Stochastic Differential Equations
Aug 23, 2023



We present a novel model Graph Neural Stochastic Differential Equations (Graph Neural SDEs). This technique enhances the Graph Neural Ordinary Differential Equations (Graph Neural ODEs) by embedding randomness into data representation using Brownian motion. This inclusion allows for the assessment of prediction uncertainty, a crucial aspect frequently missed in current models. In our framework, we spotlight the \textit{Latent Graph Neural SDE} variant, demonstrating its effectiveness. Through empirical studies, we find that Latent Graph Neural SDEs surpass conventional models like Graph Convolutional Networks and Graph Neural ODEs, especially in confidence prediction, making them superior in handling out-of-distribution detection across both static and spatio-temporal contexts.
Large-Scale Educational Question Analysis with Partial Variational Auto-encoders
Mar 12, 2020
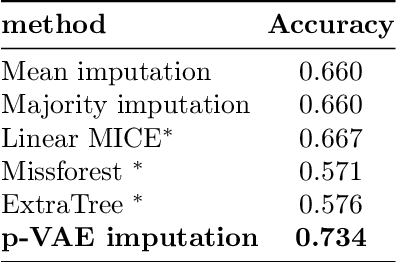
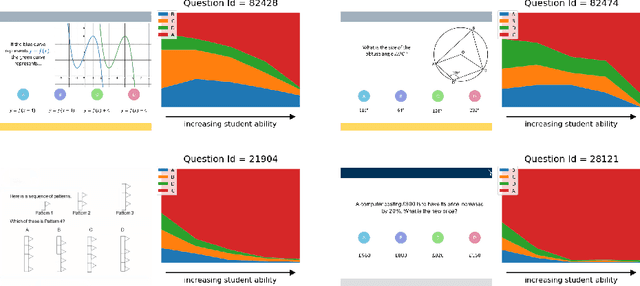
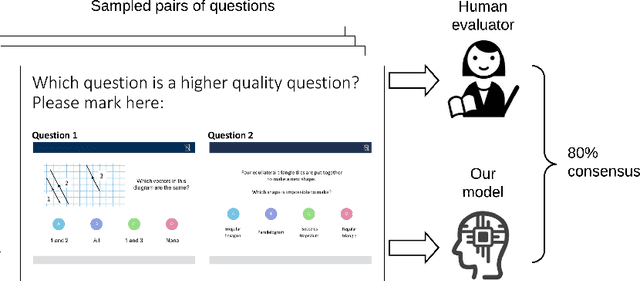
Online education platforms enable teachers to share a large number of educational resources such as questions to form exercises and quizzes for students. With large volumes of such crowd-sourced questions, quantifying the properties of these questions in crowd-sourced online education platforms is of great importance to enable both teachers and students to find high-quality and suitable resources. In this work, we propose a framework for large-scale question analysis. We utilize the state-of-the-art Bayesian deep learning method, in particular partial variational auto-encoders, to analyze real-world educational data. We also develop novel objectives to quantify question quality and difficulty. We apply our proposed framework to a real-world cohort with millions of question-answer pairs from an online education platform. Our framework not only demonstrates promising results in terms of statistical metrics but also obtains highly consistent results with domain expert evaluation.
