 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Frequency Collaborative Training Network and Dataset for Semi-supervised First Molar Root Canal Segmentation
Apr 16, 2025Root canal (RC) treatment is a highly delicate and technically complex procedure in clinical practice, heavily influenced by the clinicians' experience and subjective judgment. Deep learning has made significant advancements in the field of computer-aided diagnosis (CAD) because it can provide more objective and accurate diagnostic results. However, its application in RC treatment is still relatively rare, mainly due to the lack of public datasets in this field. To address this issue, in this paper, we established a First Molar Root Canal segmentation dataset called FMRC-2025. Additionally, to alleviate the workload of manual annotation for dentists and fully leverage the unlabeled data, we designed a Cross-Frequency Collaborative training semi-supervised learning (SSL) Network called CFC-Net. It consists of two components: (1) Cross-Frequency Collaborative Mean Teacher (CFC-MT), which introduces two specialized students (SS) and one comprehensive teacher (CT) for collaborative multi-frequency training. The CT and SS are trained on different frequency components while fully integrating multi-frequency knowledge through cross and full frequency consistency supervisions. (2) Uncertainty-guided Cross-Frequency Mix (UCF-Mix) mechanism enables the network to generate high-confidence pseudo-labels while learning to integrate multi-frequency information and maintaining the structural integrity of the targets. Extensive experiments on FMRC-2025 and three public dental datasets demonstrate that CFC-MT is effective for RC segmentation and can also exhibit strong generalizability on other dental segmentation tasks, outperforming state-of-the-art SSL medical image segmentation methods. Codes and dataset will be released.
Transformer for Multitemporal Hyperspectral Image Unmixing
Jul 15, 2024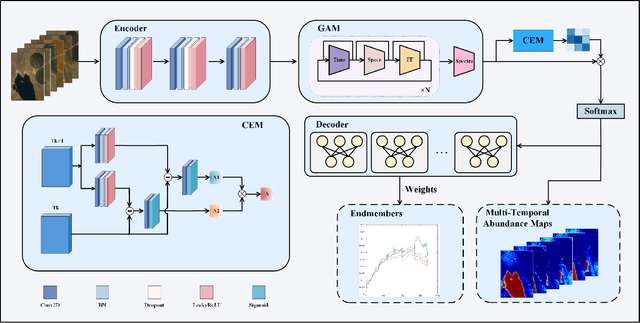
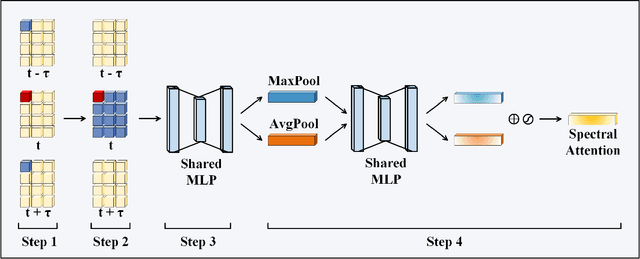

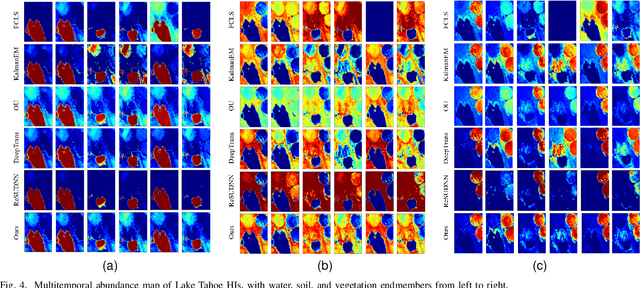
Multitemporal hyperspectral image unmixing (MTHU) holds significant importance in monitoring and analyzing the dynamic changes of surface. However, compared to single-temporal unmixing, the multitemporal approach demands comprehensive consideration of information across different phases, rendering it a greater challenge. To address this challenge, we propose the Multitemporal Hyperspectral Image Unmixing Transformer (MUFormer), an end-to-end unsupervised deep learning model. To effectively perform multitemporal hyperspectral image unmixing, we introduce two key modules: the Global Awareness Module (GAM) and the Change Enhancement Module (CEM). The Global Awareness Module computes self-attention across all phases, facilitating global weight allocation. On the other hand, the Change Enhancement Module dynamically learns local temporal changes by comparing endmember changes between adjacent phases. The synergy between these modules allows for capturing semantic information regarding endmember and abundance changes, thereby enhancing the effectiveness of multitemporal hyperspectral image unmixing. We conducted experiments on one real dataset and two synthetic datasets, demonstrating that our model significantly enhances the effect of multitemporal hyperspectral image unmixing.
