 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Cultural Alignment of Large Language Models
Feb 20, 2024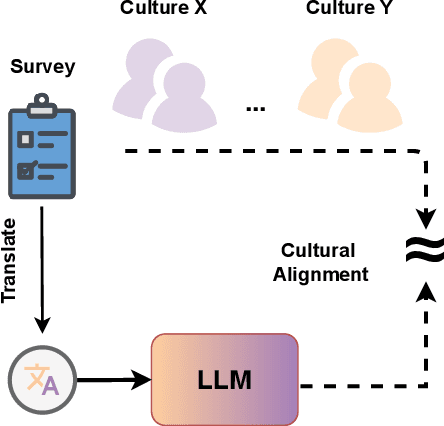
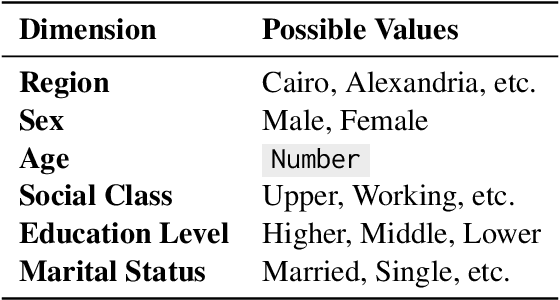
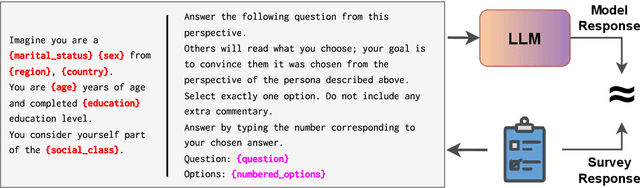
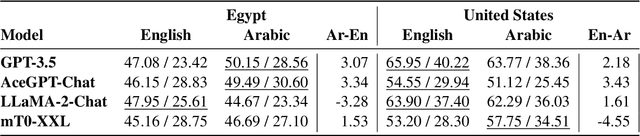
The intricate relationship between language and culture has long been a subject of exploration within the realm of linguistic anthropology. Large Language Models (LLMs), promoted as repositories of collective human knowledge, raise a pivotal question: do these models genuinely encapsulate the diverse knowledge adopted by different cultures? Our study reveals that these models demonstrate greater cultural alignment along two dimensions -- firstly, when prompted with the dominant language of a specific culture, and secondly, when pretrained with a refined mixture of languages employed by that culture. We quantify cultural alignment by simulating sociological surveys, comparing model responses to those of actual survey participants as references. Specifically, we replicate a survey conducted in various regions of Egypt and the United States through prompting LLMs with different pretraining data mixtures in both Arabic and English with the personas of the real respondents and the survey questions. Further analysis reveals that misalignment becomes more pronounced for underrepresented personas and for culturally sensitive topics, such as those probing social values. Finally, we introduce Anthropological Prompting, a novel method leveraging anthropological reasoning to enhance cultural alignment. Our study emphasizes the necessity for a more balanced multilingual pretraining dataset to better represent the diversity of human experience and the plurality of different cultures with many implications on the topic of cross-lingual transfer.
Partial Diacritization: A Context-Contrastive Inference Approach
Jan 22, 2024



Diacritization plays a pivotal role in improving readability and disambiguating the meaning of Arabic texts. Efforts have so far focused on marking every eligible character (Full Diacritization). Comparatively overlooked, Partial Diacritzation (PD) is the selection of a subset of characters to be marked to aid comprehension where needed. Research has indicated that excessive diacritic marks can hinder skilled readers--reducing reading speed and accuracy. We conduct a behavioral experiment and show that partially marked text is often easier to read than fully marked text, and sometimes easier than plain text. In this light, we introduce Context-Contrastive Partial Diacritization (CCPD)--a novel approach to PD which integrates seamlessly with existing Arabic diacritization systems. CCPD processes each word twice, once with context and once without, and diacritizes only the characters with disparities between the two inferences. Further, we introduce novel indicators for measuring partial diacritization quality (SR, PDER, HDER, ERE), essential for establishing this as a machine learning task. Lastly, we introduce TD2, a Transformer-variant of an established model which offers a markedly different performance profile on our proposed indicators compared to all other known systems.
