 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Transformers: SwiftKey's Differential Privacy Implementation
May 08, 2025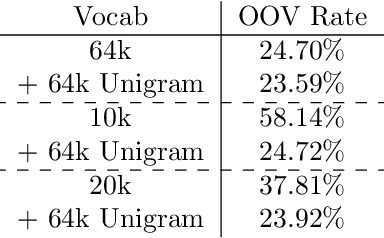
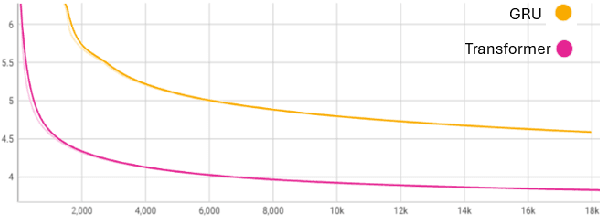
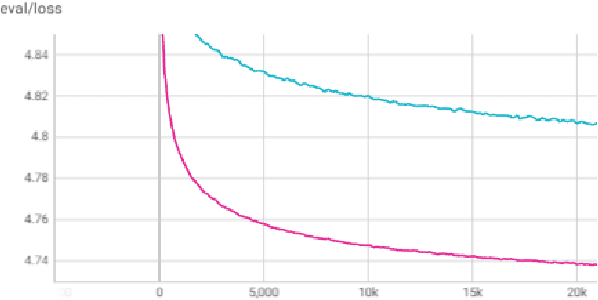
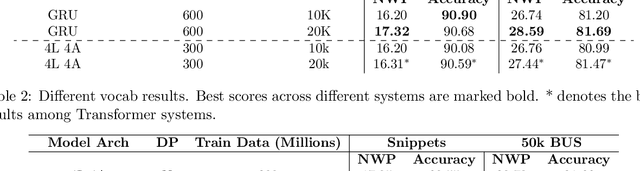
In this paper we train a transformer using differential privacy (DP) for language modeling in SwiftKey. We run multiple experiments to balance the trade-off between the model size, run-time speed and accuracy. We show that we get small and consistent gains in the next-word-prediction and accuracy with graceful increase in memory and speed compared to the production GRU. This is obtained by scaling down a GPT2 architecture to fit the required size and a two stage training process that builds a seed model on general data and DP finetunes it on typing data. The transformer is integrated using ONNX offering both flexibility and efficiency.
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
How Good Are GPT Models at Machine Translation? A Comprehensive Evaluation
Feb 18, 2023



Generative Pre-trained Transformer (GPT) models have shown remarkable capabilities for natural language generation, but their performance for machine translation has not been thoroughly investigated. In this paper, we present a comprehensive evaluation of GPT models for machine translation, covering various aspects such as quality of different GPT models in comparison with state-of-the-art research and commercial systems, effect of prompting strategies, robustness towards domain shifts and document-level translation. We experiment with eighteen different translation directions involving high and low resource languages, as well as non English-centric translations, and evaluate the performance of three GPT models: ChatGPT, GPT3.5 (text-davinci-003), and text-davinci-002. Our results show that GPT models achieve very competitive translation quality for high resource languages, while having limited capabilities for low resource languages. We also show that hybrid approaches, which combine GPT models with other translation systems, can further enhance the translation quality. We perform comprehensive analysis and human evaluation to further understand the characteristics of GPT translations. We hope that our paper provides valuable insights for researchers and practitioners in the field and helps to better understand the potential and limitations of GPT models for translation.
Domain Specific Sub-network for Multi-Domain Neural Machine Translation
Oct 18, 2022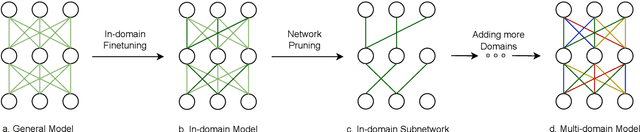
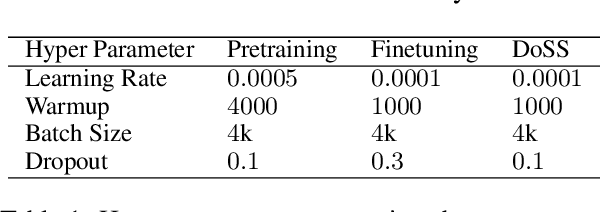
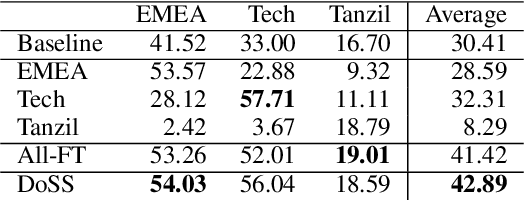
This paper presents Domain-Specific Sub-network (DoSS). It uses a set of masks obtained through pruning to define a sub-network for each domain and finetunes the sub-network parameters on domain data. This performs very closely and drastically reduces the number of parameters compared to finetuning the whole network on each domain. Also a method to make masks unique per domain is proposed and shown to greatly improve the generalization to unseen domains. In our experiments on German to English machine translation the proposed method outperforms the strong baseline of continue training on multi-domain (medical, tech and religion) data by 1.47 BLEU points. Also continue training DoSS on new domain (legal) outperforms the multi-domain (medical, tech, religion, legal) baseline by 1.52 BLEU points.