ADFQ-ViT: Activation-Distribution-Friendly Post-Training Quantization for Vision Transformers
Jul 03, 2024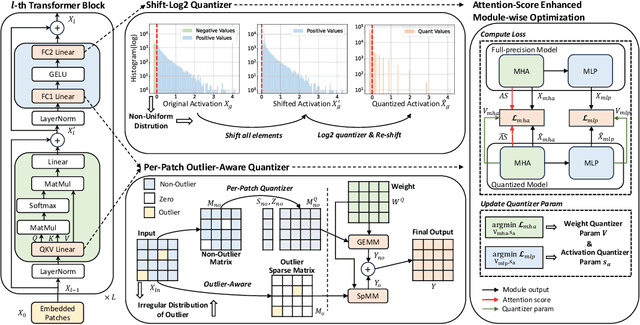
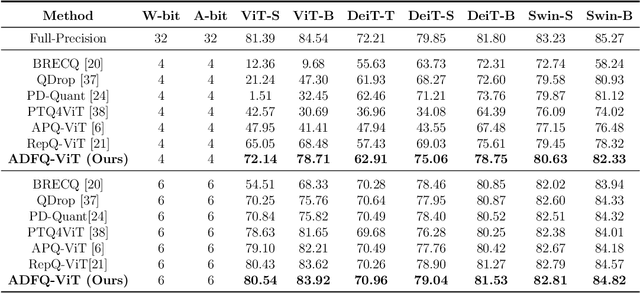
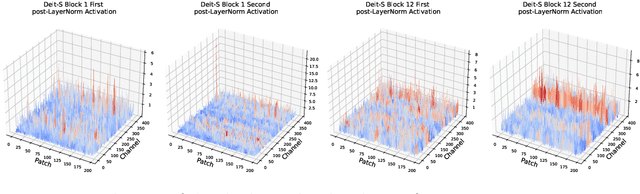
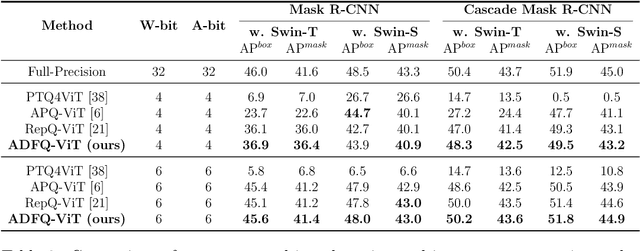
Vision Transformers (ViTs) have exhibited exceptional performance across diverse computer vision tasks, while their substantial parameter size incurs significantly increased memory and computational demands, impeding effective inference on resource-constrained devices. Quantization has emerged as a promising solution to mitigate these challenges, yet existing methods still suffer from significant accuracy loss at low-bit. We attribute this issue to the distinctive distributions of post-LayerNorm and post-GELU activations within ViTs, rendering conventional hardware-friendly quantizers ineffective, particularly in low-bit scenarios. To address this issue, we propose a novel framework called Activation-Distribution-Friendly post-training Quantization for Vision Transformers, ADFQ-ViT. Concretely, we introduce the Per-Patch Outlier-aware Quantizer to tackle irregular outliers in post-LayerNorm activations. This quantizer refines the granularity of the uniform quantizer to a per-patch level while retaining a minimal subset of values exceeding a threshold at full-precision. To handle the non-uniform distributions of post-GELU activations between positive and negative regions, we design the Shift-Log2 Quantizer, which shifts all elements to the positive region and then applies log2 quantization. Moreover, we present the Attention-score enhanced Module-wise Optimization which adjusts the parameters of each quantizer by reconstructing errors to further mitigate quantization error. Extensive experiments demonstrate ADFQ-ViT provides significant improvements over various baselines in image classification, object detection, and instance segmentation tasks at 4-bit. Specifically, when quantizing the ViT-B model to 4-bit, we achieve a 10.23% improvement in Top-1 accuracy on the ImageNet dataset.
Spatial-Frequency Dual Progressive Attention Network For Medical Image Segmentation
Jun 12, 2024In medical images, various types of lesions often manifest significant differences in their shape and texture. Accurate medical image segmentation demands deep learning models with robust capabilities in multi-scale and boundary feature learning. However, previous networks still have limitations in addressing the above issues. Firstly, previous networks simultaneously fuse multi-level features or employ deep supervision to enhance multi-scale learning. However, this may lead to feature redundancy and excessive computational overhead, which is not conducive to network training and clinical deployment. Secondly, the majority of medical image segmentation networks exclusively learn features in the spatial domain, disregarding the abundant global information in the frequency domain. This results in a bias towards low-frequency components, neglecting crucial high-frequency information. To address these problems, we introduce SF-UNet, a spatial-frequency dual-domain attention network. It comprises two main components: the Multi-scale Progressive Channel Attention (MPCA) block, which progressively extract multi-scale features across adjacent encoder layers, and the lightweight Frequency-Spatial Attention (FSA) block, with only 0.05M parameters, enabling concurrent learning of texture and boundary features from both spatial and frequency domains. We validate the effectiveness of the proposed SF-UNet on three public datasets. Experimental results show that compared to previous state-of-the-art (SOTA) medical image segmentation networks, SF-UNet achieves the best performance, and achieves up to 9.4\% and 10.78\% improvement in DSC and IOU. Codes will be released at https://github.com/nkicsl/SF-UNet.
Memory-Efficient and Secure DNN Inference on TrustZone-enabled Consumer IoT Devices
Mar 19, 2024



Edge intelligence enables resource-demanding Deep Neural Network (DNN) inference without transferring original data, addressing concerns about data privacy in consumer Internet of Things (IoT) devices. For privacy-sensitive applications, deploying models in hardware-isolated trusted execution environments (TEEs) becomes essential. However, the limited secure memory in TEEs poses challenges for deploying DNN inference, and alternative techniques like model partitioning and offloading introduce performance degradation and security issues. In this paper, we present a novel approach for advanced model deployment in TrustZone that ensures comprehensive privacy preservation during model inference. We design a memory-efficient management method to support memory-demanding inference in TEEs. By adjusting the memory priority, we effectively mitigate memory leakage risks and memory overlap conflicts, resulting in 32 lines of code alterations in the trusted operating system. Additionally, we leverage two tiny libraries: S-Tinylib (2,538 LoCs), a tiny deep learning library, and Tinylibm (827 LoCs), a tiny math library, to support efficient inference in TEEs. We implemented a prototype on Raspberry Pi 3B+ and evaluated it using three well-known lightweight DNN models. The experimental results demonstrate that our design significantly improves inference speed by 3.13 times and reduces power consumption by over 66.5% compared to non-memory optimization method in TEEs.