 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDANCE: Doubly Adaptive Neighborhood Conformal Estimation
Feb 24, 2026The recent developments of complex deep learning models have led to unprecedented ability to accurately predict across multiple data representation types. Conformal prediction for uncertainty quantification of these models has risen in popularity, providing adaptive, statistically-valid prediction sets. For classification tasks, conformal methods have typically focused on utilizing logit scores. For pre-trained models, however, this can result in inefficient, overly conservative set sizes when not calibrated towards the target task. We propose DANCE, a doubly locally adaptive nearest-neighbor based conformal algorithm combining two novel nonconformity scores directly using the data's embedded representation. DANCE first fits a task-adaptive kernel regression model from the embedding layer before using the learned kernel space to produce the final prediction sets for uncertainty quantification. We test against state-of-the-art local, task-adapted and zero-shot conformal baselines, demonstrating DANCE's superior blend of set size efficiency and robustness across various datasets.
Steering Autoregressive Music Generation with Recursive Feature Machines
Oct 21, 2025Controllable music generation remains a significant challenge, with existing methods often requiring model retraining or introducing audible artifacts. We introduce MusicRFM, a framework that adapts Recursive Feature Machines (RFMs) to enable fine-grained, interpretable control over frozen, pre-trained music models by directly steering their internal activations. RFMs analyze a model's internal gradients to produce interpretable "concept directions", or specific axes in the activation space that correspond to musical attributes like notes or chords. We first train lightweight RFM probes to discover these directions within MusicGen's hidden states; then, during inference, we inject them back into the model to guide the generation process in real-time without per-step optimization. We present advanced mechanisms for this control, including dynamic, time-varying schedules and methods for the simultaneous enforcement of multiple musical properties. Our method successfully navigates the trade-off between control and generation quality: we can increase the accuracy of generating a target musical note from 0.23 to 0.82, while text prompt adherence remains within approximately 0.02 of the unsteered baseline, demonstrating effective control with minimal impact on prompt fidelity. We release code to encourage further exploration on RFMs in the music domain.
Aggregate and conquer: detecting and steering LLM concepts by combining nonlinear predictors over multiple layers
Feb 06, 2025



A trained Large Language Model (LLM) contains much of human knowledge. Yet, it is difficult to gauge the extent or accuracy of that knowledge, as LLMs do not always ``know what they know'' and may even be actively misleading. In this work, we give a general method for detecting semantic concepts in the internal activations of LLMs. Furthermore, we show that our methodology can be easily adapted to steer LLMs toward desirable outputs. Our innovations are the following: (1) we use a nonlinear feature learning method to identify important linear directions for predicting concepts from each layer; (2) we aggregate features across layers to build powerful concept detectors and steering mechanisms. We showcase the power of our approach by attaining state-of-the-art results for detecting hallucinations, harmfulness, toxicity, and untruthful content on seven benchmarks. We highlight the generality of our approach by steering LLMs towards new concepts that, to the best of our knowledge, have not been previously considered in the literature, including: semantic disambiguation, human languages, programming languages, hallucinated responses, science subjects, poetic/Shakespearean English, and even multiple concepts simultaneously. Moreover, our method can steer concepts with numerical attributes such as product reviews. We provide our code (including a simple API for our methods) at https://github.com/dmbeaglehole/neural_controllers .
Emergence in non-neural models: grokking modular arithmetic via average gradient outer product
Jul 29, 2024Neural networks trained to solve modular arithmetic tasks exhibit grokking, a phenomenon where the test accuracy starts improving long after the model achieves 100% training accuracy in the training process. It is often taken as an example of "emergence", where model ability manifests sharply through a phase transition. In this work, we show that the phenomenon of grokking is not specific to neural networks nor to gradient descent-based optimization. Specifically, we show that this phenomenon occurs when learning modular arithmetic with Recursive Feature Machines (RFM), an iterative algorithm that uses the Average Gradient Outer Product (AGOP) to enable task-specific feature learning with general machine learning models. When used in conjunction with kernel machines, iterating RFM results in a fast transition from random, near zero, test accuracy to perfect test accuracy. This transition cannot be predicted from the training loss, which is identically zero, nor from the test loss, which remains constant in initial iterations. Instead, as we show, the transition is completely determined by feature learning: RFM gradually learns block-circulant features to solve modular arithmetic. Paralleling the results for RFM, we show that neural networks that solve modular arithmetic also learn block-circulant features. Furthermore, we present theoretical evidence that RFM uses such block-circulant features to implement the Fourier Multiplication Algorithm, which prior work posited as the generalizing solution neural networks learn on these tasks. Our results demonstrate that emergence can result purely from learning task-relevant features and is not specific to neural architectures nor gradient descent-based optimization methods. Furthermore, our work provides more evidence for AGOP as a key mechanism for feature learning in neural networks.
