 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Transformers: SwiftKey's Differential Privacy Implementation
May 08, 2025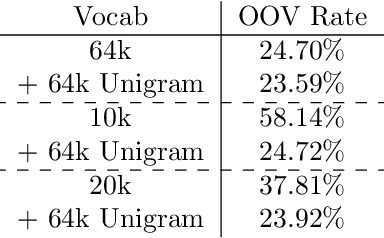
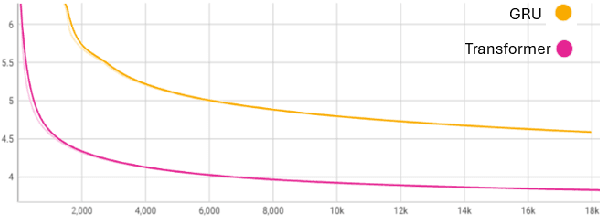
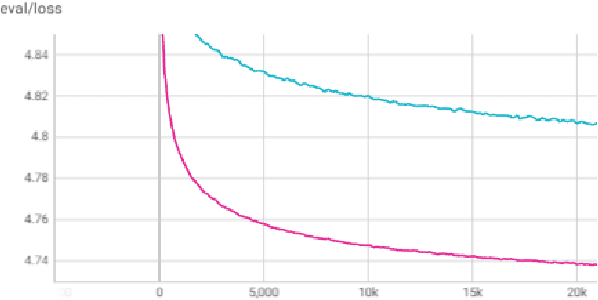
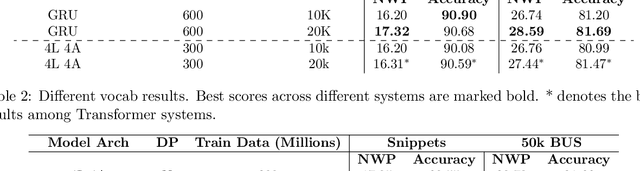
In this paper we train a transformer using differential privacy (DP) for language modeling in SwiftKey. We run multiple experiments to balance the trade-off between the model size, run-time speed and accuracy. We show that we get small and consistent gains in the next-word-prediction and accuracy with graceful increase in memory and speed compared to the production GRU. This is obtained by scaling down a GPT2 architecture to fit the required size and a two stage training process that builds a seed model on general data and DP finetunes it on typing data. The transformer is integrated using ONNX offering both flexibility and efficiency.
On-Device Emoji Classifier Trained with GPT-based Data Augmentation for a Mobile Keyboard
Nov 06, 2024
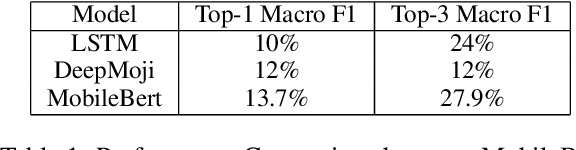
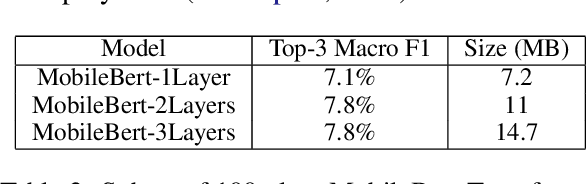

Emojis improve communication quality among smart-phone users that use mobile keyboards to exchange text. To predict emojis for users based on input text, we should consider the on-device low memory and time constraints, ensure that the on-device emoji classifier covers a wide range of emoji classes even though the emoji dataset is typically imbalanced, and adapt the emoji classifier output to user favorites. This paper proposes an on-device emoji classifier based on MobileBert with reasonable memory and latency requirements for SwiftKey. To account for the data imbalance, we utilize the widely used GPT to generate one or more tags for each emoji class. For each emoji and corresponding tags, we merge the original set with GPT-generated sentences and label them with this emoji without human intervention to alleviate the data imbalance. At inference time, we interpolate the emoji output with the user history for emojis for better emoji classifications. Results show that the proposed on-device emoji classifier deployed for SwiftKey increases the accuracy performance of emoji prediction particularly on rare emojis and emoji engagement.
