 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Intent-Based Filtering for Multi-Party Conversations Using Knowledge Distillation from LLMs
Mar 21, 2025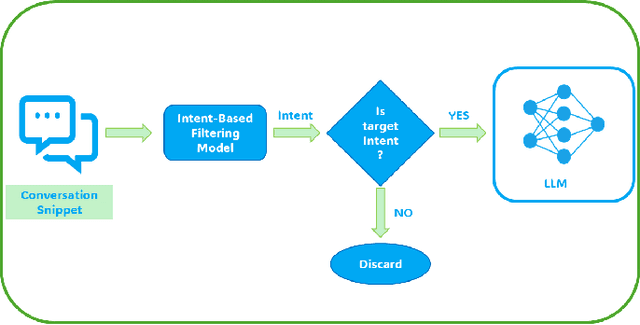
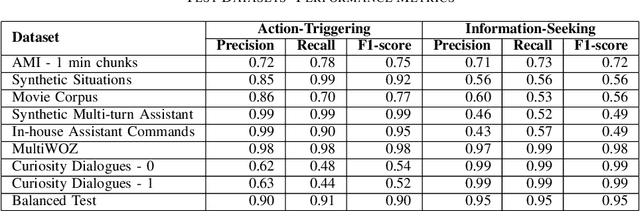
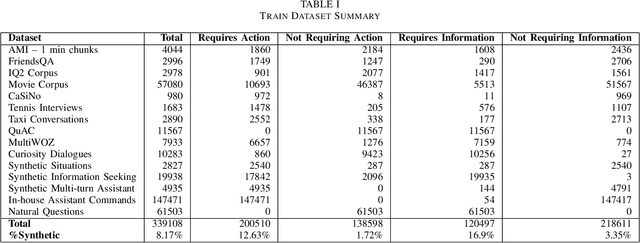

Large language models (LLMs) have showcased remarkable capabilities in conversational AI, enabling open-domain responses in chat-bots, as well as advanced processing of conversations like summarization, intent classification, and insights generation. However, these models are resource-intensive, demanding substantial memory and computational power. To address this, we propose a cost-effective solution that filters conversational snippets of interest for LLM processing, tailored to the target downstream application, rather than processing every snippet. In this work, we introduce an innovative approach that leverages knowledge distillation from LLMs to develop an intent-based filter for multi-party conversations, optimized for compute power constrained environments. Our method combines different strategies to create a diverse multi-party conversational dataset, that is annotated with the target intents and is then used to fine-tune the MobileBERT model for multi-label intent classification. This model achieves a balance between efficiency and performance, effectively filtering conversation snippets based on their intents. By passing only the relevant snippets to the LLM for further processing, our approach significantly reduces overall operational costs depending on the intents and the data distribution as demonstrated in our experiments.
Domain Specific Sub-network for Multi-Domain Neural Machine Translation
Oct 18, 2022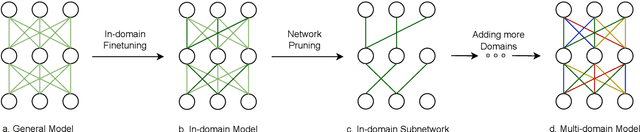
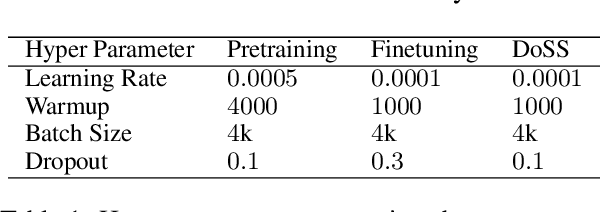
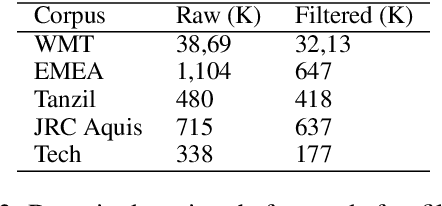
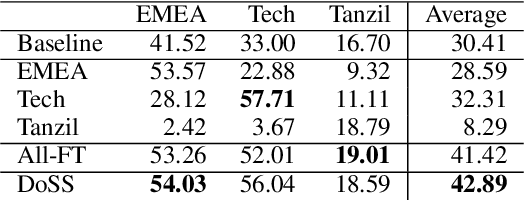
This paper presents Domain-Specific Sub-network (DoSS). It uses a set of masks obtained through pruning to define a sub-network for each domain and finetunes the sub-network parameters on domain data. This performs very closely and drastically reduces the number of parameters compared to finetuning the whole network on each domain. Also a method to make masks unique per domain is proposed and shown to greatly improve the generalization to unseen domains. In our experiments on German to English machine translation the proposed method outperforms the strong baseline of continue training on multi-domain (medical, tech and religion) data by 1.47 BLEU points. Also continue training DoSS on new domain (legal) outperforms the multi-domain (medical, tech, religion, legal) baseline by 1.52 BLEU points.