Average gradient outer product as a mechanism for deep neural collapse
Feb 21, 2024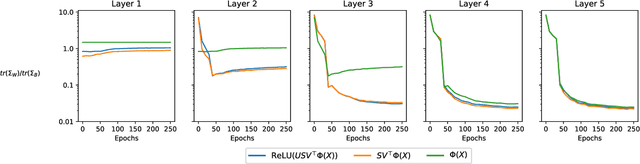

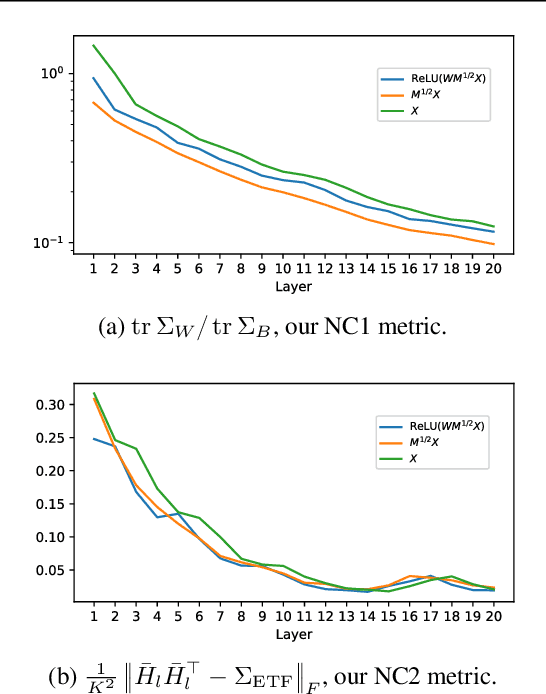
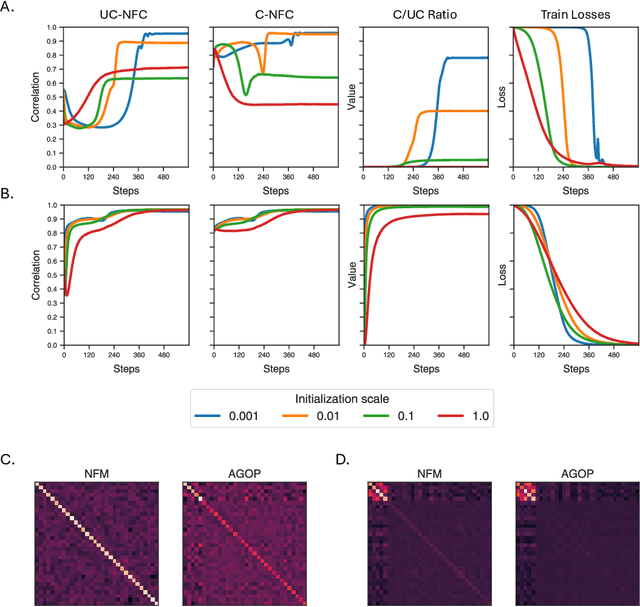
Deep Neural Collapse (DNC) refers to the surprisingly rigid structure of the data representations in the final layers of Deep Neural Networks (DNNs). Though the phenomenon has been measured in a wide variety of settings, its emergence is only partially understood. In this work, we provide substantial evidence that DNC formation occurs primarily through deep feature learning with the average gradient outer product (AGOP). This takes a step further compared to efforts that explain neural collapse via feature-agnostic approaches, such as the unconstrained features model. We proceed by providing evidence that the right singular vectors and values of the weights are responsible for the majority of within-class variability collapse in DNNs. As shown in recent work, this singular structure is highly correlated with that of the AGOP. We then establish experimentally and theoretically that AGOP induces neural collapse in a randomly initialized neural network. In particular, we demonstrate that Deep Recursive Feature Machines, a method originally introduced as an abstraction for AGOP feature learning in convolutional neural networks, exhibits DNC.
