 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse to Fine: Multi-label Image Classification with Global/Local Attention
Paper and Code
Dec 26, 2020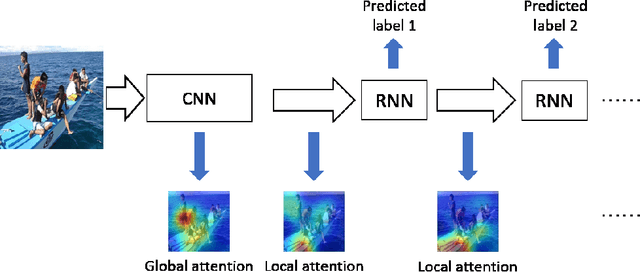
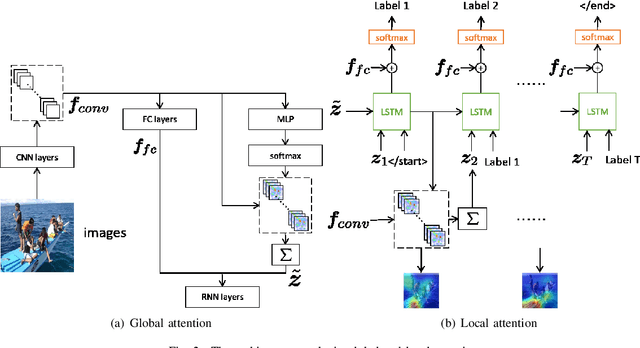
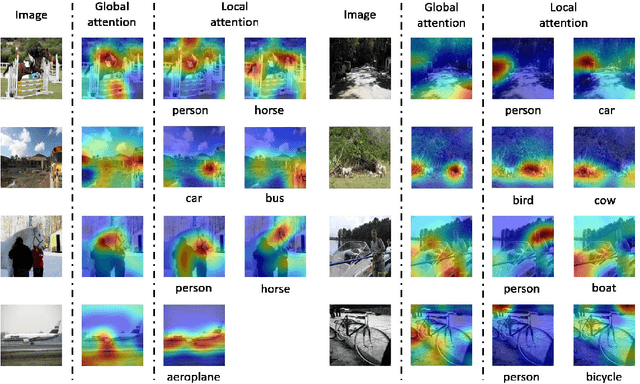
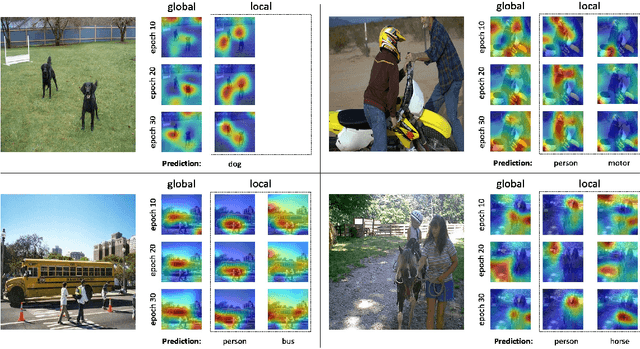
In our daily life, the scenes around us are always with multiple labels especially in a smart city, i.e., recognizing the information of city operation to response and control. Great efforts have been made by using Deep Neural Networks to recognize multi-label images. Since multi-label image classification is very complicated, people seek to use the attention mechanism to guide the classification process. However, conventional attention-based methods always analyzed images directly and aggressively. It is difficult for them to well understand complicated scenes. In this paper, we propose a global/local attention method that can recognize an image from coarse to fine by mimicking how human-beings observe images. Specifically, our global/local attention method first concentrates on the whole image, and then focuses on local specific objects in the image. We also propose a joint max-margin objective function, which enforces that the minimum score of positive labels should be larger than the maximum score of negative labels horizontally and vertically. This function can further improve our multi-label image classification method. We evaluate the effectiveness of our method on two popular multi-label image datasets (i.e., Pascal VOC and MS-COCO). Our experimental results show that our method outperforms state-of-the-art methods.