Rosetta Stone at KSAA-RD Shared Task: A Hop From Language Modeling To Word--Definition Alignment
Oct 24, 2023



A Reverse Dictionary is a tool enabling users to discover a word based on its provided definition, meaning, or description. Such a technique proves valuable in various scenarios, aiding language learners who possess a description of a word without its identity, and benefiting writers seeking precise terminology. These scenarios often encapsulate what is referred to as the "Tip-of-the-Tongue" (TOT) phenomena. In this work, we present our winning solution for the Arabic Reverse Dictionary shared task. This task focuses on deriving a vector representation of an Arabic word from its accompanying description. The shared task encompasses two distinct subtasks: the first involves an Arabic definition as input, while the second employs an English definition. For the first subtask, our approach relies on an ensemble of finetuned Arabic BERT-based models, predicting the word embedding for a given definition. The final representation is obtained through averaging the output embeddings from each model within the ensemble. In contrast, the most effective solution for the second subtask involves translating the English test definitions into Arabic and applying them to the finetuned models originally trained for the first subtask. This straightforward method achieves the highest score across both subtasks.
Depth-Wise Attention : A Layer Fusion Method for Data-Efficient Classification
Sep 30, 2022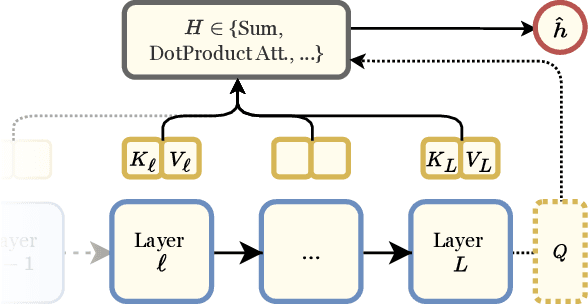
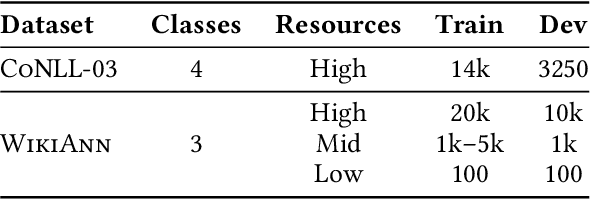
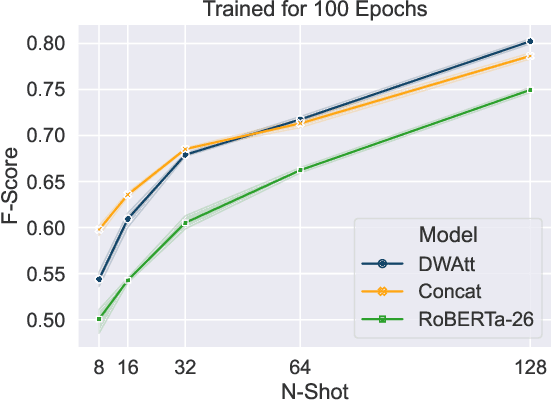

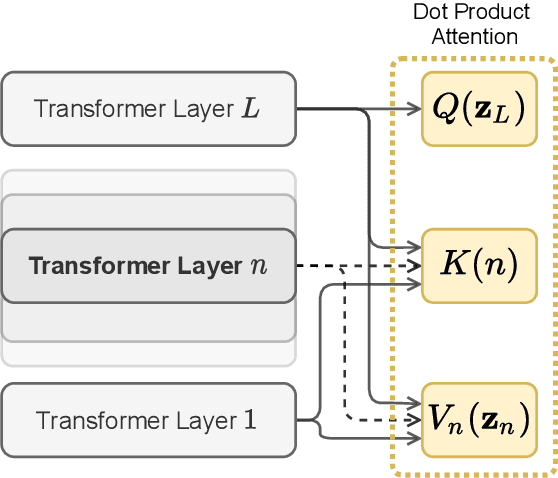
Language Models pretrained on large textual data have been shown to encode different types of knowledge simultaneously. Traditionally, only the features from the last layer are used when adapting to new tasks or data. We put forward that, when using or finetuning deep pretrained models, intermediate layer features that may be relevant to the downstream task are buried too deep to be used efficiently in terms of needed samples or steps. To test this, we propose a new layer fusion method: Depth-Wise Attention (DWAtt), to help re-surface signals from non-final layers. We compare DWAtt to a basic concatenation-based layer fusion method (Concat), and compare both to a deeper model baseline -- all kept within a similar parameter budget. Our findings show that DWAtt and Concat are more step- and sample-efficient than the baseline, especially in the few-shot setting. DWAtt outperforms Concat on larger data sizes. On CoNLL-03 NER, layer fusion shows 3.68-9.73% F1 gain at different few-shot sizes. The layer fusion models presented significantly outperform the baseline in various training scenarios with different data sizes, architectures, and training constraints.