Gradient descent induces alignment between weights and the empirical NTK for deep non-linear networks
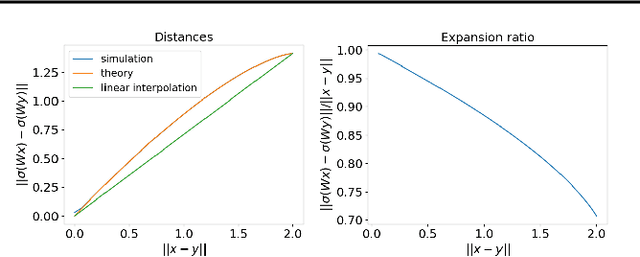
Feb 07, 2024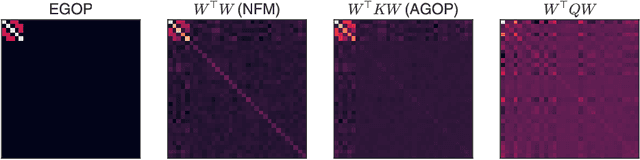
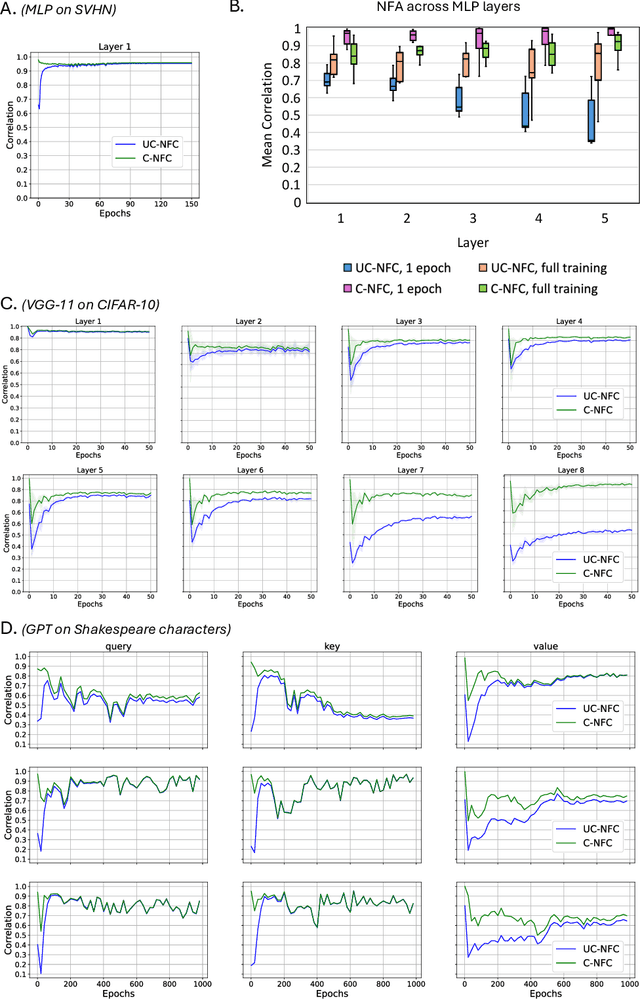
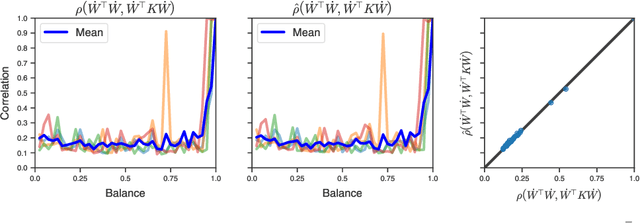
Understanding the mechanisms through which neural networks extract statistics from input-label pairs is one of the most important unsolved problems in supervised learning. Prior works have identified that the gram matrices of the weights in trained neural networks of general architectures are proportional to the average gradient outer product of the model, in a statement known as the Neural Feature Ansatz (NFA). However, the reason these quantities become correlated during training is poorly understood. In this work, we explain the emergence of this correlation. We identify that the NFA is equivalent to alignment between the left singular structure of the weight matrices and a significant component of the empirical neural tangent kernels associated with those weights. We establish that the NFA introduced in prior works is driven by a centered NFA that isolates this alignment. We show that the speed of NFA development can be predicted analytically at early training times in terms of simple statistics of the inputs and labels. Finally, we introduce a simple intervention to increase NFA correlation at any given layer, which dramatically improves the quality of features learned.
