 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence of Things: A Survey
Oct 25, 2024



The integration of the Internet of Things (IoT) and modern Artificial Intelligence (AI) has given rise to a new paradigm known as the Artificial Intelligence of Things (AIoT). In this survey, we provide a systematic and comprehensive review of AIoT research. We examine AIoT literature related to sensing, computing, and networking & communication, which form the three key components of AIoT. In addition to advancements in these areas, we review domain-specific AIoT systems that are designed for various important application domains. We have also created an accompanying GitHub repository, where we compile the papers included in this survey: https://github.com/AIoT-MLSys-Lab/AIoT-Survey. This repository will be actively maintained and updated with new research as it becomes available. As both IoT and AI become increasingly critical to our society, we believe AIoT is emerging as an essential research field at the intersection of IoT and modern AI. We hope this survey will serve as a valuable resource for those engaged in AIoT research and act as a catalyst for future explorations to bridge gaps and drive advancements in this exciting field.
* Accepted in ACM Transactions on Sensor Networks (TOSN)
Performance Characterization of using Quantization for DNN Inference on Edge Devices: Extended Version
Mar 09, 2023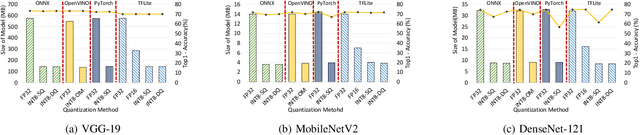

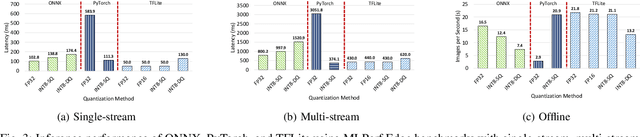
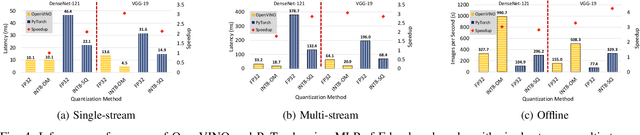
Quantization is a popular technique used in Deep Neural Networks (DNN) inference to reduce the size of models and improve the overall numerical performance by exploiting native hardware. This paper attempts to conduct an elaborate performance characterization of the benefits of using quantization techniques -- mainly FP16/INT8 variants with static and dynamic schemes -- using the MLPerf Edge Inference benchmarking methodology. The study is conducted on Intel x86 processors and Raspberry Pi device with ARM processor. The paper uses a number of DNN inference frameworks, including OpenVINO (for Intel CPUs only), TensorFlow Lite (TFLite), ONNX, and PyTorch with MobileNetV2, VGG-19, and DenseNet-121. The single-stream, multi-stream, and offline scenarios of the MLPerf Edge Inference benchmarks are used for measuring latency and throughput in our experiments. Our evaluation reveals that OpenVINO and TFLite are the most optimized frameworks for Intel CPUs and Raspberry Pi device, respectively. We observe no loss in accuracy except for the static quantization techniques. We also observed the benefits of using quantization for these optimized frameworks. For example, INT8-based quantized models deliver $3.3\times$ and $4\times$ better performance over FP32 using OpenVINO on Intel CPU and TFLite on Raspberry Pi device, respectively, for the MLPerf offline scenario. To the best of our knowledge, this paper is the first one that presents a unique characterization study characterizing the impact of quantization for a range of DNN inference frameworks -- including OpenVINO, TFLite, PyTorch, and ONNX -- on Intel x86 processors and Raspberry Pi device with ARM processor using the MLPerf Edge Inference benchmark methodology.
ScissionLite: Accelerating Distributed Deep Neural Networks Using Transfer Layer
May 05, 2021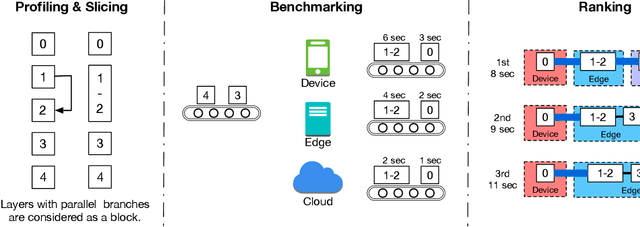
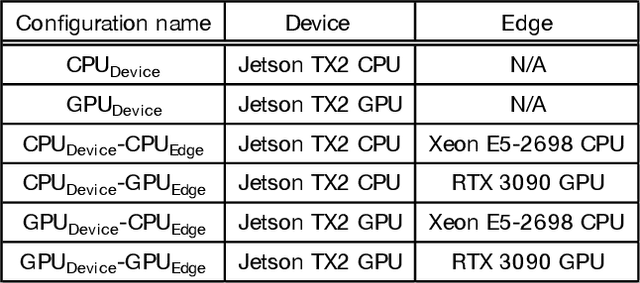
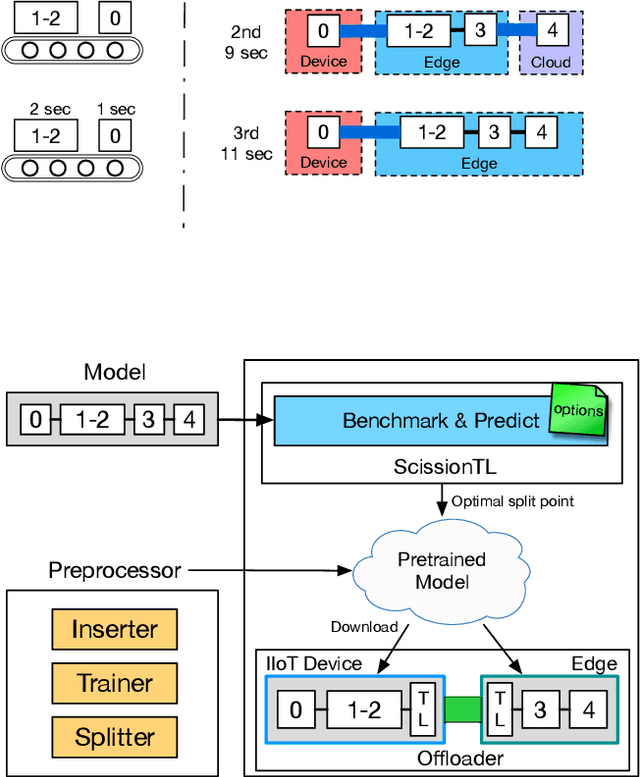

Industrial Internet of Things (IIoT) applications can benefit from leveraging edge computing. For example, applications underpinned by deep neural networks (DNN) models can be sliced and distributed across the IIoT device and the edge of the network for improving the overall performance of inference and for enhancing privacy of the input data, such as industrial product images. However, low network performance between IIoT devices and the edge is often a bottleneck. In this study, we develop ScissionLite, a holistic framework for accelerating distributed DNN inference using the Transfer Layer (TL). The TL is a traffic-aware layer inserted between the optimal slicing point of a DNN model slice in order to decrease the outbound network traffic without a significant accuracy drop. For the TL, we implement a new lightweight down/upsampling network for performance-limited IIoT devices. In ScissionLite, we develop ScissionTL, the Preprocessor, and the Offloader for end-to-end activities for deploying DNN slices with the TL. They decide the optimal slicing point of the DNN, prepare pre-trained DNN slices including the TL, and execute the DNN slices on an IIoT device and the edge. Employing the TL for the sliced DNN models has a negligible overhead. ScissionLite improves the inference latency by up to 16 and 2.8 times when compared to execution on the local device and an existing state-of-the-art model slicing approach respectively.