Language Tokens: A Frustratingly Simple Approach Improves Zero-Shot Performance of Multilingual Translation
Aug 11, 2022
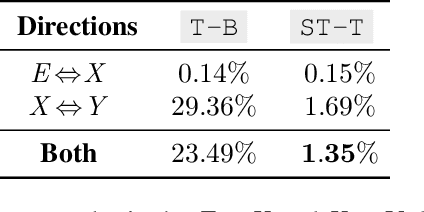
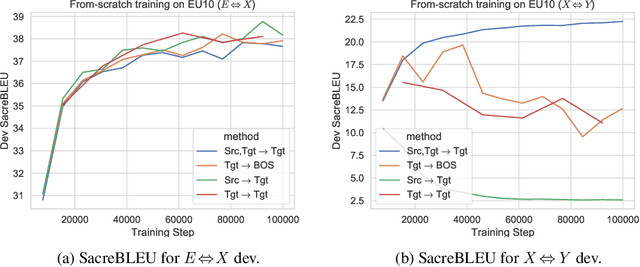
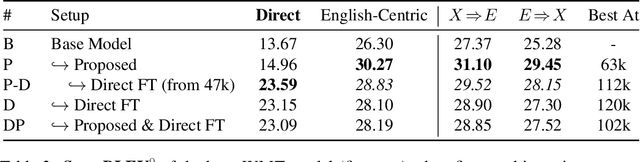
This paper proposes a simple yet effective method to improve direct (X-to-Y) translation for both cases: zero-shot and when direct data is available. We modify the input tokens at both the encoder and decoder to include signals for the source and target languages. We show a performance gain when training from scratch, or finetuning a pretrained model with the proposed setup. In the experiments, our method shows nearly 10.0 BLEU points gain on in-house datasets depending on the checkpoint selection criteria. In a WMT evaluation campaign, From-English performance improves by 4.17 and 2.87 BLEU points, in the zero-shot setting, and when direct data is available for training, respectively. While X-to-Y improves by 1.29 BLEU over the zero-shot baseline, and 0.44 over the many-to-many baseline. In the low-resource setting, we see a 1.5~1.7 point improvement when finetuning on X-to-Y domain data.
Ensembling of Distilled Models from Multi-task Teachers for Constrained Resource Language Pairs
Nov 26, 2021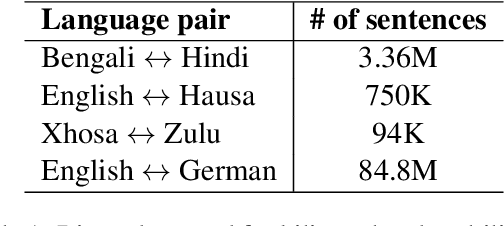
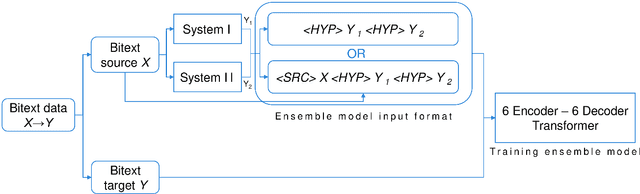
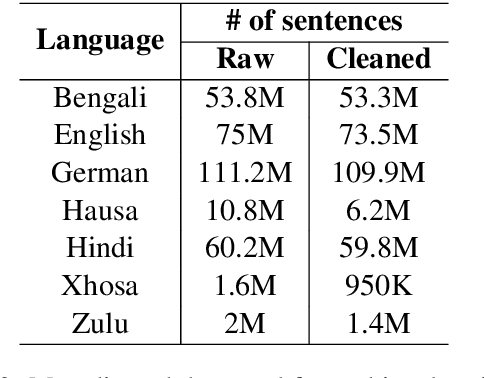
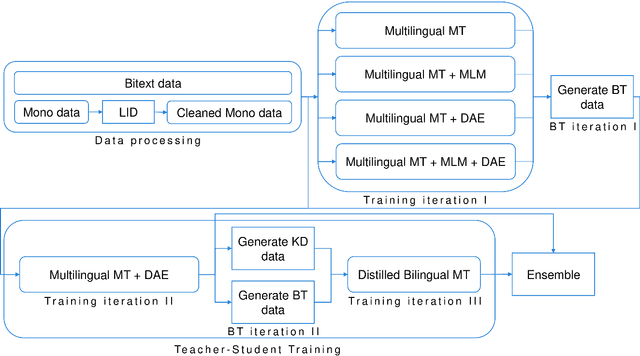
This paper describes our submission to the constrained track of WMT21 shared news translation task. We focus on the three relatively low resource language pairs Bengali to and from Hindi, English to and from Hausa, and Xhosa to and from Zulu. To overcome the limitation of relatively low parallel data we train a multilingual model using a multitask objective employing both parallel and monolingual data. In addition, we augment the data using back translation. We also train a bilingual model incorporating back translation and knowledge distillation then combine the two models using sequence-to-sequence mapping. We see around 70% relative gain in BLEU point for English to and from Hausa, and around 25% relative improvements for both Bengali to and from Hindi, and Xhosa to and from Zulu compared to bilingual baselines.