Ergodic Measure Preserving Flows
Aug 13, 2018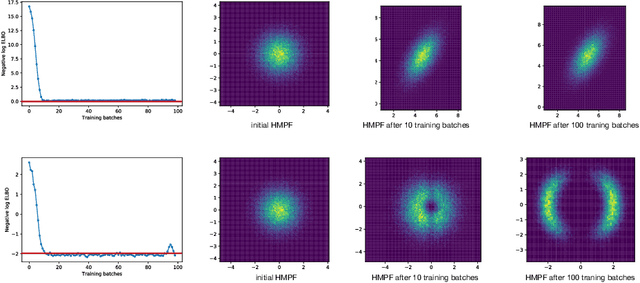
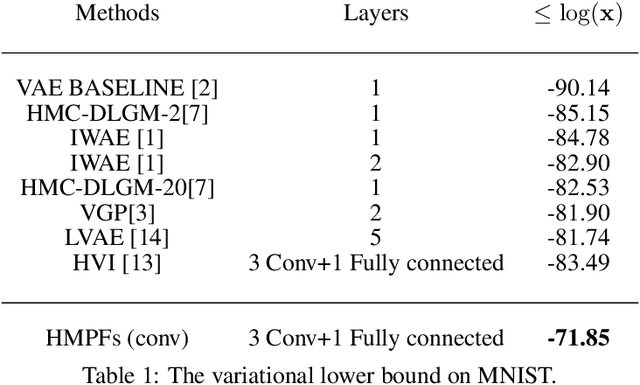
Probabilistic modelling is a general and elegant framework to capture the uncertainty, ambiguity and diversity of data. Probabilistic inference is the core technique for developing training and simulation algorithms on probabilistic models. However, the classic inference methods, like Markov chain Monte Carlo (MCMC) methods and mean-field variational inference (VI), are not computationally scalable for the recent developed probabilistic models with neural networks (NNs). This motivates many recent works on improving classic inference methods using NNs, especially, NN empowered VI. However, even with powerful NNs, VI still suffers its fundamental limitations. In this work, we propose a novel computational scalable general inference framework. With the theoretical foundation in ergodic theory, the proposed methods are not only computationally scalable like NN-based VI methods but also asymptotically accurate like MCMC. We test our method on popular benchmark problems and the results suggest that our methods can outperform NN-based VI and MCMC on deep generative models and Bayesian neural networks.
Stochastic Expectation Propagation
Nov 18, 2015
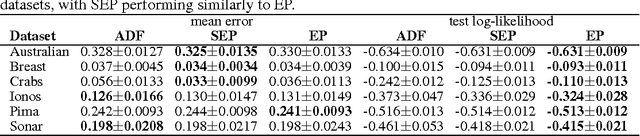
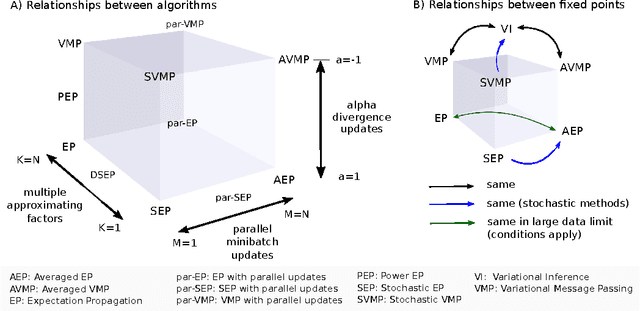
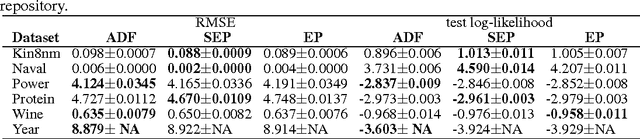
Expectation propagation (EP) is a deterministic approximation algorithm that is often used to perform approximate Bayesian parameter learning. EP approximates the full intractable posterior distribution through a set of local approximations that are iteratively refined for each datapoint. EP can offer analytic and computational advantages over other approximations, such as Variational Inference (VI), and is the method of choice for a number of models. The local nature of EP appears to make it an ideal candidate for performing Bayesian learning on large models in large-scale dataset settings. However, EP has a crucial limitation in this context: the number of approximating factors needs to increase with the number of data-points, N, which often entails a prohibitively large memory overhead. This paper presents an extension to EP, called stochastic expectation propagation (SEP), that maintains a global posterior approximation (like VI) but updates it in a local way (like EP). Experiments on a number of canonical learning problems using synthetic and real-world datasets indicate that SEP performs almost as well as full EP, but reduces the memory consumption by a factor of $N$. SEP is therefore ideally suited to performing approximate Bayesian learning in the large model, large dataset setting.