 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull-Stack Optimization for CAM-Only DNN Inference
Jan 23, 2024



The accuracy of neural networks has greatly improved across various domains over the past years. Their ever-increasing complexity, however, leads to prohibitively high energy demands and latency in von Neumann systems. Several computing-in-memory (CIM) systems have recently been proposed to overcome this, but trade-offs involving accuracy, hardware reliability, and scalability for large models remain a challenge. Additionally, for some CIM designs, the activation movement still requires considerable time and energy. This paper explores the combination of algorithmic optimizations for ternary weight neural networks and associative processors (APs) implemented using racetrack memory (RTM). We propose a novel compilation flow to optimize convolutions on APs by reducing their arithmetic intensity. By leveraging the benefits of RTM-based APs, this approach substantially reduces data transfers within the memory while addressing accuracy, energy efficiency, and reliability concerns. Concretely, our solution improves the energy efficiency of ResNet-18 inference on ImageNet by 7.5x compared to crossbar in-memory accelerators while retaining software accuracy.
Brain-inspired Cognition in Next Generation Racetrack Memories
Nov 03, 2021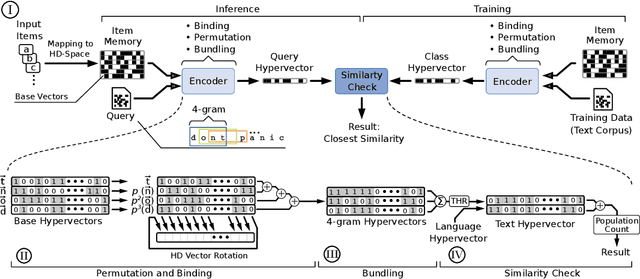
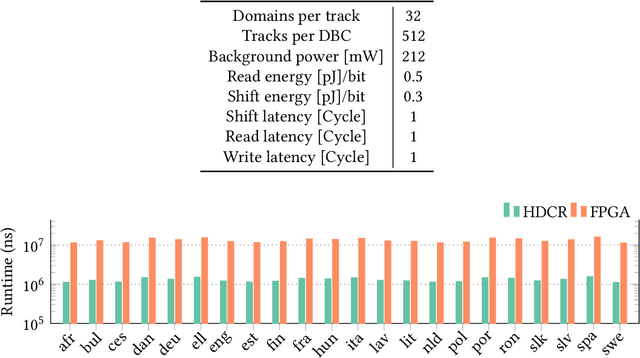
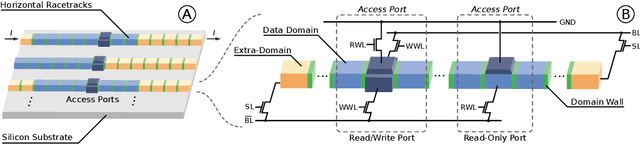
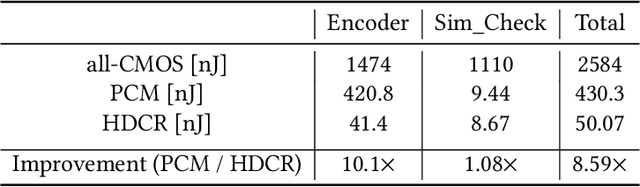
Hyperdimensional computing (HDC) is an emerging computational framework inspired by the brain that operates on vectors with thousands of dimensions to emulate cognition. Unlike conventional computational frameworks that operate on numbers, HDC, like the brain, uses high dimensional random vectors and is capable of one-shot learning. HDC is based on a well-defined set of arithmetic operations and is highly error-resilient. The core operations of HDC manipulate HD vectors in bulk bit-wise fashion, offering many opportunities to leverage parallelism. Unfortunately, on conventional Von-Neuman architectures, the continuous movement of HD vectors among the processor and the memory can make the cognition task prohibitively slow and energy-intensive. Hardware accelerators only marginally improve related metrics. On the contrary, only partial implementation of an HDC framework inside memory, using emerging memristive devices, has reported considerable performance/energy gains. This paper presents an architecture based on racetrack memory (RTM) to conduct and accelerate the entire HDC framework within the memory. The proposed solution requires minimal additional CMOS circuitry and uses a read operation across multiple domains in RTMs called transverse read (TR) to realize exclusive-or (XOR) and addition operations. To minimize the overhead the CMOS circuitry, we propose an RTM nanowires-based counting mechanism that leverages the TR operation and the standard RTM operations. Using language recognition as the use case demonstrates 7.8x and 5.3x reduction in the overall runtime and energy consumption compared to the FPGA design, respectively. Compared to the state-of-the-art in-memory implementation, the proposed HDC system reduces the energy consumption by 8.6x.