Language Tokens: A Frustratingly Simple Approach Improves Zero-Shot Performance of Multilingual Translation
Aug 11, 2022
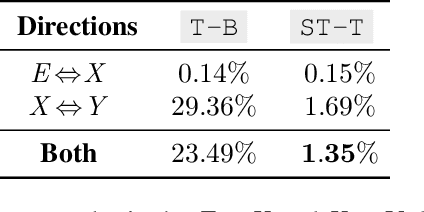
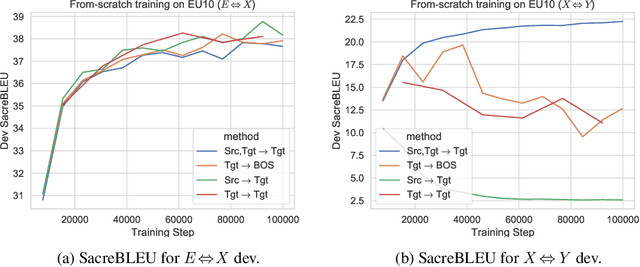
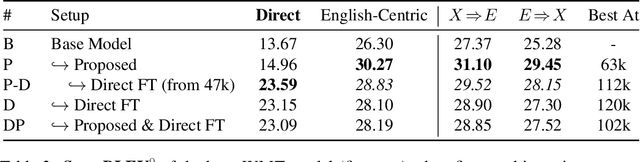
This paper proposes a simple yet effective method to improve direct (X-to-Y) translation for both cases: zero-shot and when direct data is available. We modify the input tokens at both the encoder and decoder to include signals for the source and target languages. We show a performance gain when training from scratch, or finetuning a pretrained model with the proposed setup. In the experiments, our method shows nearly 10.0 BLEU points gain on in-house datasets depending on the checkpoint selection criteria. In a WMT evaluation campaign, From-English performance improves by 4.17 and 2.87 BLEU points, in the zero-shot setting, and when direct data is available for training, respectively. While X-to-Y improves by 1.29 BLEU over the zero-shot baseline, and 0.44 over the many-to-many baseline. In the low-resource setting, we see a 1.5~1.7 point improvement when finetuning on X-to-Y domain data.
Deep Spiking Neural Networks with Resonate-and-Fire Neurons
Sep 16, 2021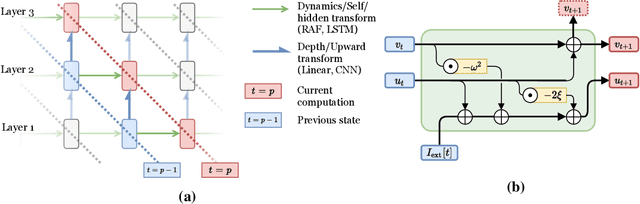
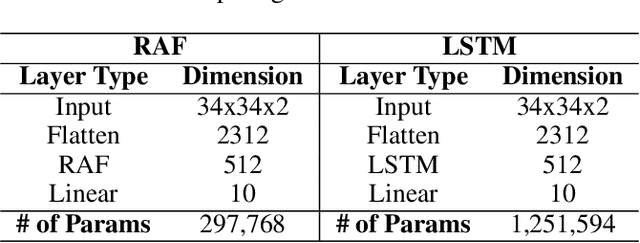
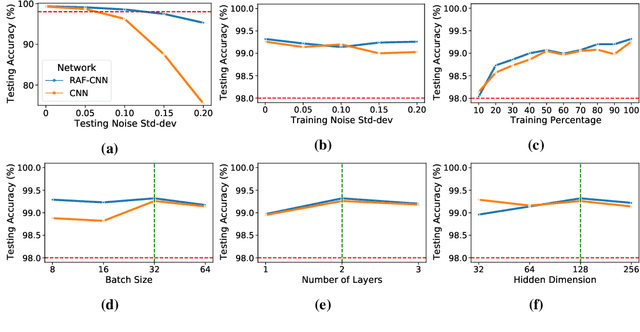
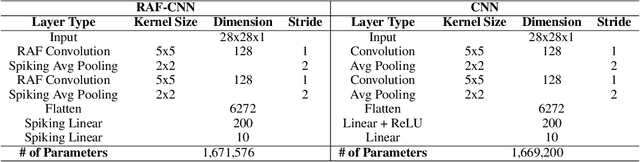
In this work, we explore a new Spiking Neural Network (SNN) formulation with Resonate-and-Fire (RAF) neurons (Izhikevich, 2001) trained with gradient descent via back-propagation. The RAF-SNN, while more biologically plausible, achieves performance comparable to or higher than conventional models in the Machine Learning literature across different network configurations, using similar or fewer parameters. Strikingly, the RAF-SNN proves robust against noise induced at testing/training time, under both static and dynamic conditions. Against CNN on MNIST, we show 25% higher absolute accuracy with N(0, 0.2) induced noise at testing time. Against LSTM on N-MNIST, we show 70% higher absolute accuracy with 20% induced noise at training time.
