 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Foundation Model Inference on a Many-tiny-core Open-source RISC-V Platform
May 29, 2024Transformer-based foundation models have become crucial for various domains, most notably natural language processing (NLP) or computer vision (CV). These models are predominantly deployed on high-performance GPUs or hardwired accelerators with highly customized, proprietary instruction sets. Until now, limited attention has been given to RISC-V-based general-purpose platforms. In our work, we present the first end-to-end inference results of transformer models on an open-source many-tiny-core RISC-V platform implementing distributed Softmax primitives and leveraging ISA extensions for SIMD floating-point operand streaming and instruction repetition, as well as specialized DMA engines to minimize costly main memory accesses and to tolerate their latency. We focus on two foundational transformer topologies, encoder-only and decoder-only models. For encoder-only models, we demonstrate a speedup of up to 12.8x between the most optimized implementation and the baseline version. We reach over 79% FPU utilization and 294 GFLOPS/W, outperforming State-of-the-Art (SoA) accelerators by more than 2x utilizing the HW platform while achieving comparable throughput per computational unit. For decoder-only topologies, we achieve 16.1x speedup in the Non-Autoregressive (NAR) mode and up to 35.6x speedup in the Autoregressive (AR) mode compared to the baseline implementation. Compared to the best SoA dedicated accelerator, we achieve 2.04x higher FPU utilization.
RedMule: A Mixed-Precision Matrix-Matrix Operation Engine for Flexible and Energy-Efficient On-Chip Linear Algebra and TinyML Training Acceleration
Jan 10, 2023
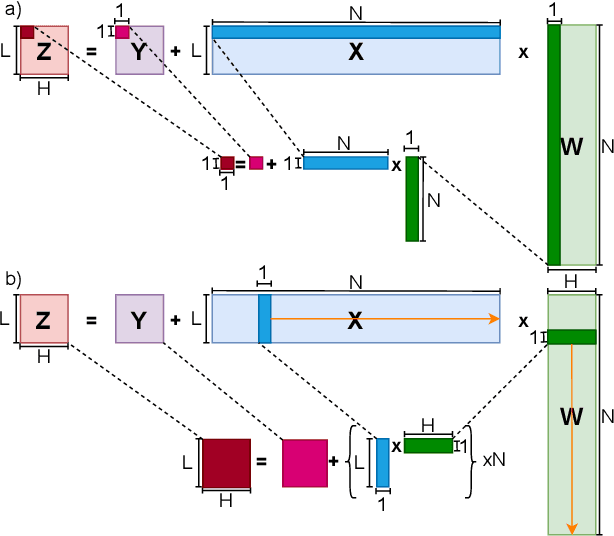
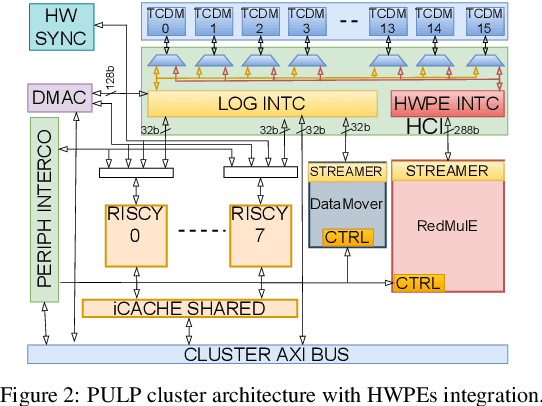
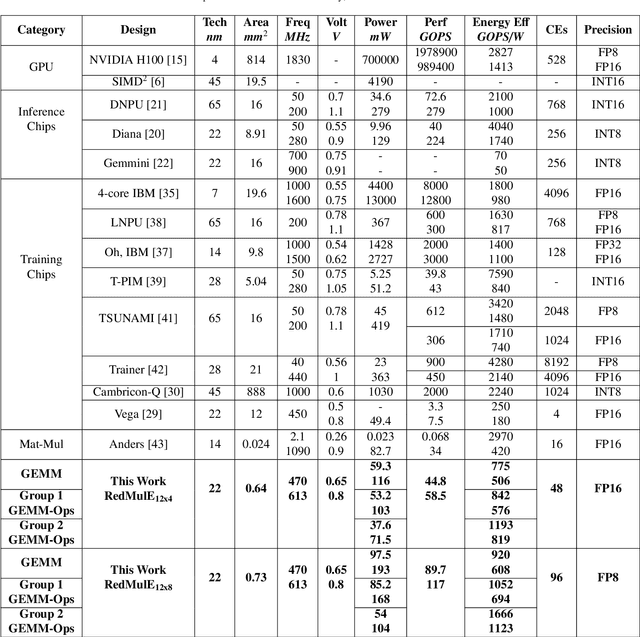
The increasing interest in TinyML, i.e., near-sensor machine learning on power budgets of a few tens of mW, is currently pushing toward enabling TinyML-class training as opposed to inference only. Current training algorithms, based on various forms of error and gradient backpropagation, rely on floating-point matrix operations to meet the precision and dynamic range requirements. So far, the energy and power cost of these operations has been considered too high for TinyML scenarios. This paper addresses the open challenge of near-sensor training on a few mW power budget and presents RedMulE - Reduced-Precision Matrix Multiplication Engine, a low-power specialized accelerator conceived for multi-precision floating-point General Matrix-Matrix Operations (GEMM-Ops) acceleration, supporting FP16, as well as hybrid FP8 formats, with {sign, exponent, mantissa}=({1,4,3}, {1,5,2}). We integrate RedMule into a Parallel Ultra-Low-Power (PULP) cluster containing eight energy-efficient RISC-V cores sharing a tightly-coupled data memory and implement the resulting system in a 22 nm technology. At its best efficiency point (@ 470 MHz, 0.65 V), the RedMulE-augmented PULP cluster achieves 755 GFLOPS/W and 920 GFLOPS/W during regular General Matrix-Matrix Multiplication (GEMM), and up to 1.19 TFLOPS/W and 1.67 TFLOPS/W when executing GEMM-Ops, respectively, for FP16 and FP8 input/output tensors. In its best performance point (@ 613 MHz, 0.8 V), RedMulE achieves up to 58.5 GFLOPS and 117 GFLOPS for FP16 and FP8, respectively, with 99.4% utilization of the array of Computing Elements and consuming less than 60 mW on average, thus enabling on-device training of deep learning models in TinyML application scenarios while retaining the flexibility to tackle other classes of common linear algebra problems efficiently.