Ensembling of Distilled Models from Multi-task Teachers for Constrained Resource Language Pairs
Nov 26, 2021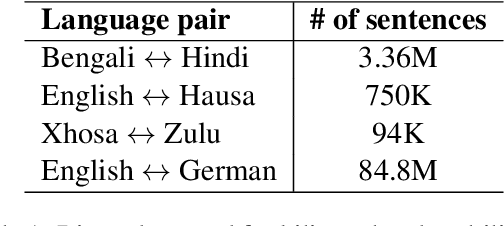
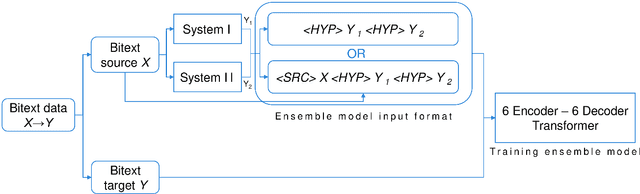
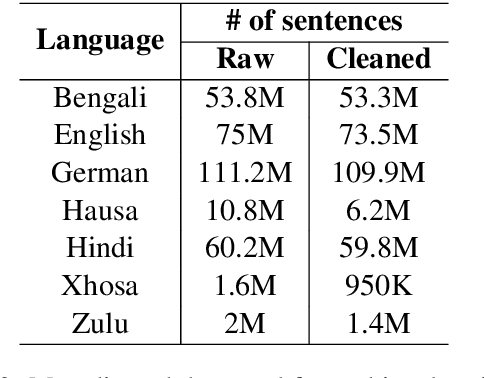
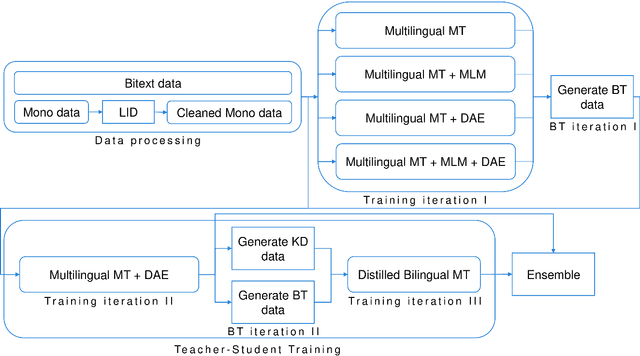
This paper describes our submission to the constrained track of WMT21 shared news translation task. We focus on the three relatively low resource language pairs Bengali to and from Hindi, English to and from Hausa, and Xhosa to and from Zulu. To overcome the limitation of relatively low parallel data we train a multilingual model using a multitask objective employing both parallel and monolingual data. In addition, we augment the data using back translation. We also train a bilingual model incorporating back translation and knowledge distillation then combine the two models using sequence-to-sequence mapping. We see around 70% relative gain in BLEU point for English to and from Hausa, and around 25% relative improvements for both Bengali to and from Hindi, and Xhosa to and from Zulu compared to bilingual baselines.
Score Combination for Improved Parallel Corpus Filtering for Low Resource Conditions
Nov 16, 2020
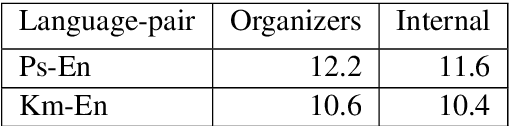
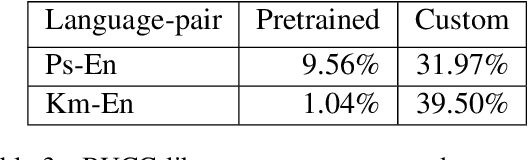

This paper describes our submission to the WMT20 sentence filtering task. We combine scores from (1) a custom LASER built for each source language, (2) a classifier built to distinguish positive and negative pairs by semantic alignment, and (3) the original scores included in the task devkit. For the mBART finetuning setup, provided by the organizers, our method shows 7% and 5% relative improvement over baseline, in sacreBLEU score on the test set for Pashto and Khmer respectively.