 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA cryogenic SRAM based arbitrary waveform generator in 14 nm for spin qubit control
Nov 03, 2022



Realization of qubit gate sequences require coherent microwave control pulses with programmable amplitude, duration, spacing and phase. We propose an SRAM based arbitrary waveform generator for cryogenic control of spin qubits. We demonstrate in this work, the cryogenic operation of a fully programmable radio frequency arbitrary waveform generator in 14 nm FinFET technology. The waveform sequence from a control processor can be stored in an SRAM memory array, which can be programmed in real time. The waveform pattern is converted to microwave pulses by a source-series-terminated digital to analog converter. The chip is operational at 4 K, capable of generating an arbitrary envelope shape at the desired carrier frequency. Total power consumption of the AWG is 40-140mW at 4 K, depending upon the baud rate. A wide signal band of 1-17 GHz is measured at 4 K, while multiple qubit control can be achieved using frequency division multiplexing at an average spurious free dynamic range of 40 dB. This work paves the way to optimal qubit control and closed loop feedback control, which is necessary to achieve low latency error mitigation
* 4 pages, IEEE ESSCIRC 2022 conference
5 Parallel Prism: A topology for pipelined implementations of convolutional neural networks using computational memory
Jun 08, 2019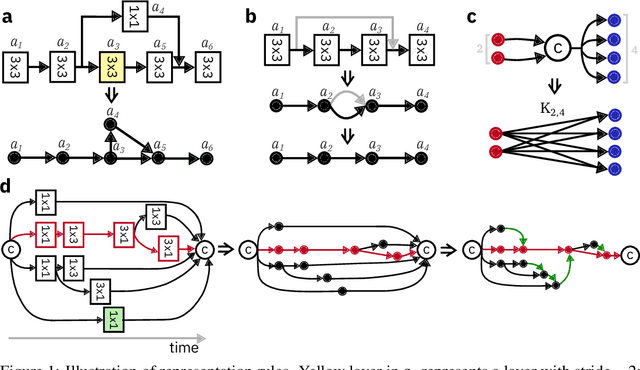
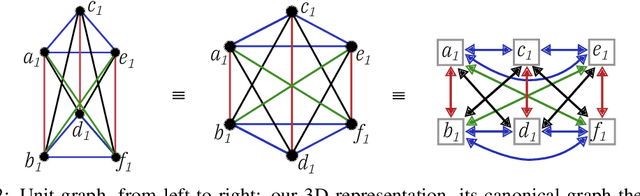
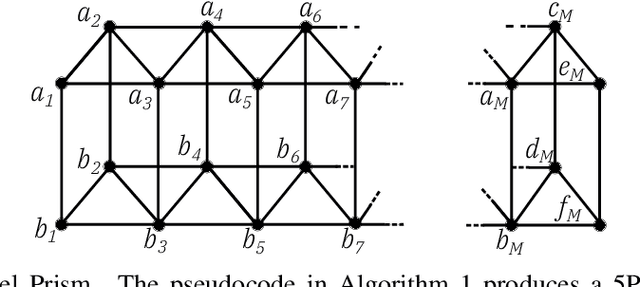
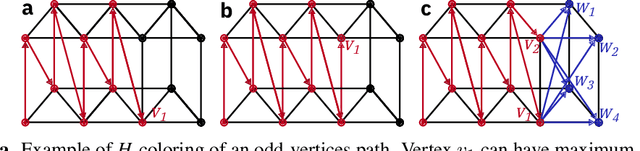
In-memory computing is an emerging computing paradigm that could enable deeplearning inference at significantly higher energy efficiency and reduced latency. The essential idea is to map the synaptic weights corresponding to each layer to one or more computational memory (CM) cores. During inference, these cores perform the associated matrix-vector multiply operations in place with O(1) time complexity, thus obviating the need to move the synaptic weights to an additional processing unit. Moreover, this architecture could enable the execution of these networks in a highly pipelined fashion. However, a key challenge is to design an efficient communication fabric for the CM cores. Here, we present one such communication fabric based on a graph topology that is well suited for the widely successful convolutional neural networks (CNNs). We show that this communication fabric facilitates the pipelined execution of all state of-the-art CNNs by proving the existence of a homomorphism between one graph representation of these networks and the proposed graph topology. We then present a quantitative comparison with established communication topologies and show that our proposed topology achieves the lowest bandwidth requirements per communication channel. Finally, we present a concrete example of mapping ResNet-32 onto an array of CM cores.