 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Large Language Model Training with Hybrid GPU-based Compression
Paper and Code
Sep 04, 2024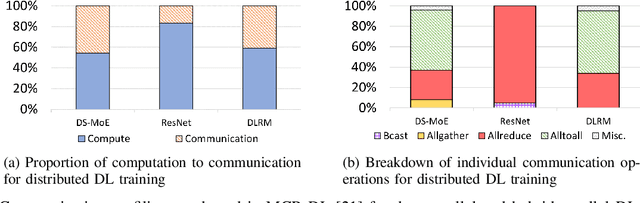
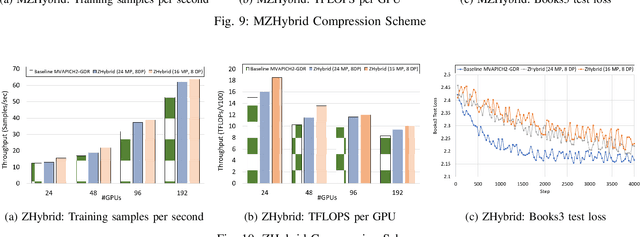
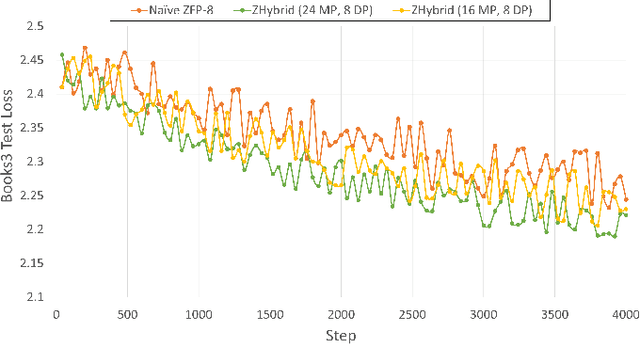
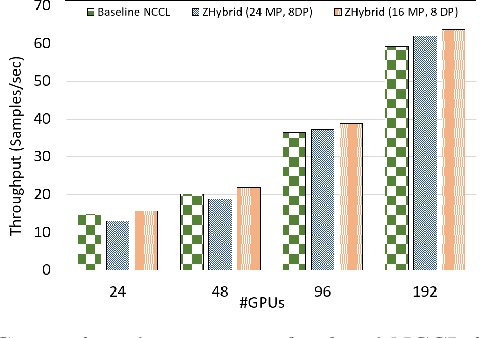
Data Parallelism (DP), Tensor Parallelism (TP), and Pipeline Parallelism (PP) are the three strategies widely adopted to enable fast and efficient Large Language Model (LLM) training. However, these approaches rely on data-intensive communication routines to collect, aggregate, and re-distribute gradients, activations, and other important model information, which pose significant overhead. Co-designed with GPU-based compression libraries, MPI libraries have been proven to reduce message size significantly, and leverage interconnect bandwidth, thus increasing training efficiency while maintaining acceptable accuracy. In this work, we investigate the efficacy of compression-assisted MPI collectives under the context of distributed LLM training using 3D parallelism and ZeRO optimizations. We scaled up to 192 V100 GPUs on the Lassen supercomputer. First, we enabled a na\"ive compression scheme across all collectives and observed a 22.5\% increase in TFLOPS per GPU and a 23.6\% increase in samples per second for GPT-NeoX-20B training. Nonetheless, such a strategy ignores the sparsity discrepancy among messages communicated in each parallelism degree, thus introducing more errors and causing degradation in training loss. Therefore, we incorporated hybrid compression settings toward each parallel dimension and adjusted the compression intensity accordingly. Given their low-rank structure (arXiv:2301.02654), we apply aggressive compression on gradients when performing DP All-reduce. We adopt milder compression to preserve precision while communicating activations, optimizer states, and model parameters in TP and PP. Using the adjusted hybrid compression scheme, we demonstrate a 17.3\% increase in TFLOPS per GPU and a 12.7\% increase in samples per second while reaching baseline loss convergence.