 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe-NEureka: a Hybrid Modular Redundant DNN Accelerator for On-board Satellite AI Processing
Feb 04, 2026Low Earth Orbit (LEO) constellations are revolutionizing the space sector, with on-board Artificial Intelligence (AI) becoming pivotal for next-generation satellites. AI acceleration is essential for safety-critical functions such as autonomous Guidance, Navigation, and Control (GNC), where errors cannot be tolerated, and performance-critical processing of high-bandwidth sensor data, where occasional errors are tolerable. Consequently, AI accelerators for satellites must combine robust protection against radiation-induced faults with high throughput. This paper presents Safe-NEureka, a Hybrid Modular Redundant Deep Neural Network (DNN) accelerator for heterogeneous RISC-V systems. It operates in two modes: a redundancy mode utilizing Dual Modular Redundancy (DMR) with hardware-based recovery, and a performance mode repurposing redundant datapaths to maximize parallel throughput. Furthermore, its memory interface is protected by Error Correction Codes (ECCs), and the controller by Triple Modular Redundancy (TMR). Implementation in GlobalFoundries 12nm technology shows a 96 reduction in faulty executions in redundancy mode, with a manageable 15 area overhead. In performance mode, the architecture achieves near-baseline speeds on 3x3 dense convolutions with a 5 throughput and 11 efficiency reduction, compared to 48 and 53 in redundancy mode. This flexibility ensures high overheads are limited to critical tasks, establishing Safe-NEureka as a versatile solution for space applications.
A Heterogeneous RISC-V based SoC for Secure Nano-UAV Navigation
Jan 07, 2024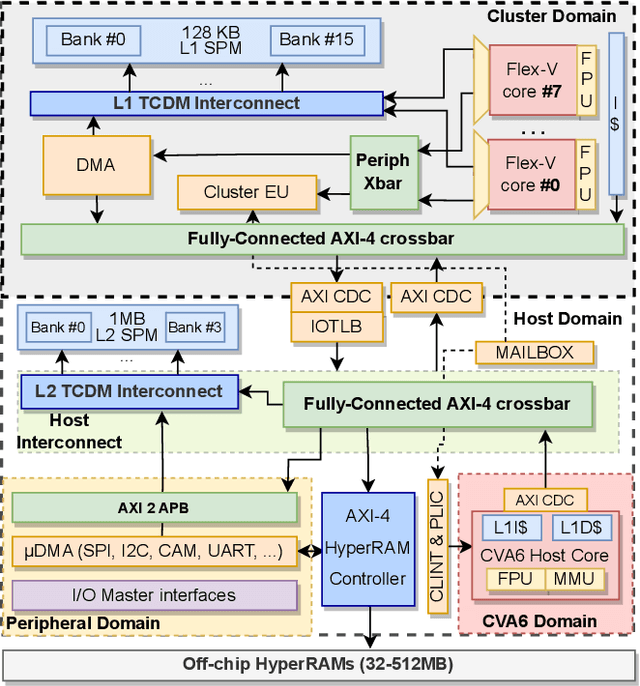
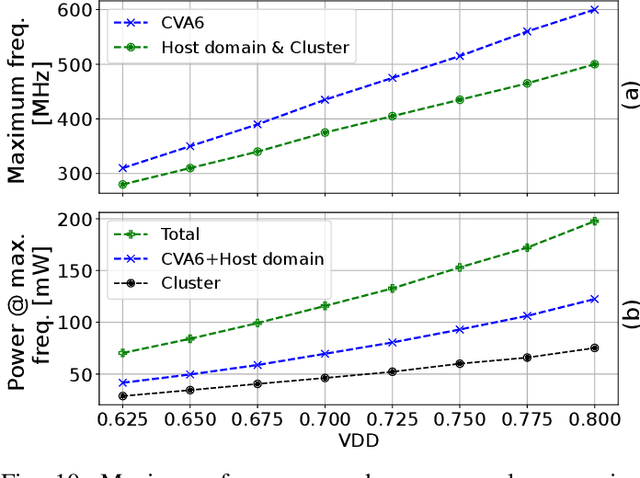
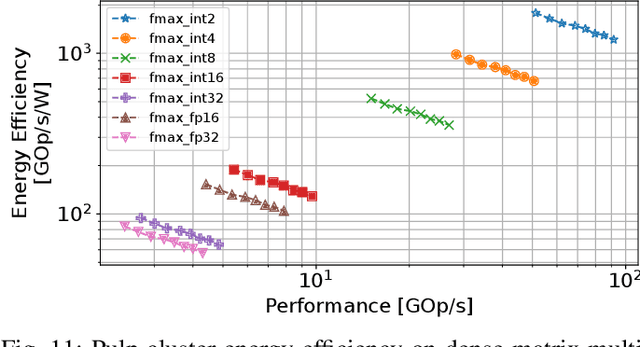
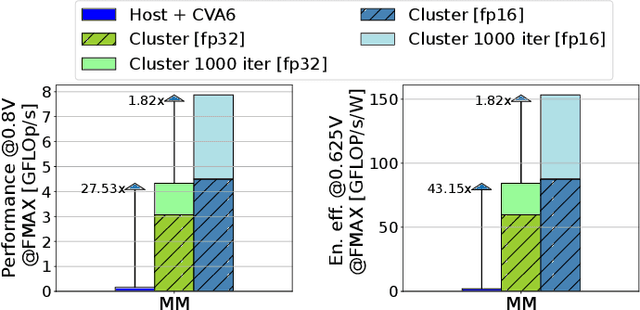
