 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRT-SRTS: Angle-Agnostic Real-Time Simultaneous 3D Reconstruction and Tumor Segmentation from Single X-Ray Projection
Oct 12, 2023Radiotherapy is one of the primary treatment methods for tumors, but the organ movement caused by respiratory motion limits its accuracy. Recently, 3D imaging from single X-ray projection receives extensive attentions as a promising way to address this issue. However, current methods can only reconstruct 3D image without direct location of the tumor and are only validated for fixed-angle imaging, which fails to fully meet the requirement of motion control in radiotherapy. In this study, we propose a novel imaging method RT-SRTS which integrates 3D imaging and tumor segmentation into one network based on the multi-task learning (MTL) and achieves real-time simultaneous 3D reconstruction and tumor segmentation from single X-ray projection at any angle. Futhermore, we propose the attention enhanced calibrator (AEC) and uncertain-region elaboration (URE) modules to aid feature extraction and improve segmentation accuracy. We evaluated the proposed method on ten patient cases and compared it with two state-of-the-art methods. Our approach not only delivered superior 3D reconstruction but also demonstrated commendable tumor segmentation results. The simultaneous reconstruction and segmentation could be completed in approximately 70 ms, significantly faster than the required time threshold for real-time tumor tracking. The efficacy of both AEC and URE was also validated through ablation studies.
AGCN: Augmented Graph Convolutional Network for Lifelong Multi-label Image Recognition
Mar 11, 2022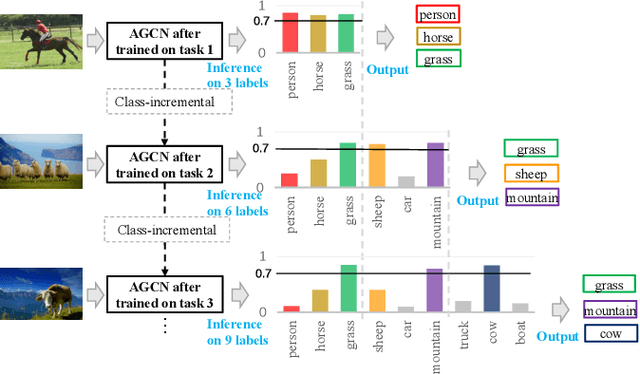
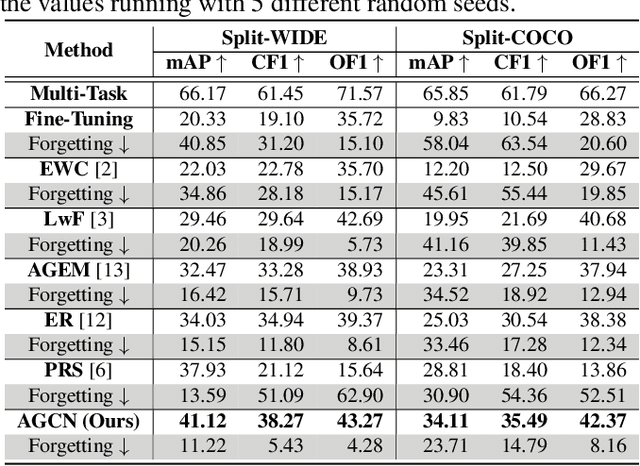
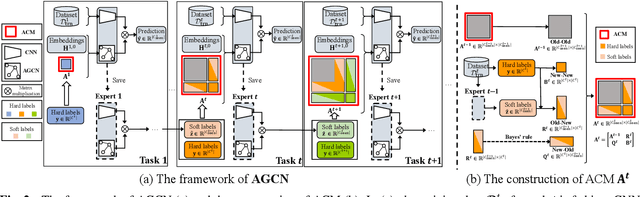
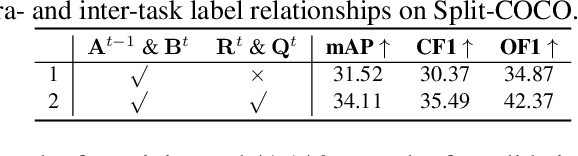
The Lifelong Multi-Label (LML) image recognition builds an online class-incremental classifier in a sequential multi-label image recognition data stream. The key challenges of LML image recognition are the construction of label relationships on Partial Labels of training data and the Catastrophic Forgetting on old classes, resulting in poor generalization. To solve the problems, the study proposes an Augmented Graph Convolutional Network (AGCN) model that can construct the label relationships across the sequential recognition tasks and sustain the catastrophic forgetting. First, we build an Augmented Correlation Matrix (ACM) across all seen classes, where the intra-task relationships derive from the hard label statistics while the inter-task relationships leverage both hard and soft labels from data and a constructed expert network. Then, based on the ACM, the proposed AGCN captures label dependencies with dynamic augmented structure and yields effective class representations. Last, to suppress the forgetting of label dependencies across old tasks, we propose a relationship-preserving loss as a constraint to the construction of label relationships. The proposed method is evaluated using two multi-label image benchmarks and the experimental results show that the proposed method is effective for LML image recognition and can build convincing correlation across tasks even if the labels of previous tasks are missing. Our code is available at https://github.com/Kaile-Du/AGCN.