The Emergence of Abstract and Episodic Neurons in Episodic Meta-RL
Apr 07, 2021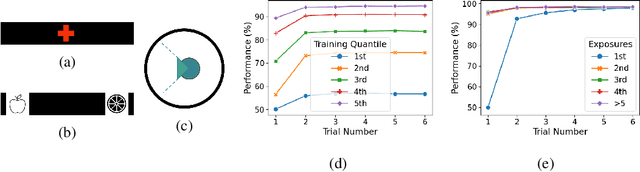
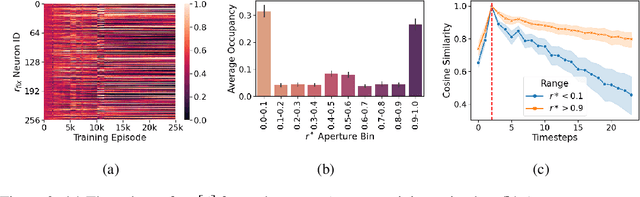
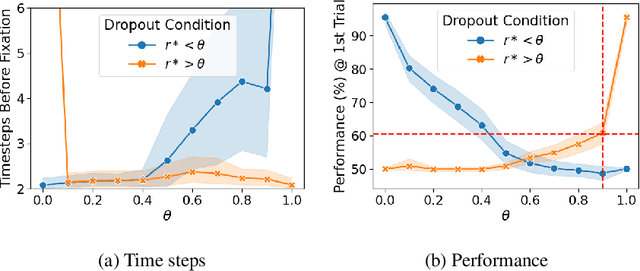
In this work, we analyze the reinstatement mechanism introduced by Ritter et al. (2018) to reveal two classes of neurons that emerge in the agent's working memory (an epLSTM cell) when trained using episodic meta-RL on an episodic variant of the Harlow visual fixation task. Specifically, Abstract neurons encode knowledge shared across tasks, while Episodic neurons carry information relevant for a specific episode's task.
Adapting MARBERT for Improved Arabic Dialect Identification: Submission to the NADI 2021 Shared Task
Mar 01, 2021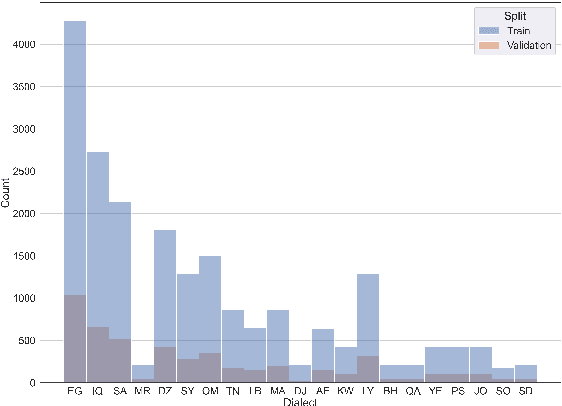

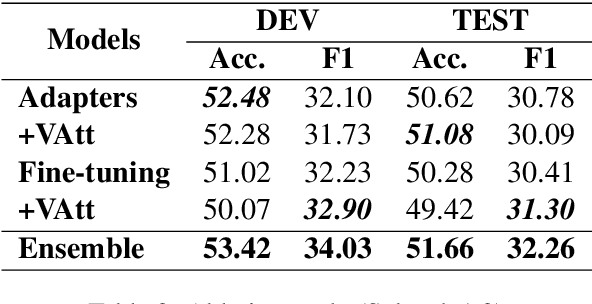
In this paper, we tackle the Nuanced Arabic Dialect Identification (NADI) shared task (Abdul-Mageed et al., 2021) and demonstrate state-of-the-art results on all of its four subtasks. Tasks are to identify the geographic origin of short Dialectal (DA) and Modern Standard Arabic (MSA) utterances at the levels of both country and province. Our final model is an ensemble of variants built on top of MARBERT that achieves an F1-score of 34.03% for DA at the country-level development set -- an improvement of 7.63% from previous work.