 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepetition In Repetition Out: Towards Understanding Neural Text Degeneration from the Data Perspective
Paper and Code

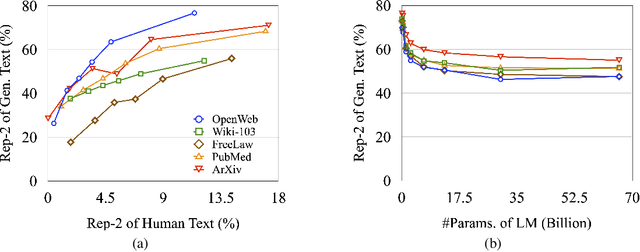
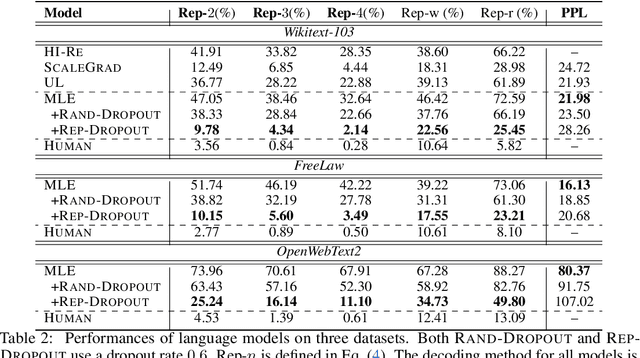
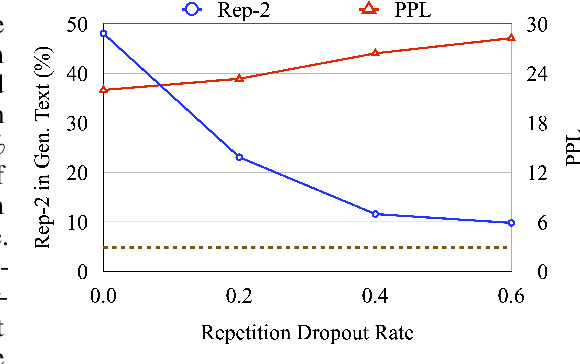
There are a number of diverging hypotheses about the neural text degeneration problem, i.e., generating repetitive and dull loops, which makes this problem both interesting and confusing. In this work, we aim to advance our understanding by presenting a straightforward and fundamental explanation from the data perspective. Our preliminary investigation reveals a strong correlation between the degeneration issue and the presence of repetitions in training data. Subsequent experiments also demonstrate that by selectively dropping out the attention to repetitive words in training data, degeneration can be significantly minimized. Furthermore, our empirical analysis illustrates that prior works addressing the degeneration issue from various standpoints, such as the high-inflow words, the likelihood objective, and the self-reinforcement phenomenon, can be interpreted by one simple explanation. That is, penalizing the repetitions in training data is a common and fundamental factor for their effectiveness. Moreover, our experiments reveal that penalizing the repetitions in training data remains critical even when considering larger model sizes and instruction tuning.