 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressing Structured Tensor Algebra
Paper and Code
Jul 18, 2024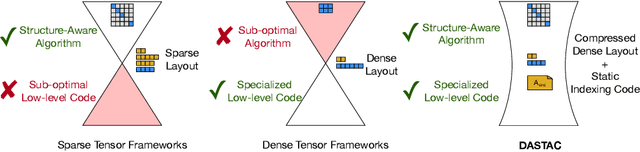


Tensor algebra is a crucial component for data-intensive workloads such as machine learning and scientific computing. As the complexity of data grows, scientists often encounter a dilemma between the highly specialized dense tensor algebra and efficient structure-aware algorithms provided by sparse tensor algebra. In this paper, we introduce DASTAC, a framework to propagate the tensors's captured high-level structure down to low-level code generation by incorporating techniques such as automatic data layout compression, polyhedral analysis, and affine code generation. Our methodology reduces memory footprint by automatically detecting the best data layout, heavily benefits from polyhedral optimizations, leverages further optimizations, and enables parallelization through MLIR. Through extensive experimentation, we show that DASTAC achieves 1 to 2 orders of magnitude speedup over TACO, a state-of-the-art sparse tensor compiler, and StructTensor, a state-of-the-art structured tensor algebra compiler, with a significantly lower memory footprint.