 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoder-Only or Encoder-Decoder? Interpreting Language Model as a Regularized Encoder-Decoder
Paper and Code
Apr 08, 2023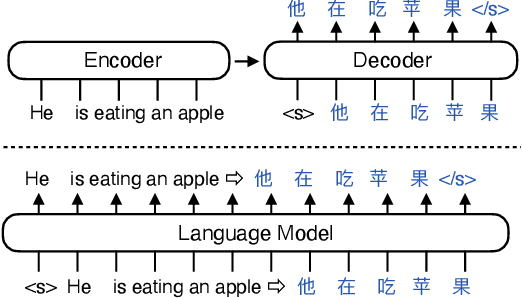
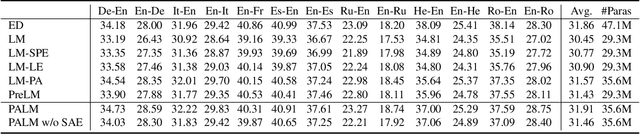
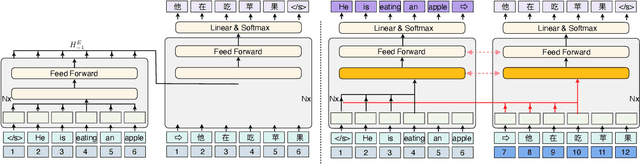
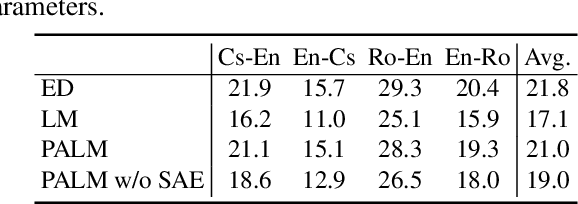
The sequence-to-sequence (seq2seq) task aims at generating the target sequence based on the given input source sequence. Traditionally, most of the seq2seq task is resolved by the Encoder-Decoder framework which requires an encoder to encode the source sequence and a decoder to generate the target text. Recently, a bunch of new approaches have emerged that apply decoder-only language models directly to the seq2seq task. Despite the significant advancements in applying language models to the seq2seq task, there is still a lack of thorough analysis on the effectiveness of the decoder-only language model architecture. This paper aims to address this gap by conducting a detailed comparison between the encoder-decoder architecture and the decoder-only language model framework through the analysis of a regularized encoder-decoder structure. This structure is designed to replicate all behaviors in the classical decoder-only language model but has an encoder and a decoder making it easier to be compared with the classical encoder-decoder structure. Based on the analysis, we unveil the attention degeneration problem in the language model, namely, as the generation step number grows, less and less attention is focused on the source sequence. To give a quantitative understanding of this problem, we conduct a theoretical sensitivity analysis of the attention output with respect to the source input. Grounded on our analysis, we propose a novel partial attention language model to solve the attention degeneration problem. Experimental results on machine translation, summarization, and data-to-text generation tasks support our analysis and demonstrate the effectiveness of our proposed model.