 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogic Synthesis Meets Machine Learning: Trading Exactness for Generalization
Dec 15, 2020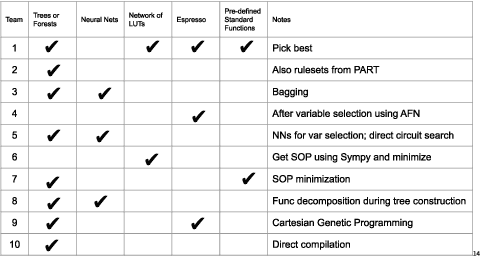
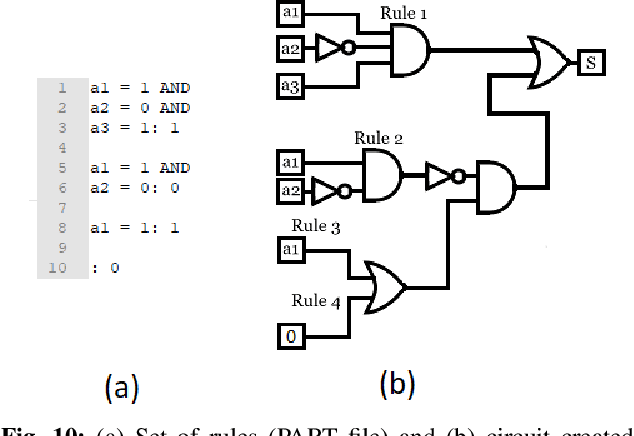
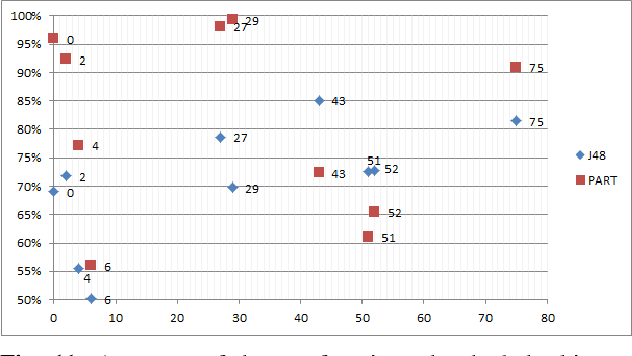
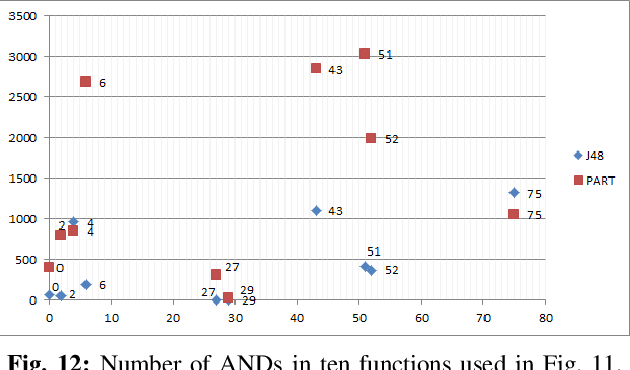
Logic synthesis is a fundamental step in hardware design whose goal is to find structural representations of Boolean functions while minimizing delay and area. If the function is completely-specified, the implementation accurately represents the function. If the function is incompletely-specified, the implementation has to be true only on the care set. While most of the algorithms in logic synthesis rely on SAT and Boolean methods to exactly implement the care set, we investigate learning in logic synthesis, attempting to trade exactness for generalization. This work is directly related to machine learning where the care set is the training set and the implementation is expected to generalize on a validation set. We present learning incompletely-specified functions based on the results of a competition conducted at IWLS 2020. The goal of the competition was to implement 100 functions given by a set of care minterms for training, while testing the implementation using a set of validation minterms sampled from the same function. We make this benchmark suite available and offer a detailed comparative analysis of the different approaches to learning
ExPAN(N)D: Exploring Posits for Efficient Artificial Neural Network Design in FPGA-based Systems
Oct 27, 2020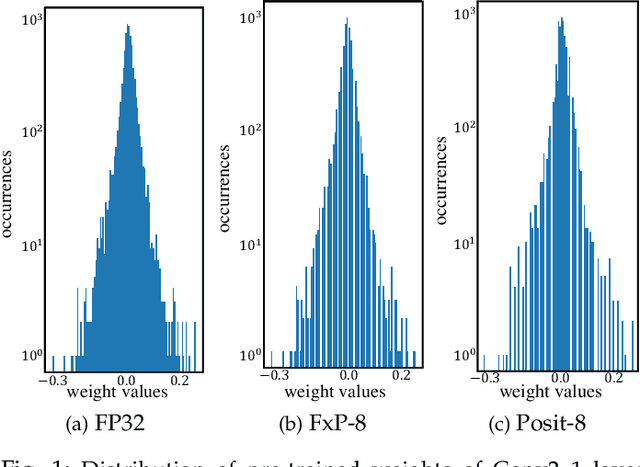
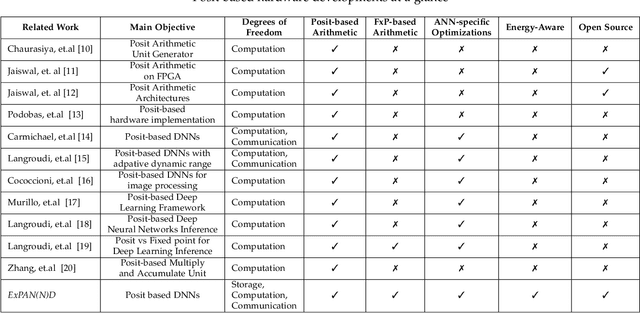
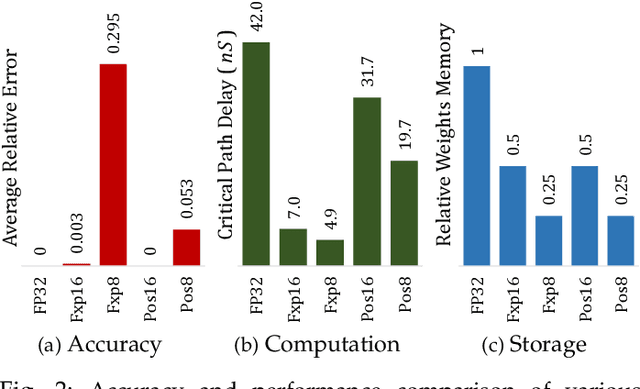
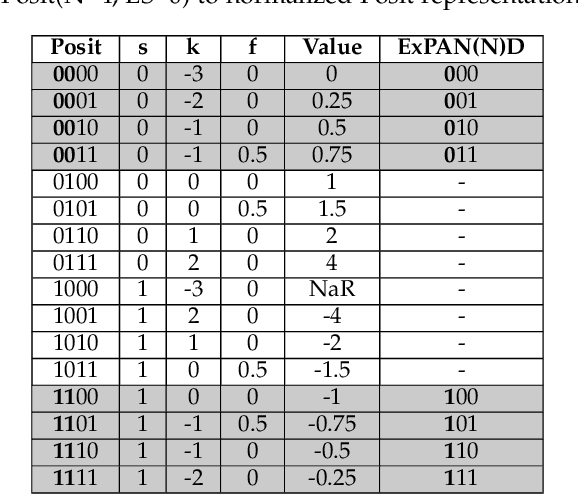