The rapid advancement of energy-efficient parallel ultra-low-power (ULP) ucontrollers units (MCUs) is enabling the development of autonomous nano-sized unmanned aerial vehicles (nano-UAVs). These sub-10cm drones represent the next generation of unobtrusive robotic helpers and ubiquitous smart sensors. However, nano-UAVs face significant power and payload constraints while requiring advanced computing capabilities akin to standard drones, including real-time Machine Learning (ML) performance and the safe co-existence of general-purpose and real-time OSs. Although some advanced parallel ULP MCUs offer the necessary ML computing capabilities within the prescribed power limits, they rely on small main memories (<1MB) and ucontroller-class CPUs with no virtualization or security features, and hence only support simple bare-metal runtimes. In this work, we present Shaheen, a 9mm2 200mW SoC implemented in 22nm FDX technology. Differently from state-of-the-art MCUs, Shaheen integrates a Linux-capable RV64 core, compliant with the v1.0 ratified Hypervisor extension and equipped with timing channel protection, along with a low-cost and low-power memory controller exposing up to 512MB of off-chip low-cost low-power HyperRAM directly to the CPU. At the same time, it integrates a fully programmable energy- and area-efficient multi-core cluster of RV32 cores optimized for general-purpose DSP as well as reduced- and mixed-precision ML. To the best of the authors' knowledge, it is the first silicon prototype of a ULP SoC coupling the RV64 and RV32 cores in a heterogeneous host+accelerator architecture fully based on the RISC-V ISA. We demonstrate the capabilities of the proposed SoC on a wide range of benchmarks relevant to nano-UAV applications. The cluster can deliver up to 90GOp/s and up to 1.8TOp/s/W on 2-bit integer kernels and up to 7.9GFLOp/s and up to 150GFLOp/s/W on 16-bit FP kernels.
