 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubmodular Evaluation Subset Selection in Automatic Prompt Optimization
Jan 07, 2026Automatic prompt optimization reduces manual prompt engineering, but relies on task performance measured on a small, often randomly sampled evaluation subset as its main source of feedback signal. Despite this, how to select that evaluation subset is usually treated as an implementation detail. We study evaluation subset selection for prompt optimization from a principled perspective and propose SESS, a submodular evaluation subset selection method. We frame selection as maximizing an objective set function and show that, under mild conditions, it is monotone and submodular, enabling greedy selection with theoretical guarantees. Across GSM8K, MATH, and GPQA-Diamond, submodularly selected evaluation subsets can yield better optimized prompts than random or heuristic baselines.
Compiler-Level Matrix Multiplication Optimization for Deep Learning
Sep 23, 2019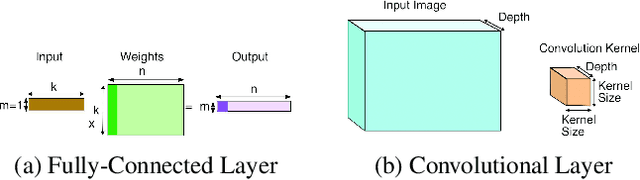
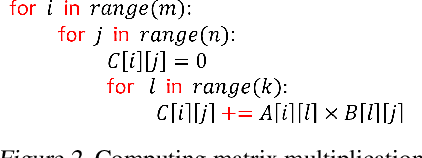
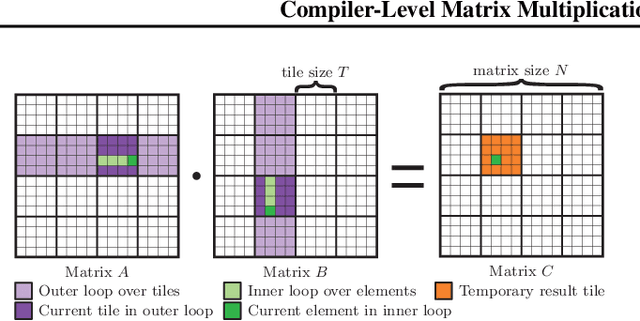

An important linear algebra routine, GEneral Matrix Multiplication (GEMM), is a fundamental operator in deep learning. Compilers need to translate these routines into low-level code optimized for specific hardware. Compiler-level optimization of GEMM has significant performance impact on training and executing deep learning models. However, most deep learning frameworks rely on hardware-specific operator libraries in which GEMM optimization has been mostly achieved by manual tuning, which restricts the performance on different target hardware. In this paper, we propose two novel algorithms for GEMM optimization based on the TVM framework, a lightweight Greedy Best First Search (G-BFS) method based on heuristic search, and a Neighborhood Actor Advantage Critic (N-A2C) method based on reinforcement learning. Experimental results show significant performance improvement of the proposed methods, in both the optimality of the solution and the cost of search in terms of time and fraction of the search space explored. Specifically, the proposed methods achieve 24% and 40% savings in GEMM computation time over state-of-the-art XGBoost and RNN methods, respectively, while exploring only 0.1% of the search space. The proposed approaches have potential to be applied to other operator-level optimizations.
Gradient-Coherent Strong Regularization for Deep Neural Networks
Nov 20, 2018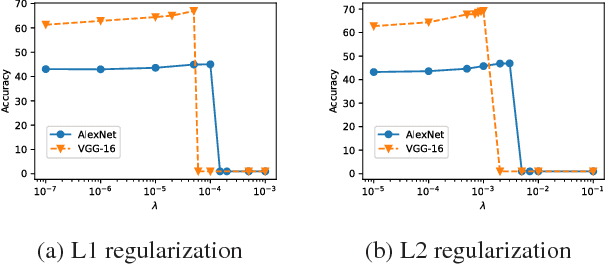
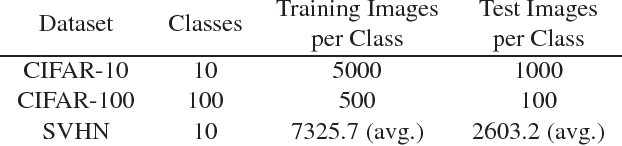

Deep neural networks are often prone to over-fitting with their numerous parameters, so regularization plays an important role in generalization. L1 and L2 regularizers are common regularization tools in machine learning with their simplicity and effectiveness. However, we observe that imposing strong L1 or L2 regularization on deep neural networks with stochastic gradient descent easily fails, which limits the generalization ability of the underlying neural networks. To understand this phenomenon, we first investigate how and why learning fails when strong regularization is imposed on deep neural networks. We then propose a novel method, gradient-coherent strong regularization, which imposes regularization only when the gradients are kept coherent in the presence of strong regularization. Experiments are performed with multiple deep architectures on three benchmark data sets for image recognition. Experimental results show that our proposed approach indeed endures strong regularization and significantly improves both accuracy and compression, which could not be achieved otherwise.