Simply Trainable Nearest Neighbour Machine Translation with GPU Inference
Jul 29, 2024


Nearest neighbor machine translation is a successful approach for fast domain adaption, which interpolates the pre-trained transformers with domain-specific token-level k-nearest-neighbor (kNN) retrieval without retraining. Despite kNN MT's success, searching large reference corpus and fixed interpolation between the kNN and pre-trained model led to computational complexity and translation quality challenges. Among other papers, Dai et al. proposed methods to obtain a small number of reference samples dynamically for which they introduced a distance-aware interpolation method using an equation that includes free parameters. This paper proposes a simply trainable nearest neighbor machine translation and carry out inference experiments on GPU. Similar to Dai et al., we first adaptively construct a small datastore for each input sentence. Second, we train a single-layer network for the interpolation coefficient between the knnMT and pre-trained result to automatically interpolate in different domains. Experimental results on different domains show that our proposed method either improves or sometimes maintain the translation quality of methods in Dai et al. while being automatic. In addition, our GPU inference results demonstrate that knnMT can be integrated into GPUs with a drop of only 5% in terms of speed.
How Good Are GPT Models at Machine Translation? A Comprehensive Evaluation
Feb 18, 2023



Generative Pre-trained Transformer (GPT) models have shown remarkable capabilities for natural language generation, but their performance for machine translation has not been thoroughly investigated. In this paper, we present a comprehensive evaluation of GPT models for machine translation, covering various aspects such as quality of different GPT models in comparison with state-of-the-art research and commercial systems, effect of prompting strategies, robustness towards domain shifts and document-level translation. We experiment with eighteen different translation directions involving high and low resource languages, as well as non English-centric translations, and evaluate the performance of three GPT models: ChatGPT, GPT3.5 (text-davinci-003), and text-davinci-002. Our results show that GPT models achieve very competitive translation quality for high resource languages, while having limited capabilities for low resource languages. We also show that hybrid approaches, which combine GPT models with other translation systems, can further enhance the translation quality. We perform comprehensive analysis and human evaluation to further understand the characteristics of GPT translations. We hope that our paper provides valuable insights for researchers and practitioners in the field and helps to better understand the potential and limitations of GPT models for translation.
Domain Specific Sub-network for Multi-Domain Neural Machine Translation
Oct 18, 2022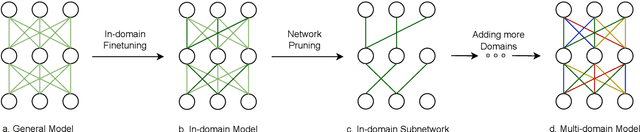
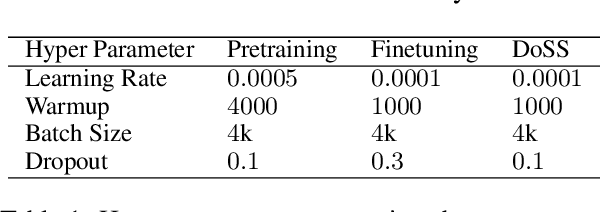
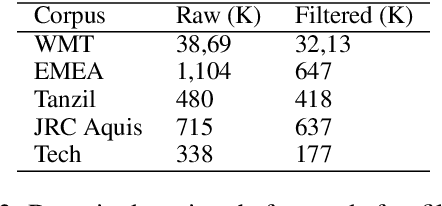
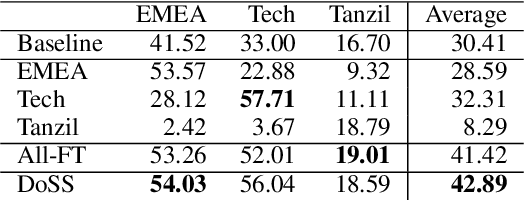
This paper presents Domain-Specific Sub-network (DoSS). It uses a set of masks obtained through pruning to define a sub-network for each domain and finetunes the sub-network parameters on domain data. This performs very closely and drastically reduces the number of parameters compared to finetuning the whole network on each domain. Also a method to make masks unique per domain is proposed and shown to greatly improve the generalization to unseen domains. In our experiments on German to English machine translation the proposed method outperforms the strong baseline of continue training on multi-domain (medical, tech and religion) data by 1.47 BLEU points. Also continue training DoSS on new domain (legal) outperforms the multi-domain (medical, tech, religion, legal) baseline by 1.52 BLEU points.