The recent advances in machine learning, in general, and Artificial Neural Networks (ANN), in particular, has made smart embedded systems an attractive option for a larger number of application areas. However, the high computational complexity, memory footprints, and energy requirements of machine learning models hinder their deployment on resource-constrained embedded systems. Most state-of-the-art works have considered this problem by proposing various low bit-width data representation schemes, optimized arithmetic operators' implementations, and different complexity reduction techniques such as network pruning. To further elevate the implementation gains offered by these individual techniques, there is a need to cross-examine and combine these techniques' unique features. This paper presents ExPAN(N)D, a framework to analyze and ingather the efficacy of the Posit number representation scheme and the efficiency of fixed-point arithmetic implementations for ANNs. The Posit scheme offers a better dynamic range and higher precision for various applications than IEEE $754$ single-precision floating-point format. However, due to the dynamic nature of the various fields of the Posit scheme, the corresponding arithmetic circuits have higher critical path delay and resource requirements than the single-precision-based arithmetic units. Towards this end, we propose a novel Posit to fixed-point converter for enabling high-performance and energy-efficient hardware implementations for ANNs with minimal drop in the output accuracy. We also propose a modified Posit-based representation to store the trained parameters of a network. Compared to an $8$-bit fixed-point-based inference accelerator, our proposed implementation offers $\approx46\%$ and $\approx18\%$ reductions in the storage requirements of the parameters and energy consumption of the MAC units, respectively.