Coarse to Fine: Multi-label Image Classification with Global/Local Attention
Dec 26, 2020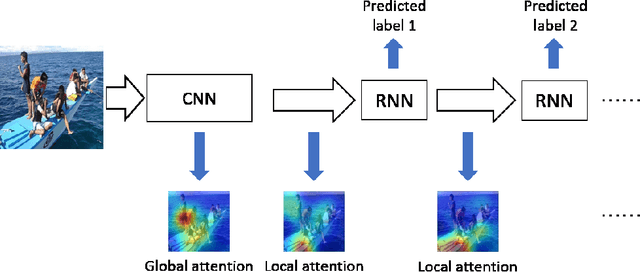
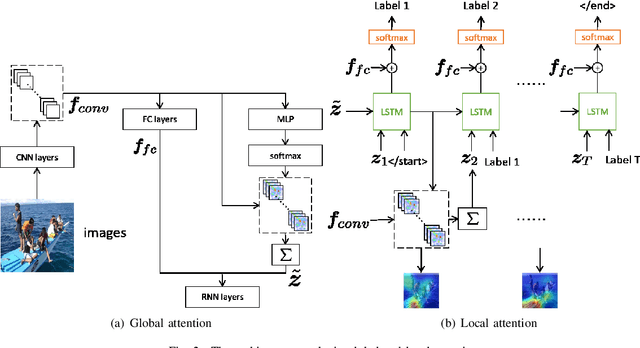
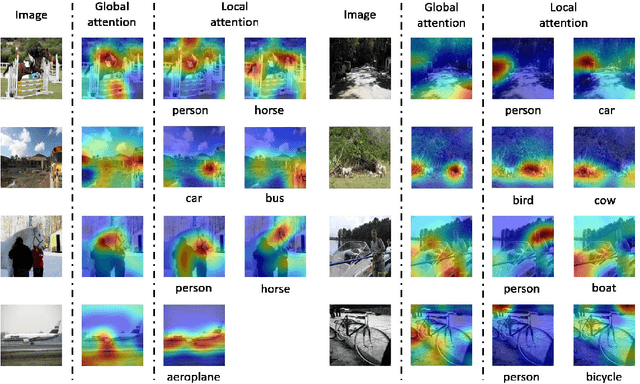
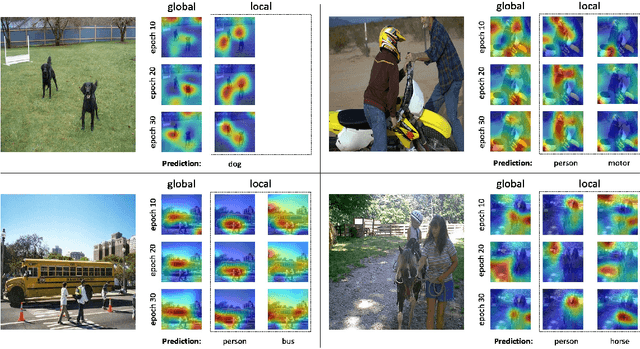
In our daily life, the scenes around us are always with multiple labels especially in a smart city, i.e., recognizing the information of city operation to response and control. Great efforts have been made by using Deep Neural Networks to recognize multi-label images. Since multi-label image classification is very complicated, people seek to use the attention mechanism to guide the classification process. However, conventional attention-based methods always analyzed images directly and aggressively. It is difficult for them to well understand complicated scenes. In this paper, we propose a global/local attention method that can recognize an image from coarse to fine by mimicking how human-beings observe images. Specifically, our global/local attention method first concentrates on the whole image, and then focuses on local specific objects in the image. We also propose a joint max-margin objective function, which enforces that the minimum score of positive labels should be larger than the maximum score of negative labels horizontally and vertically. This function can further improve our multi-label image classification method. We evaluate the effectiveness of our method on two popular multi-label image datasets (i.e., Pascal VOC and MS-COCO). Our experimental results show that our method outperforms state-of-the-art methods.