Fast Vocabulary Projection Method via Clustering for Multilingual Machine Translation on GPU
Aug 14, 2022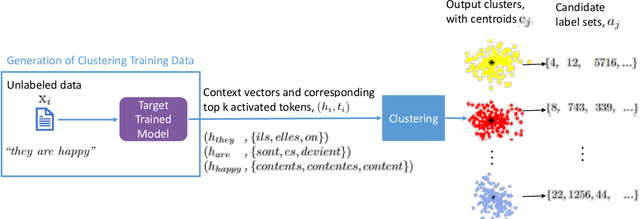
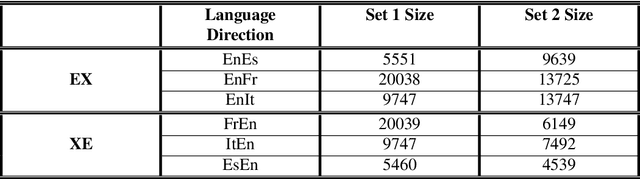
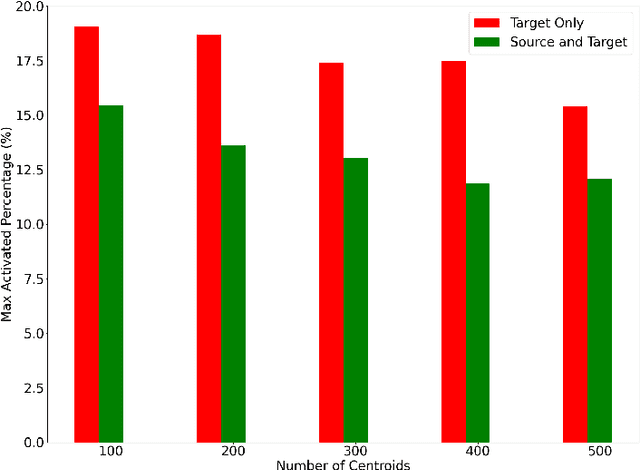
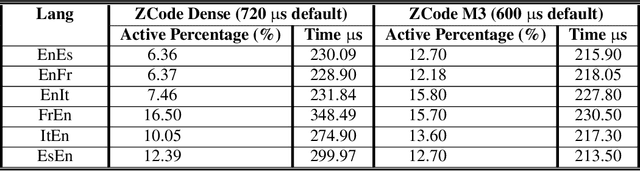
Multilingual Neural Machine Translation has been showing great success using transformer models. Deploying these models is challenging because they usually require large vocabulary (vocab) sizes for various languages. This limits the speed of predicting the output tokens in the last vocab projection layer. To alleviate these challenges, this paper proposes a fast vocabulary projection method via clustering which can be used for multilingual transformers on GPUs. First, we offline split the vocab search space into disjoint clusters given the hidden context vector of the decoder output, which results in much smaller vocab columns for vocab projection. Second, at inference time, the proposed method predicts the clusters and candidate active tokens for hidden context vectors at the vocab projection. This paper also includes analysis of different ways of building these clusters in multilingual settings. Our results show end-to-end speed gains in float16 GPU inference up to 25% while maintaining the BLEU score and slightly increasing memory cost. The proposed method speeds up the vocab projection step itself by up to 2.6x. We also conduct an extensive human evaluation to verify the proposed method preserves the quality of the translations from the original model.