Scalable and Efficient MoE Training for Multitask Multilingual Models
Sep 22, 2021
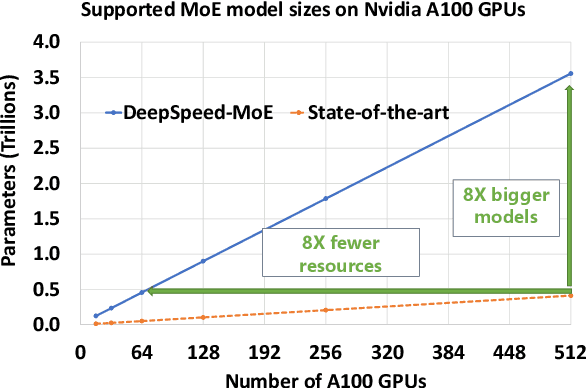
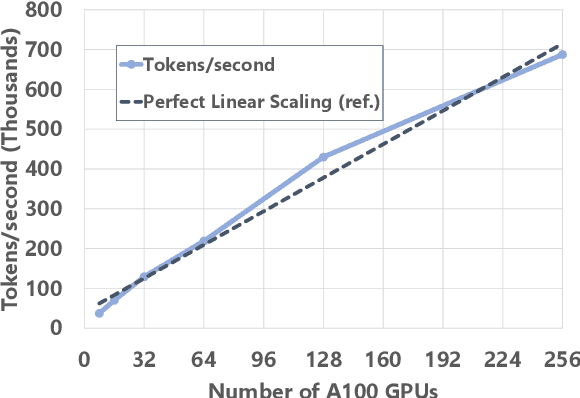
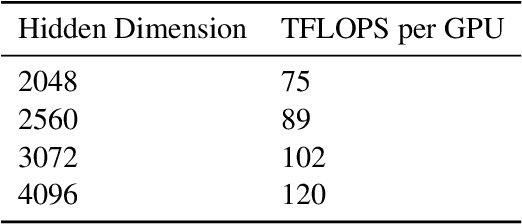
The Mixture of Experts (MoE) models are an emerging class of sparsely activated deep learning models that have sublinear compute costs with respect to their parameters. In contrast with dense models, the sparse architecture of MoE offers opportunities for drastically growing model size with significant accuracy gain while consuming much lower compute budget. However, supporting large scale MoE training also has its own set of system and modeling challenges. To overcome the challenges and embrace the opportunities of MoE, we first develop a system capable of scaling MoE models efficiently to trillions of parameters. It combines multi-dimensional parallelism and heterogeneous memory technologies harmoniously with MoE to empower 8x larger models on the same hardware compared with existing work. Besides boosting system efficiency, we also present new training methods to improve MoE sample efficiency and leverage expert pruning strategy to improve inference time efficiency. By combining the efficient system and training methods, we are able to significantly scale up large multitask multilingual models for language generation which results in a great improvement in model accuracy. A model trained with 10 billion parameters on 50 languages can achieve state-of-the-art performance in Machine Translation (MT) and multilingual natural language generation tasks. The system support of efficient MoE training has been implemented and open-sourced with the DeepSpeed library.
Score Combination for Improved Parallel Corpus Filtering for Low Resource Conditions
Nov 16, 2020
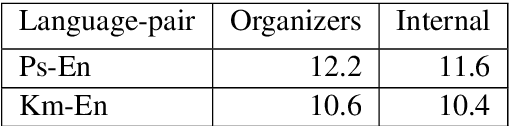
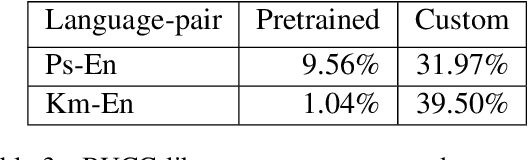

This paper describes our submission to the WMT20 sentence filtering task. We combine scores from (1) a custom LASER built for each source language, (2) a classifier built to distinguish positive and negative pairs by semantic alignment, and (3) the original scores included in the task devkit. For the mBART finetuning setup, provided by the organizers, our method shows 7% and 5% relative improvement over baseline, in sacreBLEU score on the test set for Pashto and Khmer respectively.