SR-GAN: Semantic Rectifying Generative Adversarial Network for Zero-shot Learning
Apr 15, 2019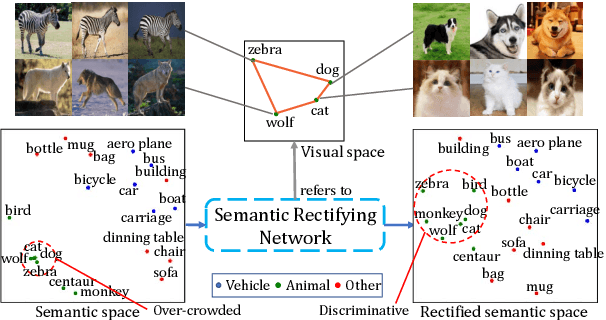
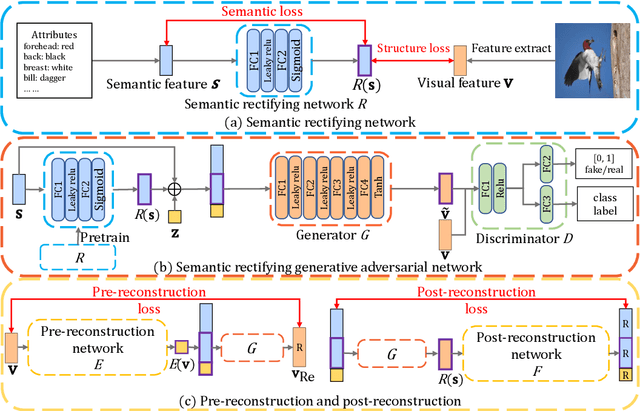
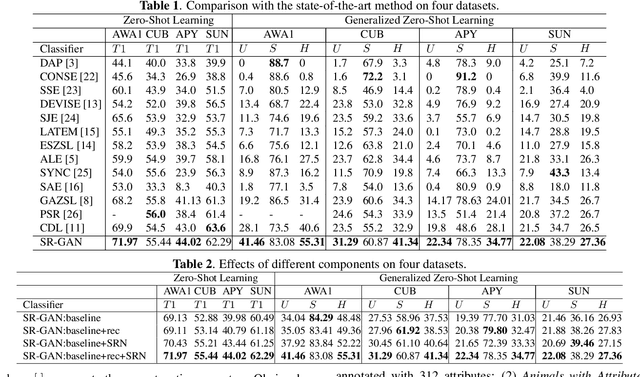

The existing Zero-Shot learning (ZSL) methods may suffer from the vague class attributes that are highly overlapped for different classes. Unlike these methods that ignore the discrimination among classes, in this paper, we propose to classify unseen image by rectifying the semantic space guided by the visual space. First, we pre-train a Semantic Rectifying Network (SRN) to rectify semantic space with a semantic loss and a rectifying loss. Then, a Semantic Rectifying Generative Adversarial Network (SR-GAN) is built to generate plausible visual feature of unseen class from both semantic feature and rectified semantic feature. To guarantee the effectiveness of rectified semantic features and synthetic visual features, a pre-reconstruction and a post reconstruction networks are proposed, which keep the consistency between visual feature and semantic feature. Experimental results demonstrate that our approach significantly outperforms the state-of-the-arts on four benchmark datasets.