 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Dispersion in Non-Markovian Environment
Feb 28, 2023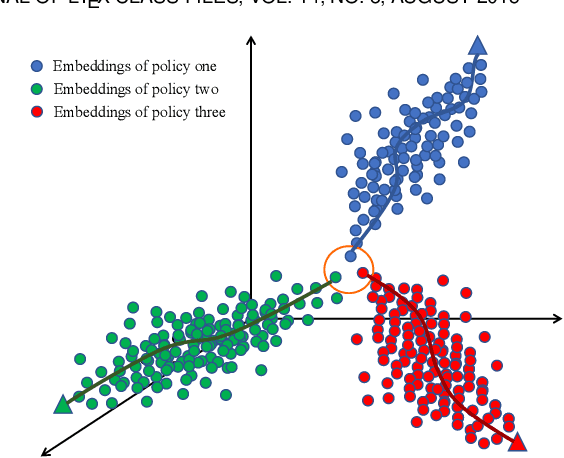

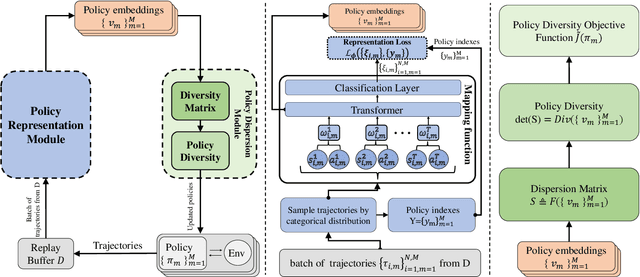

Markov Decision Process (MDP) presents a mathematical framework to formulate the learning processes of agents in reinforcement learning. MDP is limited by the Markovian assumption that a reward only depends on the immediate state and action. However, a reward sometimes depends on the history of states and actions, which may result in the decision process in a non-Markovian environment. In such environments, agents receive rewards via temporally-extended behaviors sparsely, and the learned policies may be similar. This leads the agents acquired with similar policies generally overfit to the given task and can not quickly adapt to perturbations of environments. To resolve this problem, this paper tries to learn the diverse policies from the history of state-action pairs under a non-Markovian environment, in which a policy dispersion scheme is designed for seeking diverse policy representation. Specifically, we first adopt a transformer-based method to learn policy embeddings. Then, we stack the policy embeddings to construct a dispersion matrix to induce a set of diverse policies. Finally, we prove that if the dispersion matrix is positive definite, the dispersed embeddings can effectively enlarge the disagreements across policies, yielding a diverse expression for the original policy embedding distribution. Experimental results show that this dispersion scheme can obtain more expressive diverse policies, which then derive more robust performance than recent learning baselines under various learning environments.
Unsupervised Deraining: Where Contrastive Learning Meets Self-similarity
Mar 22, 2022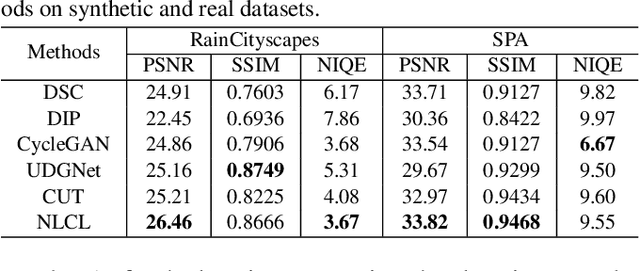
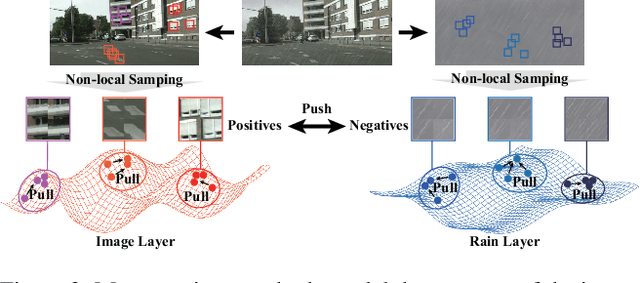
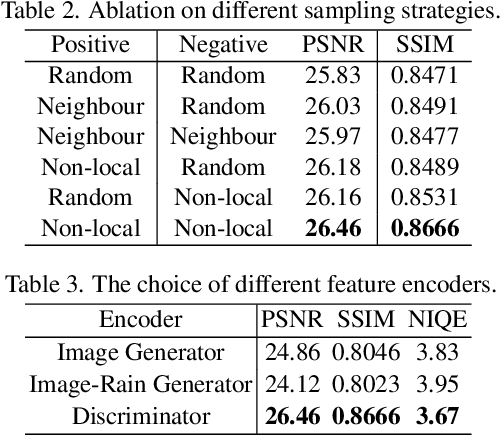
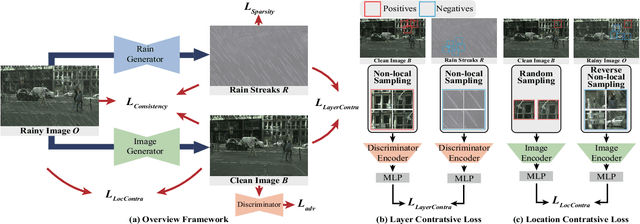
Image deraining is a typical low-level image restoration task, which aims at decomposing the rainy image into two distinguishable layers: the clean image layer and the rain layer. Most of the existing learning-based deraining methods are supervisedly trained on synthetic rainy-clean pairs. The domain gap between the synthetic and real rains makes them less generalized to different