Language Tokens: A Frustratingly Simple Approach Improves Zero-Shot Performance of Multilingual Translation
Aug 11, 2022
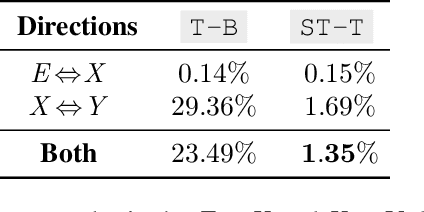
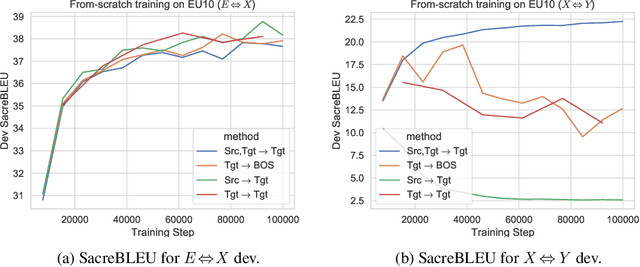
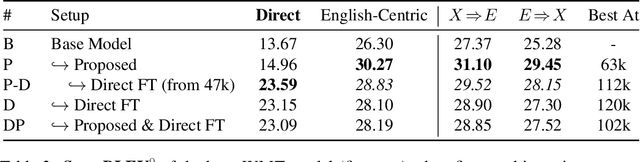
This paper proposes a simple yet effective method to improve direct (X-to-Y) translation for both cases: zero-shot and when direct data is available. We modify the input tokens at both the encoder and decoder to include signals for the source and target languages. We show a performance gain when training from scratch, or finetuning a pretrained model with the proposed setup. In the experiments, our method shows nearly 10.0 BLEU points gain on in-house datasets depending on the checkpoint selection criteria. In a WMT evaluation campaign, From-English performance improves by 4.17 and 2.87 BLEU points, in the zero-shot setting, and when direct data is available for training, respectively. While X-to-Y improves by 1.29 BLEU over the zero-shot baseline, and 0.44 over the many-to-many baseline. In the low-resource setting, we see a 1.5~1.7 point improvement when finetuning on X-to-Y domain data.
Ensembling of Distilled Models from Multi-task Teachers for Constrained Resource Language Pairs
Nov 26, 2021
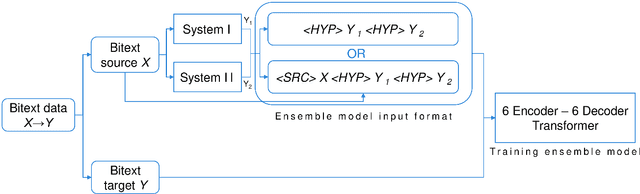
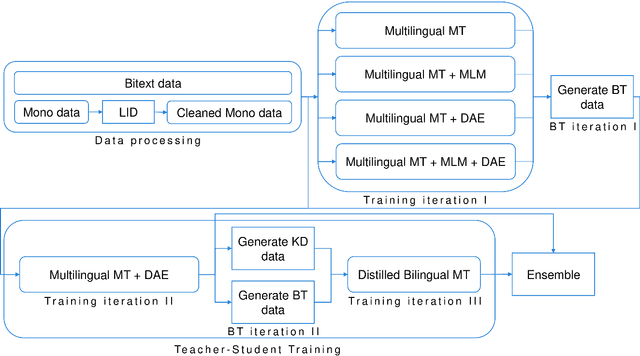
This paper describes our submission to the constrained track of WMT21 shared news translation task. We focus on the three relatively low resource language pairs Bengali to and from Hindi, English to and from Hausa, and Xhosa to and from Zulu. To overcome the limitation of relatively low parallel data we train a multilingual model using a multitask objective employing both parallel and monolingual data. In addition, we augment the data using back translation. We also train a bilingual model incorporating back translation and knowledge distillation then combine the two models using sequence-to-sequence mapping. We see around 70% relative gain in BLEU point for English to and from Hausa, and around 25% relative improvements for both Bengali to and from Hindi, and Xhosa to and from Zulu compared to bilingual baselines.