Mechanism of feature learning in convolutional neural networks
Sep 01, 2023



Understanding the mechanism of how convolutional neural networks learn features from image data is a fundamental problem in machine learning and computer vision. In this work, we identify such a mechanism. We posit the Convolutional Neural Feature Ansatz, which states that covariances of filters in any convolutional layer are proportional to the average gradient outer product (AGOP) taken with respect to patches of the input to that layer. We present extensive empirical evidence for our ansatz, including identifying high correlation between covariances of filters and patch-based AGOPs for convolutional layers in standard neural architectures, such as AlexNet, VGG, and ResNets pre-trained on ImageNet. We also provide supporting theoretical evidence. We then demonstrate the generality of our result by using the patch-based AGOP to enable deep feature learning in convolutional kernel machines. We refer to the resulting algorithm as (Deep) ConvRFM and show that our algorithm recovers similar features to deep convolutional networks including the notable emergence of edge detectors. Moreover, we find that Deep ConvRFM overcomes previously identified limitations of convolutional kernels, such as their inability to adapt to local signals in images and, as a result, leads to sizable performance improvement over fixed convolutional kernels.
Feature learning in neural networks and kernel machines that recursively learn features
Dec 28, 2022Neural networks have achieved impressive results on many technological and scientific tasks. Yet, their empirical successes have outpaced our fundamental understanding of their structure and function. By identifying mechanisms driving the successes of neural networks, we can provide principled approaches for improving neural network performance and develop simple and effective alternatives. In this work, we isolate the key mechanism driving feature learning in fully connected neural networks by connecting neural feature learning to the average gradient outer product. We subsequently leverage this mechanism to design \textit{Recursive Feature Machines} (RFMs), which are kernel machines that learn features. We show that RFMs (1) accurately capture features learned by deep fully connected neural networks, (2) close the gap between kernel machines and fully connected networks, and (3) surpass a broad spectrum of models including neural networks on tabular data. Furthermore, we demonstrate that RFMs shed light on recently observed deep learning phenomena such as grokking, lottery tickets, simplicity biases, and spurious features. We provide a Python implementation to make our method broadly accessible [\href{https://github.com/aradha/recursive_feature_machines}{GitHub}].
Kernel Ridgeless Regression is Inconsistent in Low Dimensions
Jun 02, 2022

We show that kernel interpolation for a large class of shift-invariant kernels is inconsistent in fixed dimension, even with bandwidth adaptive to the training set.
Learning to Hash Robustly, with Guarantees
Aug 17, 2021



The indexing algorithms for the high-dimensional nearest neighbor search (NNS) with the best worst-case guarantees are based on the randomized Locality Sensitive Hashing (LSH), and its derivatives. In practice, many heuristic approaches exist to "learn" the best indexing method in order to speed-up NNS, crucially adapting to the structure of the given dataset. Oftentimes, these heuristics outperform the LSH-based algorithms on real datasets, but, almost always, come at the cost of losing the guarantees of either correctness or robust performance on adversarial queries, or apply to datasets with an assumed extra structure/model. In this paper, we design an NNS algorithm for the Hamming space that has worst-case guarantees essentially matching that of theoretical algorithms, while optimizing the hashing to the structure of the dataset (think instance-optimal algorithms) for performance on the minimum-performing query. We evaluate the algorithm's ability to optimize for a given dataset both theoretically and practically. On the theoretical side, we exhibit a natural setting (dataset model) where our algorithm is much better than the standard theoretical one. On the practical side, we run experiments that show that our algorithm has a 1.8x and 2.1x better recall on the worst-performing queries to the MNIST and ImageNet datasets.