RedMule: A Mixed-Precision Matrix-Matrix Operation Engine for Flexible and Energy-Efficient On-Chip Linear Algebra and TinyML Training Acceleration
Jan 10, 2023
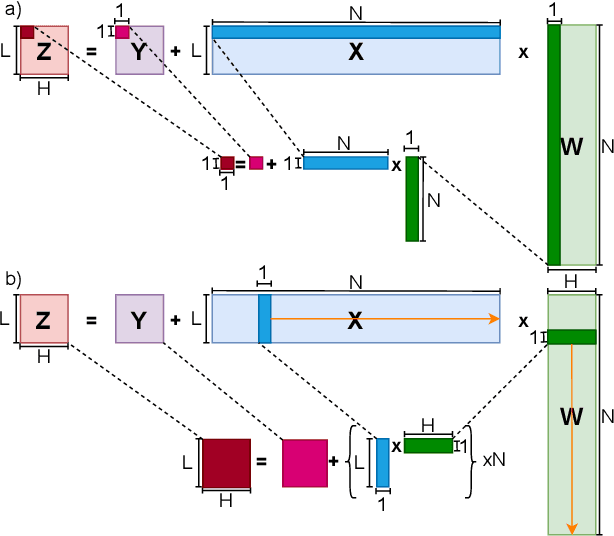
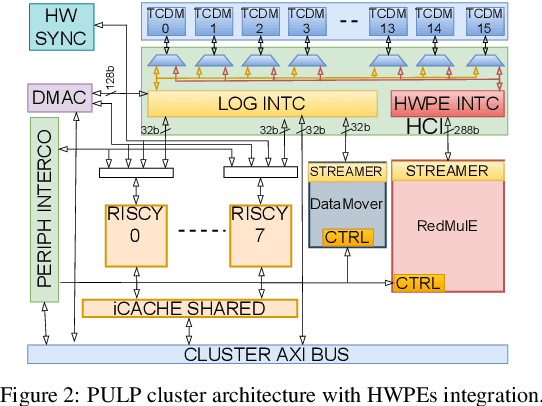
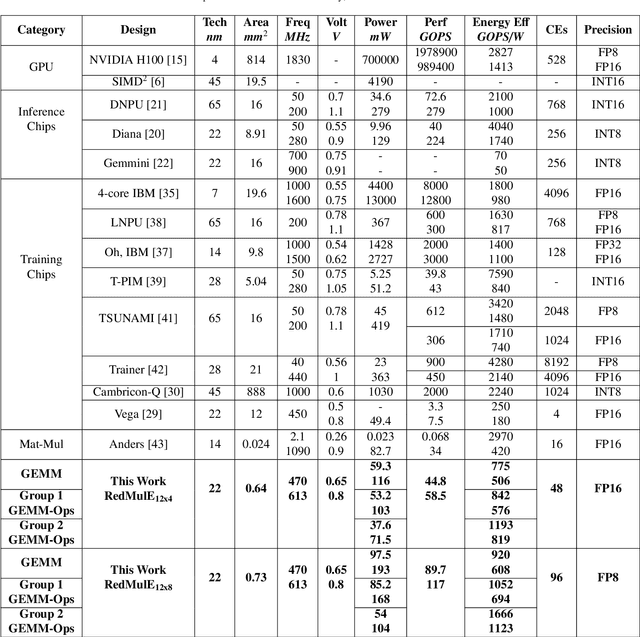
The increasing interest in TinyML, i.e., near-sensor machine learning on power budgets of a few tens of mW, is currently pushing toward enabling TinyML-class training as opposed to inference only. Current training algorithms, based on various forms of error and gradient backpropagation, rely on floating-point matrix operations to meet the precision and dynamic range requirements. So far, the energy and power cost of these operations has been considered too high for TinyML scenarios. This paper addresses the open challenge of near-sensor training on a few mW power budget and presents RedMulE - Reduced-Precision Matrix Multiplication Engine, a low-power specialized accelerator conceived for multi-precision floating-point General Matrix-Matrix Operations (GEMM-Ops) acceleration, supporting FP16, as well as hybrid FP8 formats, with {sign, exponent, mantissa}=({1,4,3}, {1,5,2}). We integrate RedMule into a Parallel Ultra-Low-Power (PULP) cluster containing eight energy-efficient RISC-V cores sharing a tightly-coupled data memory and implement the resulting system in a 22 nm technology. At its best efficiency point (@ 470 MHz, 0.65 V), the RedMulE-augmented PULP cluster achieves 755 GFLOPS/W and 920 GFLOPS/W during regular General Matrix-Matrix Multiplication (GEMM), and up to 1.19 TFLOPS/W and 1.67 TFLOPS/W when executing GEMM-Ops, respectively, for FP16 and FP8 input/output tensors. In its best performance point (@ 613 MHz, 0.8 V), RedMulE achieves up to 58.5 GFLOPS and 117 GFLOPS for FP16 and FP8, respectively, with 99.4% utilization of the array of Computing Elements and consuming less than 60 mW on average, thus enabling on-device training of deep learning models in TinyML application scenarios while retaining the flexibility to tackle other classes of common linear algebra problems efficiently.