Score Combination for Improved Parallel Corpus Filtering for Low Resource Conditions
Nov 16, 2020
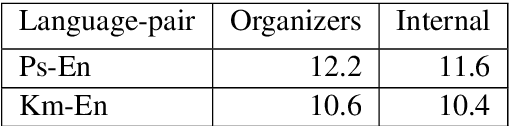
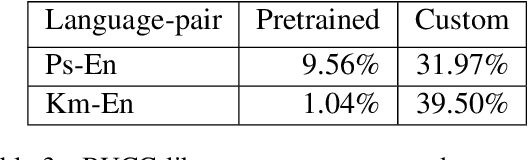

This paper describes our submission to the WMT20 sentence filtering task. We combine scores from (1) a custom LASER built for each source language, (2) a classifier built to distinguish positive and negative pairs by semantic alignment, and (3) the original scores included in the task devkit. For the mBART finetuning setup, provided by the organizers, our method shows 7% and 5% relative improvement over baseline, in sacreBLEU score on the test set for Pashto and Khmer respectively.
Text-Independent Speaker Verification Based on Deep Neural Networks and Segmental Dynamic Time Warping
Jun 26, 2018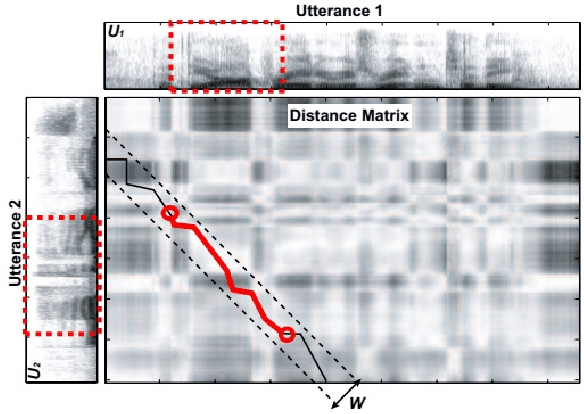

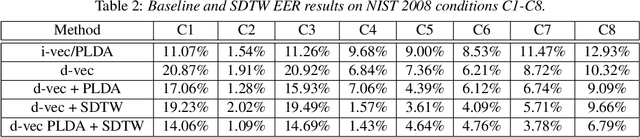
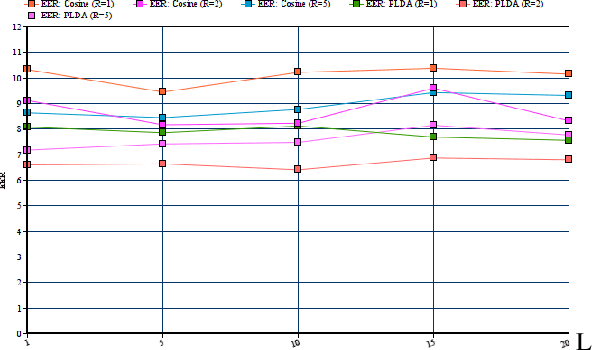
In this paper we present a new method for text-independent speaker verification that combines segmental dynamic time warping (SDTW) and the d-vector approach. The d-vectors, generated from a feed forward deep neural network trained to distinguish between speakers, are used as features to perform alignment and hence calculate the overall distance between the enrolment and test utterances.We present results on the NIST 2008 data set for speaker verification where the proposed method outperforms the conventional i-vector baseline with PLDA scores and outperforms d-vector approach with local distances based on cosine and PLDA scores. Also score combination with the i-vector/PLDA baseline leads to significant gains over both methods.