real rainy scenes. Moreover, the existing methods mainly utilize the property of the two layers independently, while few of them have considered the mutually exclusive relationship between the two layers. In this work, we propose a novel non-local contrastive learning (NLCL) method for unsupervised image deraining. Consequently, we not only utilize the intrinsic self-similarity property within samples but also the mutually exclusive property between the two layers, so as to better differ the rain layer from the clean image. Specifically, the non-local self-similarity image layer patches as the positives are pulled together and similar rain layer patches as the negatives are pushed away. Thus the similar positive/negative samples that are close in the original space benefit us to enrich more discriminative representation. Apart from the self-similarity sampling strategy, we analyze how to choose an appropriate feature encoder in NLCL. Extensive experiments on different real rainy datasets demonstrate that the proposed method obtains state-of-the-art performance in real deraining.
Interpreting Deep Classifier by Visual Distillation of Dark Knowledge
Mar 11, 2018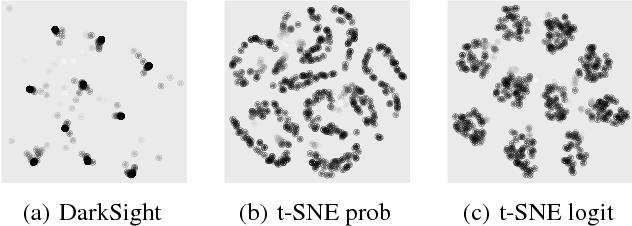
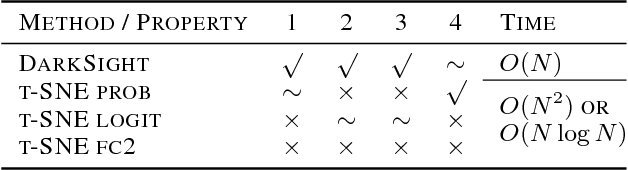
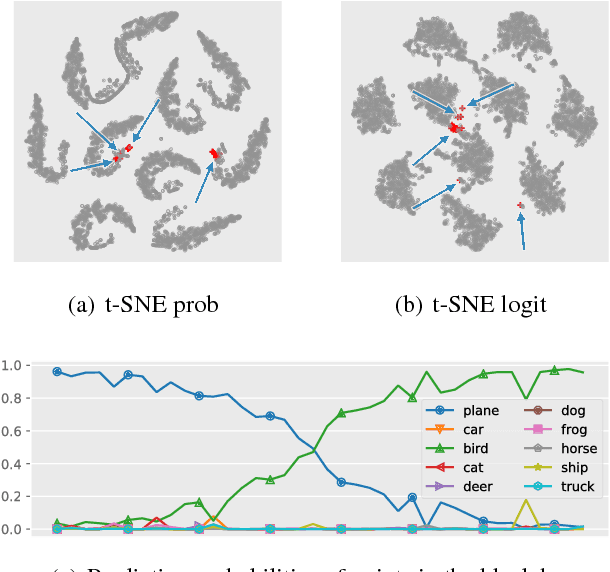
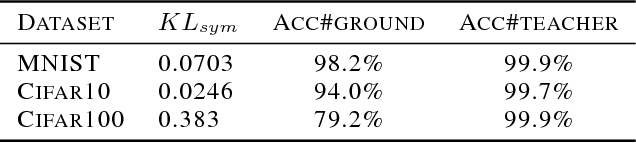
Interpreting black box classifiers, such as deep networks, allows an analyst to validate a classifier before it is deployed in a high-stakes setting. A natural idea is to visualize the deep network's representations, so as to "see what the network sees". In this paper, we demonstrate that standard dimension reduction methods in this setting can yield uninformative or even misleading visualizations. Instead, we present DarkSight, which visually summarizes the predictions of a classifier in a way inspired by notion of dark knowledge. DarkSight embeds the data points into a low-dimensional space such that it is easy to compress the deep classifier into a simpler one, essentially combining model compression and dimension reduction. We compare DarkSight against t-SNE both qualitatively and quantitatively, demonstrating that DarkSight visualizations are more informative. Our method additionally yields a new confidence measure based on dark knowledge by quantifying how unusual a given vector of predictions is.