Adversarial Sampling and Training for Semi-Supervised Information Retrieval
Nov 09, 2018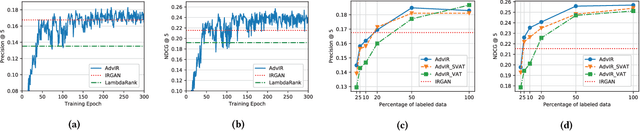
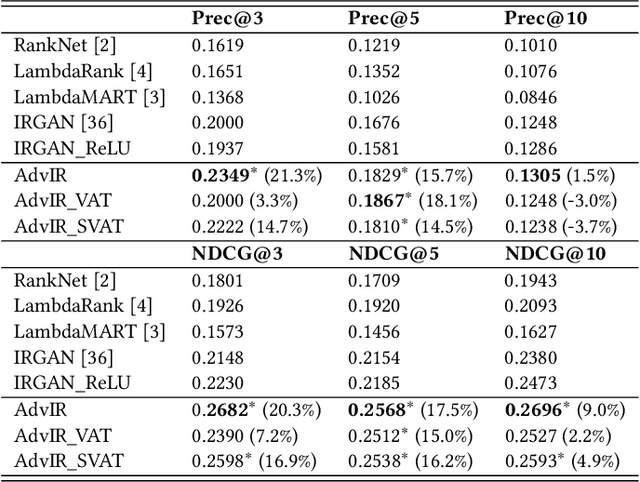
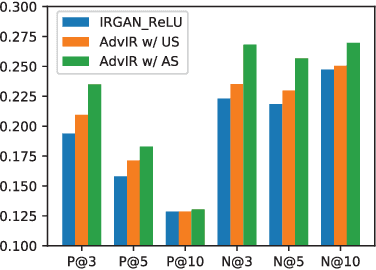
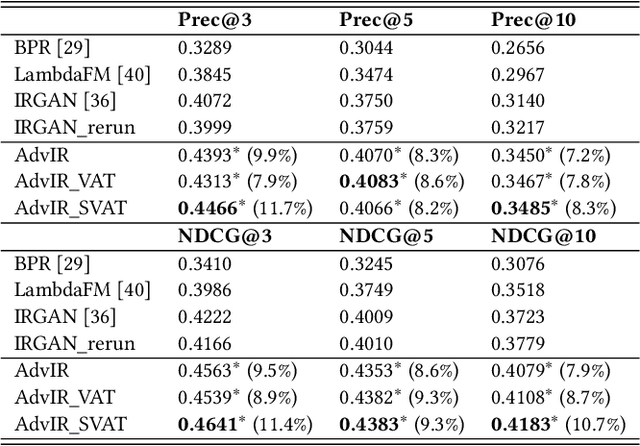
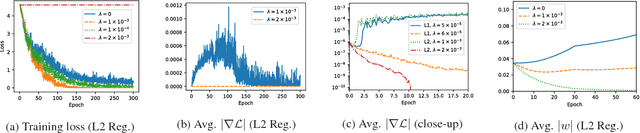
Modern ad-hoc retrieval models learned with implicit feedback have two problems in general. First, there are usually much more non-clicked documents than clicked documents, and many of the non-clicked documents are not informational. Second, modern ad-hoc retrieval models are vulnerable to adversarial examples due to the linear nature in the models. To solve the problems at the same time, we propose adversarial training methods that can overcome those weaknesses. Our key idea is to combine adversarial training with adversarial sampling in order to obtain very difficult examples, which are informational and can attack the linear nature of the models. Specifically, we adversarially sample difficult training examples, and based on them, we further generate adversarial examples that are even more difficult. To make the models robust, the generated adversarial examples as well as the original training examples are then given to the models for joint optimization. Experiments are performed on benchmark data sets for common ad-hoc retrieval tasks such as Web search, item recommendation, and question answering. The proposed methods are closely compared with IRGAN, which is a recent relevant approach that employs adversarial training. Experiment results indicate that the proposed methods significantly outperform strong baselines especially for high-ranked documents, and they outperform IRGAN in NDCG@5 using only 5% of labeled data for the Web search task.
Sequenced-Replacement Sampling for Deep Learning
Oct 19, 2018

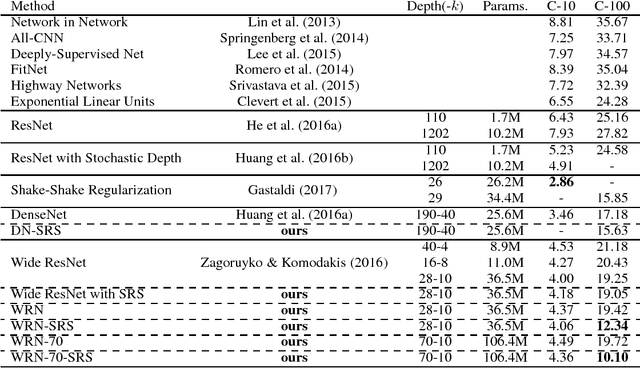

We propose sequenced-replacement sampling (SRS) for training deep neural networks. The basic idea is to assign a fixed sequence index to each sample in the dataset. Once a mini-batch is randomly drawn in each training iteration, we refill the original dataset by successively adding samples according to their sequence index. Thus we carry out replacement sampling but in a batched and sequenced way. In a sense, SRS could be viewed as a way of performing "mini-batch augmentation". It is particularly useful for a task where we have a relatively small images-per-class such as CIFAR-100. Together with a longer period of initial large learning rate, it significantly improves the classification accuracy in CIFAR-100 over the current state-of-the-art results. Our experiments indicate that training deeper networks with SRS is less prone to over-fitting. In the best case, we achieve an error rate as low as 10.10%.
Interpreting Deep Classifier by Visual Distillation of Dark Knowledge
Mar 11, 2018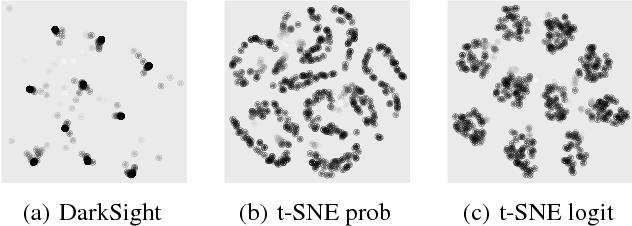
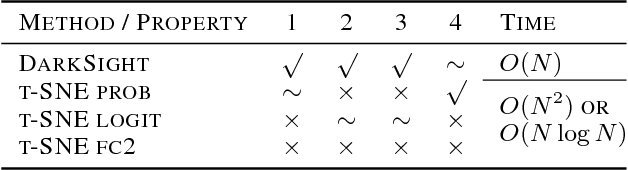
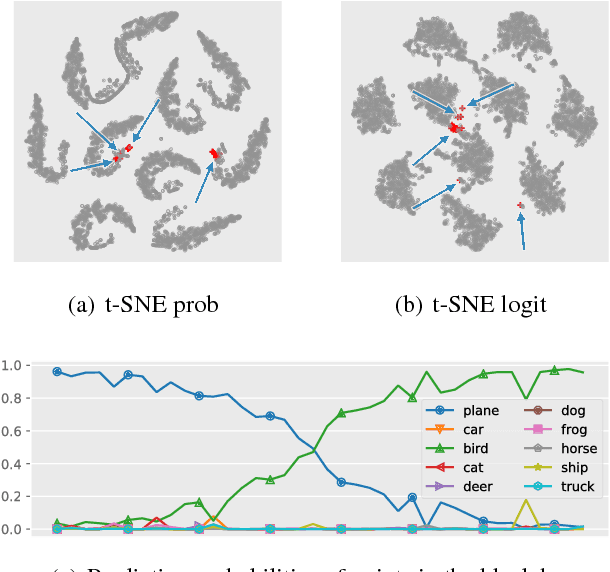
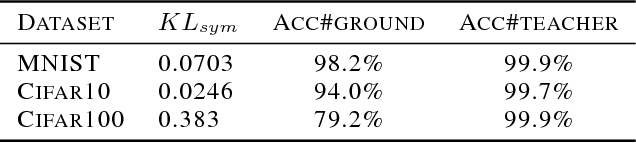
Interpreting black box classifiers, such as deep networks, allows an analyst to validate a classifier before it is deployed in a high-stakes setting. A natural idea is to visualize the deep network's representations, so as to "see what the network sees". In this paper, we demonstrate that standard dimension reduction methods in this setting can yield uninformative or even misleading visualizations. Instead, we present DarkSight, which visually summarizes the predictions of a classifier in a way inspired by notion of dark knowledge. DarkSight embeds the data points into a low-dimensional space such that it is easy to compress the deep classifier into a simpler one, essentially combining model compression and dimension reduction. We compare DarkSight against t-SNE both qualitatively and quantitatively, demonstrating that DarkSight visualizations are more informative. Our method additionally yields a new confidence measure based on dark knowledge by quantifying how unusual a given vector of predictions is.